tKafkaInput
Transmits messages you need to process to the components that follow in the Job you
are designing.
tKafkaInput is a generic message broker that
transmits messages to the Job that runs transformations over these messages.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tKafkaInput Standard properties.
The component in this framework is available in all Talend products with Big Data
and in Talend Data Fabric. -
Spark Streaming:
see tKafkaInput properties for Apache Spark Streaming.This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
-
Storm: see tKafkaInput Storm properties (deprecated).
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tKafkaInput Standard properties
These properties are used to configure tKafkaInput running in the Standard Job framework.
The Standard
tKafkaInput component belongs to the Internet family.
The component in this framework is available in all Talend products with Big Data
and in Talend Data Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields Note that the schema of this component is read-only. It stores the |
|
Output type |
Select the type of the data to be sent to the next component. Typically, using String is recommended, because tKafkaInput can automatically translate the Kafka byte[] messages |
|
Use an existing connection |
Select this check box and in the Component List click the relevant connection component to |
|
Version |
Select the version of the Kafka cluster to be used. |
|
Zookeeper quorum list |
Enter the address of the Zookeeper service of the Kafka cluster to be used. The form of this address should be hostname:port. This If you need to specify several addresses, separate them using a comma (,). This field is available to Kafka 0.8.2.0 only. |
|
Broker list |
Enter the addresses of the broker nodes of the Kafka cluster to be used. The form of this address should be hostname:port. This If you need to specify several addresses, separate them using a comma (,). This field is available since Kafka 0.9.0.1. |
|
Reset offsets on consumer |
Select this check box to clear the offsets saved for the consumer group to be used so that |
|
New consumer group starts from |
Select the starting point from which the messages of a topic are consumed. In Kafka, the increasing ID number of a message is called offset. When a new consumer group starts, from this list, you can select Note that the consumer group takes into account only the offset-committed messages to Each consumer group has its own counter to remember the position of a message it has
|
| Offset storage |
Select the system to which you want to commit the offsets of the consumed messages. |
| Enable dual commit |
If you select Kafka as the offset storage system, the |
|
Auto-commit offsets |
Select this check box to make tKafkaInput automatically Note that the offsets are committed only at the end of each interval. If your Job stops in |
| Topic name |
Enter the name of the topic from which tKafkaInput |
|
Consumer group ID |
Enter the name of the consumer group to which you want the current consumer (the tKafkaInput component) to belong. This consumer group will be created at runtime if it does not exist at that moment. |
|
Stop after a maximum total duration |
Select this check box and in the pop-up field, enter the duration (in milliseconds) at the |
|
Stop after receiving a maximum number of |
Select this check box and in the pop-up field, enter the maximum number of messages you |
|
Stop after maximum time waiting between |
Select this check box and in the pop-up field, enter the waiting time (in milliseconds) by |
|
Use SSL/TLS |
Select this check box to enable the SSL or TLS encrypted connection. Then you need to use the tSetKeystore This check box is available since Kafka 0.9.0.1. |
|
Use Kerberos authentication |
If the Kafka cluster to be used is secured with Kerberos, select this
For further information about how a Kafka cluster is secured with This check box is available since Kafka 0.9.0.1. |
Advanced settings
|
Kafka properties |
Add the Kafka consumer properties you need to customize to this table. For example, you For further information about the consumer properties you can define in this table, see |
|
Timeout precision(ms) |
Enter the time duration in millisecond at the end of which you want a timeout exception to The value -1 indicates that no timeout is set. |
|
Load the offset with the |
Select this check box to output the offsets of the consumed messages to the next |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. |
|
tStatCatcher Statistics |
Select this check box to gather the processing metadata at the Job |
Usage
|
Usage rule |
This component is used as a start component and requires an output |
Related scenarios
No scenario is available for the Standard version of this component yet.
tKafkaInput properties for Apache Spark Streaming
These properties are used to configure tKafkaInput running in the Spark Streaming Job framework.
