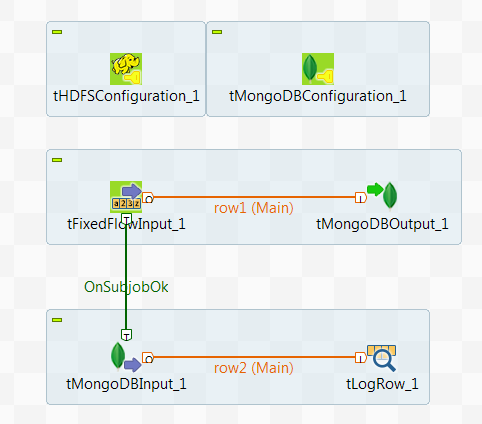
Writing and reading data from MongoDB using a Spark Batch Job
This scenario applies only to a subscription-based Talend solution with Big data.
In this scenario, you create a Spark Batch Job to write data about some movie directors
into the MongoDB default database and then read the data
from this database.
The sample data about movie directors reads as
follows:
follows:
|
1 2 3 4 5 |
1;Gregg Araki 2;P.J. Hogan 3;Alan Rudolph 4;Alex Proyas 5;Alex Sichel |
This data contains the names of these directors and the ID numbers distributed to
them.
Note that the sample data is created for demonstration purposes only.
Prerequisite: ensure that the Spark cluster and the
MongoDB database to be used have been properly installed and are running.
To replicate this scenario, proceed as follows:
Document get from Talend https://help.talend.com
Thank you for watching.
Subscribe
Login
0 Comments