Using the tDataprepRun component to apply a preparation
to a data sample in an Apache Spark Batch Job
This scenario applies only to a subscription-based Talend solution with Big data.
The tDataprepRun component allows you to reuse an existing
preparation made in Talend Data Preparation,
directly in a Big Data Job. In other words, you can operationalize the process of applying a
preparation to input data with the same model.
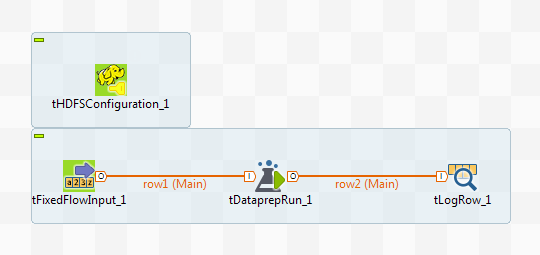
The following scenario creates a simple Job that :
- Reads a small sample of customer data,
- applies an existing preparation on this data,
- shows the result of the execution in the console.
This assumes that a preparation has been created beforehand, on a dataset with
the same schema as your input data for the Job. In this case, the existing preparation is
called datapreprun_spark. This simple preparation puts the customer last
names into upper case and applies a filter to isolate the customers from California, Texas and
Florida.

follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
James;Butt;California Daniel;Fox;Connecticut Donna;Coleman;Alabama Thomas;Webb;Illinois William;Wells;Florida Ann;Bradley;California Sean;Wagner;Florida Elizabeth;Hall;Minnesota Kenneth;Jacobs;Florida Kathleen;Crawford;Texas Antonio;Reynolds;California Pamela;Bailey;Texas Patricia;Knight;Texas Todd;Lane;New Jersey Dorothy;Patterson;Virginia |
Prerequisite: ensure that the Spark
cluster has been properly installed and is running.