The Spark Streaming
tKafkaInput component belongs to the Messaging family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields Note that the schema of this component is read-only. It stores the |
|
Output type |
Select the type of the data to be sent to the next component. Typically, using String is recommended, because tKafkaInput can automatically translate the Kafka byte[] messages |
|
Broker list |
Enter the addresses of the broker nodes of the Kafka cluster to be used. The form of this address should be hostname:port. This If you need to specify several addresses, separate them using a comma (,). |
|
Starting offset |
Select the starting point from which the messages of a topic are consumed. In Kafka, the sequential ID number of a message is called offset. From this list, you can select From Note that in order to enable the component to remember the position of a consumed message, Each consumer group has its own counter to remember the position of a message it has
|
| Topic name |
Enter the name of the topic from which tKafkaInput |
|
Group ID |
Enter the name of the consumer group to which you want the current consumer (the tKafkaInput component) to belong. This consumer group will be created at runtime if it does not exist at that moment. This property is available only when you are using Spark 2.0 or the Hadoop distribution to |
|
Set number of records per second to read from |
Enter this number within double quotation marks to limit the size of each batch to be sent For example, if you put 100 and the batch value you If you leave this check box clear, the component tries to read all the available messages |
|
Use SSL/TLS |
Select this check box to enable the SSL or TLS encrypted connection. Then you need to use the tSetKeystore This property is available only when you are using Spark 2.0 or the Hadoop distribution to The TrustStore file and any used KeyStore file must be stored locally on |
|
Use Kerberos authentication |
If the Kafka cluster to be used is secured with Kerberos, select this
For further information about how a Kafka cluster is secured with This check box is available since Kafka 0.9.0.1. |
Advanced settings
|
Kafka properties |
Add the Kafka consumer properties you need to customize to this table. For example, you For further information about the consumer properties you can define in this table, see |
|
Encoding |
Select the encoding from the list or select Custom and define it manually. This encoding is used by tKafkaInput to decode the input messages. |
Usage
|
Usage rule |
This component is used as a start component and requires an output link. This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents In the implementation of the current component in Spark, the Kafka offsets are |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Analyzing a Twitter flow in near real-time
This scenario applies only to Talend Real Time Big Data Platform and Talend Data Fabric.
In this scenario, you create a Spark Streaming Job to analyze, at the end of
each 15-second interval, which hashtags are most used by Twitter users when they mention Paris
in their Tweets over the previous 20 seconds.
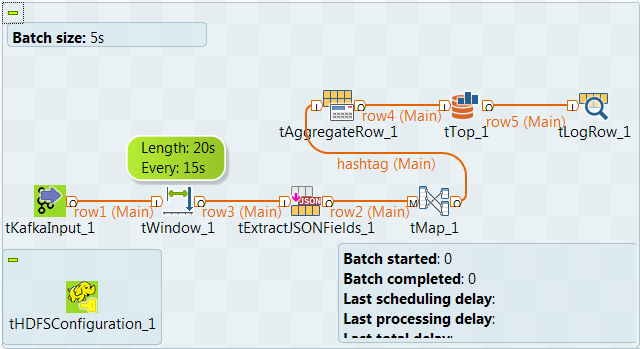
An open source third-party program is used to receive and write Twitter
streams in a given Kafka topic, twitter_live for example, and the Job
you design in this scenario is used to consume the Tweets from this topic.
A row of Twitter raw data with hashtags reads like the example presented at
https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags.
Before replicating this scenario, you need to ensure that your Kafka system is
up and running and you have proper rights and permissions to access the Kafka topic to be
used. You also need a Twitter-streaming program to transfer Twitter streams into Kafka in near
real-time.
Talend
does not provide this kind of program but some free programs created for this purpose are
available in some online communities such as Github.
tHDFSConfiguration is used in this scenario by Spark to connect
to the HDFS system where the jar files dependent on the Job are transferred.
Configuration tab in the Run
view, define the connection to a given Spark cluster for the whole Job. In
addition, since the Job expects its dependent jar files for execution, you must
specify the directory in the file system to which these jar files are
transferred so that Spark can access these files:
-
Yarn mode (Yarn client or Yarn cluster):
-
When using Google Dataproc, specify a bucket in the
Google Storage staging bucket
field in the Spark configuration
tab. -
When using HDInsight, specify the blob to be used for Job
deployment in the Windows Azure Storage
configuration area in the Spark
configuration tab. - When using Altus, specify the S3 bucket or the Azure
Data Lake Storage for Job deployment in the Spark
configuration tab. - When using Qubole, add a
tS3Configuration to your Job to write
your actual business data in the S3 system with Qubole. Without
tS3Configuration, this business data is
written in the Qubole HDFS system and destroyed once you shut
down your cluster. -
When using on-premise
distributions, use the configuration component corresponding
to the file system your cluster is using. Typically, this
system is HDFS and so use tHDFSConfiguration.
