
|
Component family |
Processing |
|
|
Function |
tAggregateRow receives a flow and |
|
|
Purpose |
Helps to provide a set of metrics based on values or calculations. |
|
|
Basic settings |
Schema and Edit |
A schema is a row description, it defines the number of fields to Since version 5.6, both the Built-In mode and the Repository mode are Click Edit schema to make changes to the schema. If the
This component offers the advantage of the dynamic schema feature. This allows you to This dynamic schema feature is designed for the purpose of retrieving unknown columns |
|
|
|
Built-in: The schema will be |
|
|
|
Repository: The schema already |
|
|
Group by |
Define the aggregation sets, the values of which will be used for |
|
|
|
Output Column: Select the column Ex: Select Country to calculate an average of values for each |
|
|
|
Input Column: Match the input |
|
|
Operations |
Select the type of operation along with the value to use for the |
|
|
|
Output Column: Select the |
|
|
|
Function: Select the operator |
|
|
|
Input column: Select the input |
|
|
|
Ignore null values: Select the |
|
Advanced settings |
Delimiter(only for list operation) |
Enter the delimiter you want to use to separate the different |
|
|
Use financial precision, this is the max precision for |
Select this check box to use a financial precision. This is a max Warning
We advise you to use the BigDecimal type for the |
|
|
Check type overflow (slower) |
Checks the type of data to ensure that the Job doesn’t |
|
|
Check ULP (Unit in the Last Place), ensure that a value |
Select this check box to ensure the most precise results possible |
|
|
tStatCatcher Statistics |
Check this box to collect the log data at component level. Note that this check box is not available in |
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see Talend Studio |
|
|
Usage |
This component handles flow of data therefore it requires input |
|
|
Usage in Map/Reduce Jobs |
If you have subscribed to one of the Talend solutions with Big Data, you can also For further information about a Talend Map/Reduce Job, see the sections Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
|
Usage in Storm Jobs |
If you have subscribed to one of the Talend solutions with Big Data, you can also The Storm version does not support the use of the global variables. You need to use the Storm Configuration tab in the This connection is effective on a per-Job basis. For further information about a Talend Storm Job, see the sections Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
|
Log4j |
The activity of this component can be logged using the log4j feature. For more information on this feature, see Talend Studio User For more information on the log4j logging levels, see the Apache documentation at http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html. |
|
|
Limitation |
n/a |
|
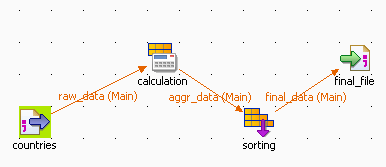
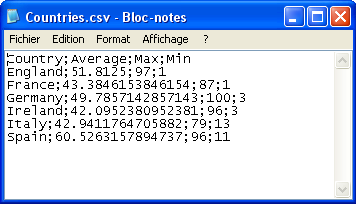
The following scenario describes a four-component Job. As input component, a CSV file
contains countries and notation values to be sorted by best average value. This
component is connected to a tAggregateRow operator, in
charge of the average calculation then to a tSortRow
component for the ascending sort. The output flow goes to the new csv file.
-
From the File folder in the Palette, drop a tFileInputDelimited component to the design workspace.
-
Click the label and rename it as Countries. Or rename it
from the View tab panel -
In the Basic settings tab panel of this
component, define the filepath and the delimitation criteria. Or select the
metadata file in the repository if it exists. -
Click Edit schema… and set the columns:
Countries and Points to match the
file structure. If your file description is stored in the Metadata area
of the Repository, the schema is automatically uploaded when you click
Repository in Schema type field. -
Then from the Processing folder in the
Palette, drop a tAggregateRow component to the design workspace. Rename it as
Calculation. -
Connect Countries to Calculation via
a right-click and select Row > Main. -
Double-click Calculation (tAggregateRow component) to set the properties. Click Edit schema and define the output schema. You can add
as many columns as you need to hold the set operations results in the output
flow.
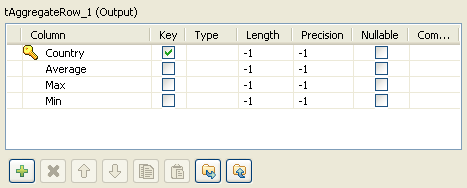
-
In this example, we’ll calculate the average notation value per country and we
will display the max and the min notation for each country, given that each
country holds several notations. Click OK when
the schema is complete. -
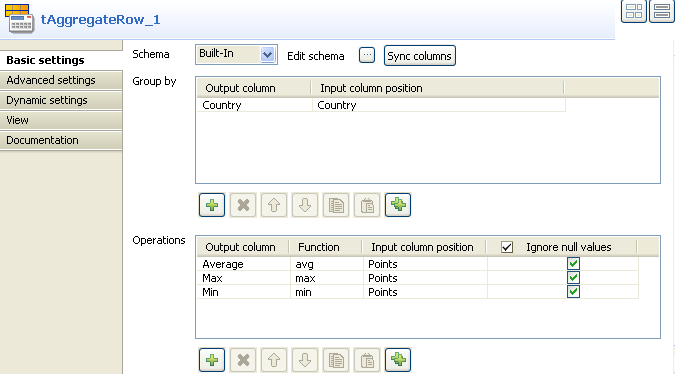
To carry out the various set operations, back in the Basic settings panel, define the sets holding the operations in
the Group By area. In this example, select
Country as group by column. Note that the
output column needs to be defined a key field in the schema. The first column
mentioned as output column in the Group By
table is the main set of calculation. All other output sets will be secondary by
order of display. -
Select the input column which the values will be taken from.
-
Then fill in the various operations to be carried out. The functions are
average, min,
max for this use case. Select the input columns, where
the values are taken from and select the check boxes in the Ignore null values list as needed.
-
Drop a tSortRow component from the Palette onto the design workspace. For more
information regarding this component, see tSortRow properties. -
Connect the tAggregateRow to this new
component using a row main link. -
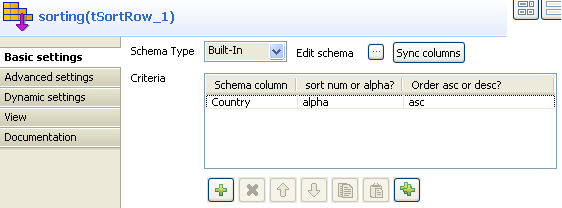
On the Component view of the tSortRow component, define the column the sorting is
based on, the sorting type and order.
-
In this case, the column to be sorted by is Country, the
sort type is alphabetical and the order is ascending. -
Drop a tFileOutputDelimited from the
Palette to the design workspace and define
it to set the output flow. -
Connect the tSortRow component to this output
component. -
In the Component view, enter the output
filepath. Edit the schema if need be. In this case the delimited file is of csv
type. And select the Include Header check box
to reuse the schema column labels in your output flow. -
Press F6 to execute the Job. The csv file
thus created contains the aggregating result.
In this scenario, a four-component Java Job uses a tAggregateRow component to read data from a CSV file, group the data,
and then send the grouping result to the Run console
and an output file. A dynamic schema is used in this Job. For more information about
dynamic schema, see Talend Studio User Guide.

