tFileInputMSPositional
sends the fields as defined in the different schemas to the next components using Row
connections.
tFileInputMSPositional Standard properties
These properties are used to configure tFileInputMSPositional running in the Standard Job framework.
The Standard
tFileInputMSPositional component belongs to the File family.
The component in this framework is available in all Talend
products.
Basic settings
|
Property type |
Either Built-in or Repository. |
|
|
Built-in: No property data stored |
|
|
Repository: Select the repository |
|
File name/Stream |
Name of the file and/or the variable to be processed For further information about how to define and use a variable in Warning: Use absolute path (instead of relative path) for
this field to avoid possible errors. |
|
Row separator |
String (ex: ” |
|
Header Field Position |
Start-end position of the schema identifier. |
|
Records |
Schema: define as many schemas as
Header value: value in the row
Pattern: string which represents
Reject incorrect row size: select
Parent row: Select the parent row
Parent key column: Type in the
Key column: Type in the key |
|
Skip from header |
Number of rows to be skipped in the beginning of file. |
|
Skip from footer |
Number of rows to be skipped at the end of the file. |
|
Limit |
Maximum number of rows to be processed. If Limit = 0, no row is |
|
Die on parse error |
Let the component die if an parsing error occurs. |
|
Die on unknown header type |
Length values separated by commas, interpreted as a string between |
Advanced settings
|
Process long rows (needed for processing rows longer than |
Select this check box to process long rows (this is necessary to |
|
Advanced separator (for numbers) |
Select this check box to modify the separators used for
Thousands separator: define
Decimal separator: define |
|
Trim all column |
Select this check box to remove leading and trailing whitespaces |
|
Validate date |
Select this check box to check the date format strictly against |
|
Encoding |
Select the encoding type from the list or select Custom and define it manually. This field |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
NB_LINE_REJECTED: the number of rows rejected. This is a
NB_LINE_UNKOWN_HEADER_TYPES: the number of rows with
NB_LINE_PARSE_ERRORS: the number of rows with parse
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to read a multi schemas positional file and |
Reading data from a positional file
The positional file is shown
below:
|
1 2 3 4 5 6 |
schema_1 (car_owner):schema_id;car_make;owner;age schema_2 (car-insurance):schema_id;car_owner;age;car_insurance 1bmw John 45 1bench Mike 30 2John 45 yes 2Mike 50 No |
Dropping the components
-
Drop one tFileInputMSPositional and two
tLogRow from the Palette to the design workspace. -
Rename the two tLogRow components as
car_owner and car_insurance.
Configuring the components
-
Double-click the tFileInputMSPositional
component to show its Basic settings view
and define its properties.
-
In the File name/Stream field, type in
the path to the input file. Also, you can click the […] button to browse and choose the file. -
In the Header Field Position field, enter
the start-end position for the schema identifier in the input file,
0-1 in this case as the first
character in each row is the schema identifier. -
Click the [+] button twice to added two
rows in the Records table. -
Click the cell under the Schema column to
show the […] button.Click the […] button to show the schema
naming box.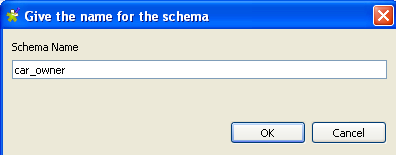
-
Enter the schema name and click OK.
The schema name appears in the cell and the schema editor opens.
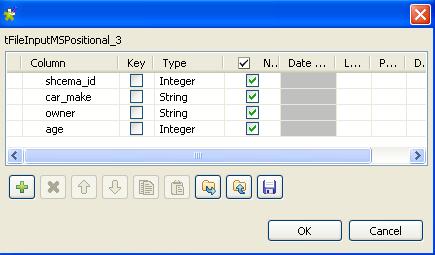
-
Define the schema car_owner, which has
four columns: schema_id, car_make, owner and age. -
Repeat the steps to define the schema car_insurance, which has four columns: schema_id, car_owner, age and
car_insurance.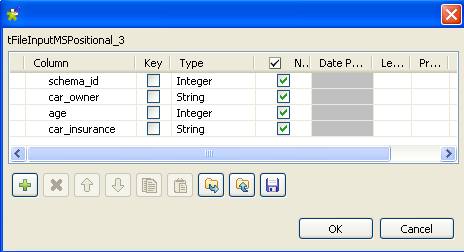
-
Connect tFileInputMSPositional to the
car_owner component with the Row > car_owner
link, and the car_insurance component with
the Row > car_insurance link. -
In the Header value column, type in the
schema identifier value for the schema, 1
for the schema car_owner and 2 for the schema car_insurance in this case. -
In the Pattern column, type in the length of each field
in the schema, the number of characters, number, etc in each field,
1,8,10,3 for the schema car_owner and 1,10,3,3 for the schema car_insurance in this case. -
In the Skip from header field, type in
the number of beginning rows to skip, 2
in this case as the two rows in the beginning just describes the two
schemas, instead of the values. -
Choose Table (print values in cells of a
table) in the Mode area of
the components car_owner and car_insurance.
Executing the Job
- Press Ctrl+S to save the Job.
-
Press F6 or click Run on the Run tab to
execute the Job. The file is read row by row based on the length values defined in the
The file is read row by row based on the length values defined in the
Pattern field and output in two tables
with different schemas.