-
-
Standalone mode: use the
configuration component corresponding to the file system your cluster is
using, such as tHDFSConfiguration or
tS3Configuration.If you are using Databricks without any configuration component present
in your Job, your business data is written directly in DBFS (Databricks
Filesystem).
To replicate this scenario, proceed as follows:
Linking the components
-
In the
Integration
perspective of the Studio, create an empty
Spark Streaming Job from the Job Designs node
in the Repository tree view.For further information about how to create a Spark Streaming Job, see
Talend Open Studio for Big Data Getting Started Guide
. -
In the workspace, enter the name of the component to be used and select this
component from the list that appears. In this scenario, the components are
tHDFSConfiguration, tKafkaInput, tWindow, tExtractJSONFields, tMap, tAggregateRow, tTop and tLogRow. -
Connect tKafkaInput, tWindow, tExtractJSONFields and
tMap using the Row >
Main link. -
Connect tMap to tAggregateRow using the Row > Main
link and name this connection in the dialog box that is displayed. For example,
name it to hashtag. -
Connect tAggregateRow, tTop and tLogRow using the
Row > Main link. -
Leave the tHDFSConfiguration component alone
without any connection.
Selecting the Spark mode
Depending on the Spark cluster to be used, select a Spark mode for your Job.
The Spark documentation provides an exhaustive list of Spark properties and
their default values at Spark Configuration. A Spark Job designed in the Studio uses
this default configuration except for the properties you explicitly defined in the
Spark Configuration tab or the components
used in your Job.
-
Click Run to open its view and then click the
Spark Configuration tab to display its view
for configuring the Spark connection. -
Select the Use local mode check box to test your Job locally.
In the local mode, the Studio builds the Spark environment in itself on the fly in order to
run the Job in. Each processor of the local machine is used as a Spark
worker to perform the computations.In this mode, your local file system is used; therefore, deactivate the
configuration components such as tS3Configuration or
tHDFSConfiguration that provides connection
information to a remote file system, if you have placed these components
in your Job.You can launch
your Job without any further configuration. -
Clear the Use local mode check box to display the
list of the available Hadoop distributions and from this list, select
the distribution corresponding to your Spark cluster to be used.This distribution could be:-
For this distribution, Talend supports:
-
Yarn client
-
Yarn cluster
-
-
For this distribution, Talend supports:
-
Standalone
-
Yarn client
-
Yarn cluster
-
-
For this distribution, Talend supports:
-
Yarn client
-
-
For this distribution, Talend supports:
-
Yarn client
-
Yarn cluster
-
-
For this distribution, Talend supports:
-
Standalone
-
Yarn client
-
Yarn cluster
-
-
For this distribution, Talend supports:
-
Yarn cluster
-
-
Cloudera Altus
For this distribution, Talend supports:-
Yarn cluster
Your Altus cluster should run on the following Cloud
providers:-
Azure
The support for Altus on Azure is a technical
preview feature. -
AWS
-
-
As a Job relies on Avro to move data among its components, it is recommended to set your
cluster to use Kryo to handle the Avro types. This not only helps avoid
this Avro known issue but also
brings inherent preformance gains. The Spark property to be set in your
cluster is:
1spark.serializer org.apache.spark.serializer.KryoSerializerIf you cannot find the distribution corresponding to yours from this
drop-down list, this means the distribution you want to connect to is not officially
supported by
Talend
. In this situation, you can select Custom, then select the Spark
version of the cluster to be connected and click the
[+] button to display the dialog box in which you can
alternatively:-
Select Import from existing
version to import an officially supported distribution as base
and then add other required jar files which the base distribution does not
provide. -
Select Import from zip to
import the configuration zip for the custom distribution to be used. This zip
file should contain the libraries of the different Hadoop/Spark elements and the
index file of these libraries.In
Talend
Exchange, members of
Talend
community have shared some ready-for-use configuration zip files
which you can download from this Hadoop configuration
list and directly use them in your connection accordingly. However, because of
the ongoing evolution of the different Hadoop-related projects, you might not be
able to find the configuration zip corresponding to your distribution from this
list; then it is recommended to use the Import from
existing version option to take an existing distribution as base
to add the jars required by your distribution.Note that custom versions are not officially supported by
Talend
.