-
Drop the components required for this use case: tFileInputDelimited, tAggregateRow, tLogRow and
tFileOutputDelimited from the Palette to the design workspace. -
Connect these components together using Row
> Main links. -
Double-click the tFileInputDelimited
component to display its Basic settings view.

Warning
The dynamic schema feature is only supported in Built-In mode and requires the input file to have a
header row.
-
Select Built-In from the Property Type list.
-
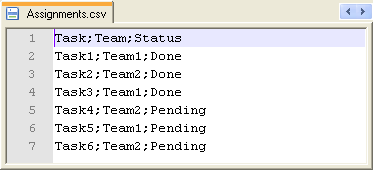
Click the […] button next to the File Name field to browse to your input file. In this
use case, we use a simple CSV file that has only three columns, as shown below:
-
Specify the header row in Header field. In
this use case the first row is the header row. -
Select Built-In from the Schema list, and click Edit
schema to set the input schema.

Warning
The dynamic column must be defined in the last row of the
schema.
-
In the schema editor, add two columns and name them Task
and Other respectively. Set the data type of the
Other column to Dynamic to retrieve all the columns undefined in the schema. -
Click OK to close the schema editor.
-
Double-click the tAggregateRow component to
display the Basic settings view.

-
Click Sync columns to reuse the input schema
for the output row. If needed, click Edit
schema and rename the columns in the output schema. In this use
case, we simply keep the schema as it is. -
Add a row in the Group by table by clicking
the plus button, and select Other in both Output column and Input column
position fields to group the data entries by the dynamic
column.
Warning
Dynamic column aggregation can be carried out only for the grouping
operation.
-
Add a row in the Operations table by clicking
the plus button, select Task in both Output column and Input column
position fields, and select list in the
Function field so that all the entries of
the Task column are listed in the grouping result. -
To view the output in the form of a table on the Run console, double-click the tLogRow component and select the Table option in the Basic
settings view. -
Double-click the tFileOutputDelimited
component to display its Basic settings
view.

-
Click the […] button next to the File Name field to browse to the directory where you
want to save the output file, and then enter a name for the file. -
Select the Include Header check box to
retrieve the column names as well as the grouped data. -
Save your Job and press F6 to run it.
As shown in the Job execution result, the data entries are grouped as per
Team and Status.