Talend
and its community provide you with the opportunity to connect to
custom versions from the Studio but cannot guarantee that the configuration of
whichever version you choose will be easy. As such, you should only attempt to
set up such a connection if you have sufficient Hadoop and Spark experience to
handle any issues on your own.
For a step-by-step example about how to connect to a custom
distribution and share this connection, see Hortonworks.
Configuring a Spark stream for your Apache Spark streaming Job
-
In the Batch size
field, enter the time interval at the end of which the Job reviews the source
data to identify changes and processes the new micro batches. -
If needs be, select the Define a streaming
timeout check box and in the field that is displayed, enter the
time frame at the end of which the streaming Job automatically stops
running.
Configuring the connection to the file system to be used by Spark
Skip this section if you are using Google Dataproc or HDInsight, as for these two
distributions, this connection is configured in the Spark
configuration tab.
-
Double-click tHDFSConfiguration to open its Component view.
Spark uses this component to connect to the HDFS system to which the jar
files dependent on the Job are transferred. -
If you have defined the HDFS connection metadata under the Hadoop
cluster node in Repository, select
Repository from the Property
type drop-down list and then click the
[…] button to select the HDFS connection you have
defined from the Repository content wizard.For further information about setting up a reusable
HDFS connection, search for centralizing HDFS metadata on Talend Help Center
(https://help.talend.com).If you complete this step, you can skip the following steps about configuring
tHDFSConfiguration because all the required fields
should have been filled automatically. -
In the Version area, select
the Hadoop distribution you need to connect to and its version. -
In the NameNode URI field,
enter the location of the machine hosting the NameNode service of the cluster.
If you are using WebHDFS, the location should be
webhdfs://masternode:portnumber; WebHDFS with SSL is not
supported yet. -
In the Username field, enter
the authentication information used to connect to the HDFS system to be used.
Note that the user name must be the same as you have put in the Spark configuration tab.
Reading messages from a given Kafka topic
-
Double-click tKafkaInput to open its
Component view.
-
In the Broker list field, enter the locations
of the brokers of the Kafka cluster to be used, separating these locations using
comma (,). In this example, only one broker
exists and its location is localhost:9092. -
From the Starting offset drop-down list,
select the starting point from which the messages of a topic are consumed. In
this scenario, select From latest, meaning to
start from the latest message that has been consumed by the same consumer group
and of which the offset has been committed. -
In the Topic name field, enter the name of
the topic from which this Job consumes Twitter streams. In this scenario, the
topic is twitter_live.This topic must exist in your Kafka system. For further information about how
to create a Kafka topic, see the documentation from Apache Kafka or use the
tKafkaCreateTopic component provided with the
Studio. But note that tKafkaCreateTopic is not
available to the Spark Jobs. -
Select the Set number of records per second to read from
each Kafka partition check box. This limits the size of each micro
batch to be sent for processing.
Configuring how frequent the Tweets are analyzed
-
Double-click tWindow to open its
Component view. This component is used to apply a Spark window on the input RDD so that this Job always
This component is used to apply a Spark window on the input RDD so that this Job always
analyzes the Tweets of the last 20 seconds at the end of each 15 seconds. This
creates, between every two window applications, the overlap of one micro batch,
counting 5 seconds as defined in the Batch size
field in the Spark configuration tab. -
In the Window duration field, enter 20000, meaning 20
seconds. -
Select the Define the slide duration check
box and in the field that is displayed, enter 15000, meaning 15 seconds.
The configuration of the window is then displaed above the icon of tWindow in the Job you are designing.
Extracting the hashtag field from the raw Tweet data
-
Double-click tExtractJSONFields to open its Component view.
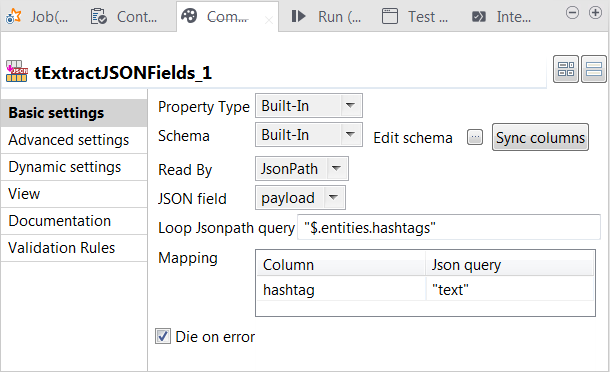 As you can read from https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags, the raw Tweet data uses the JSON format.
As you can read from https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags, the raw Tweet data uses the JSON format. -
Click Sync columns to retrieve the schema
from its preceding component. This is actually the read-only schema of tKafkaInput, since tWindow does not impact the schema. -
Click the […] button next to Edit
schema to open the schema editor.
- Rename the single column of the output schema to hashtag. This column is used to carry the hashtag field extracted from the Tweet JSON data.
- Click OK to validate these changes.
- From the Read by list, select JsonPath.
-
From the JSON field list, select the column of
the input schema from which you need to extract fields. In this scenario, it is
payload. -
In the Loop Jsonpath query field, enter JSON path
pointing to the element over which extraction is looped. According to the JSON
structure of a Tweet as you can read from the documentation of Twitter, enter
$.entities.hashtags to loop over the
hashtags entity. -
In the Mapping table, in which the hashtag column of the output schema has been filled in
automatically, enter the element on which the extraction is performed. In this
example, this is the text attribute of each
hashtags entity. Therefore, enter text within double quotation marks in the Json query column.
Aligning each hashtag to lower case
-
Double-click tMap to open its
Map editor.
-
In the table representing the output flow (on the right side), enter StringHandling.DOWNCASE(row2.hashtag) in the Expression column. This automatically creates the map
between the hashtag column of the input
schema and the hashtag column of the output
schema.Note that row2 in this expression is the ID
of the input link to tMap. It can be labeled
differently in the Job you are designing. -
Click Apply to validate these changes and
click OK to close this editor.
Counting the occurrences of each hashtag
-
Double-click tAggregateRow to open its
Component view.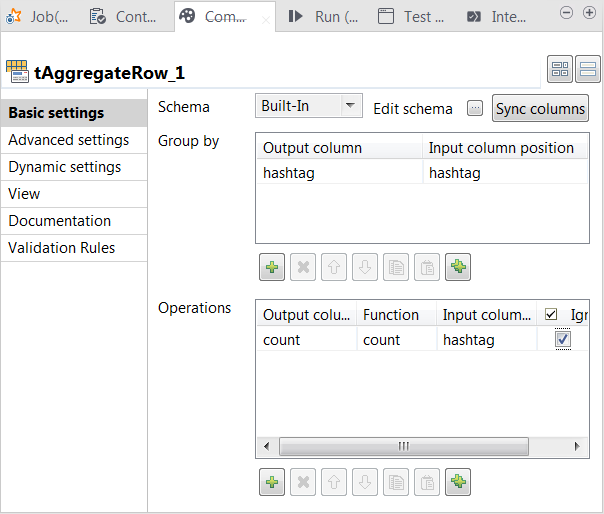
-
Click the […] button next to Edit
schema to open the schema editor.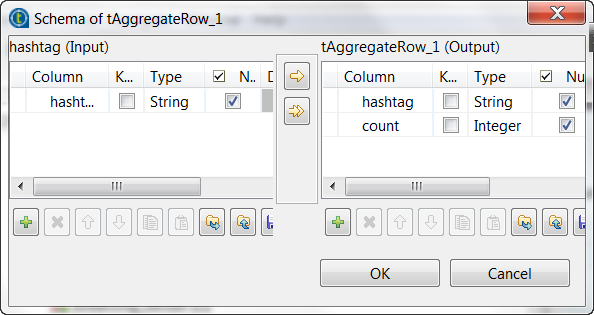
-
On the output side, click the [+] button two
times to add two rows to the output schema table and rename these new schema
columns to hashtag and count, respectively. -
Click OK to validate these changes and accept
the propagation prompted by the pop-up dialog box. -
In the Group by table, add one row by clicking
the [+] button and select hashtag for both the Output
column column and the Input column
position column. This passes data from the hashtag column of the input schema to the hashtag column of the output schema. -
In the Operations table, add one row by
clicking the [+] button. -
In the Output column column, select count, in the Function
column, select count and in the Input column position column, select hashtag.
Selecting the 5 most used hashtags in each 20 seconds
-
Double-click tTop to open its
Component view.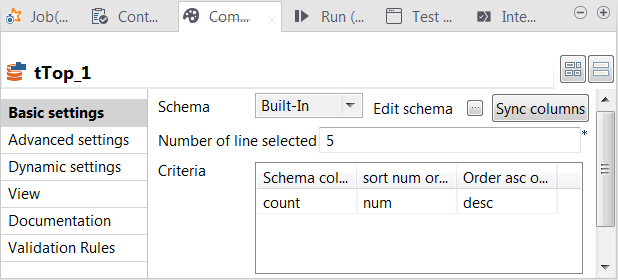
-
In the Number of line selected field, enter the
number of rows to be output to the next component, counting down from the first
row of the data sorted by tTop. In this
example, it is 5, meaning the 5 most used hashtags in each 20 seconds. -
In the Criteria table, add one row by clicking
the [+] button. -
In the Schema column column, select count, the column for which the data is sorted, in
the sort num or alpha column, select num, which means the data to be sorted are numbers,
and in the Order asc or desc column, select
desc to arrange the data in descending
order.
Executing the Job
Then you can run this Job.
The tLogRow component is used to present the execution
result of the
Job.
-
Ensure that your Twitter streaming program is still running and keep writing
the received Tweets into the given topic. -
Press F6 to run this Job.
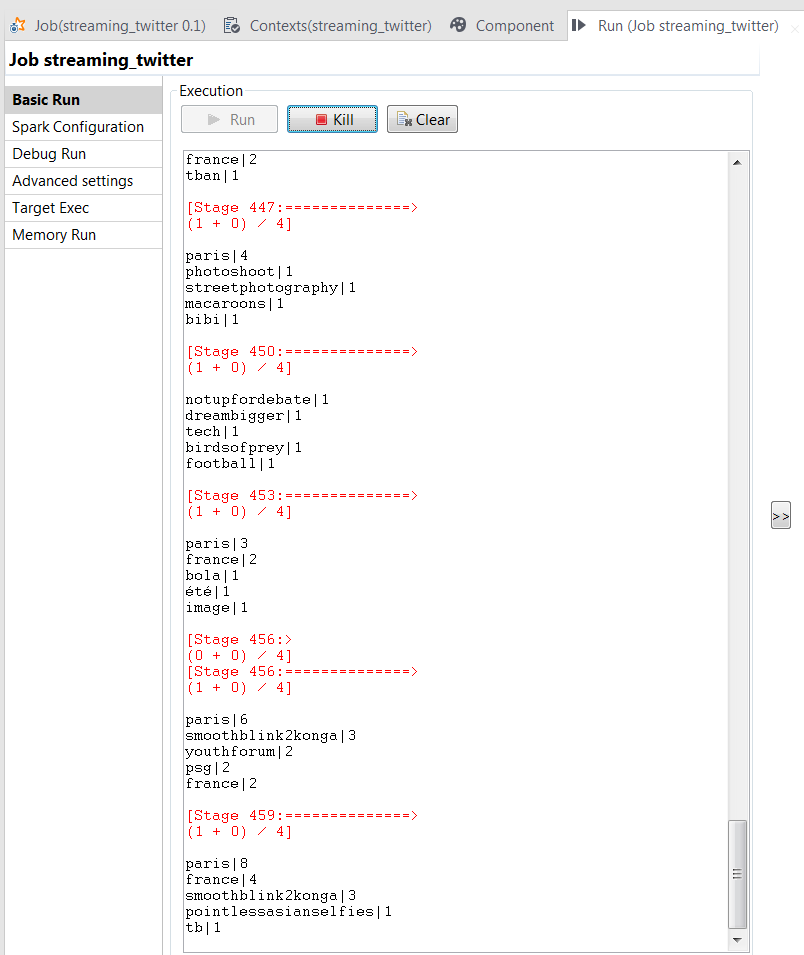
Leave the Job running a while and then in the console of the Run view, you can read the Job is listing the 5 most used hashtags in
each batch of Tweets mentioning Paris. According to the configuration of the size of
each micro batch and the Spark window, each of these Tweet batches contains the last 20
seconds’ worth of Tweets received at the end of each 15-second interval.
Note that you can manage the level of the execution information to be outputted in this
console by selecting the log4jLevel check box in the
Advanced settings tab and then selecting the level of
the information you want to display.
For more information on the log4j logging levels, see the Apache documentation at http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html.
tKafkaInput Storm properties (deprecated)
These properties are used to configure tKafkaInput running in the Storm Job framework.
The Storm
tKafkaInput component belongs to the Messaging family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
The Storm framework is deprecated from Talend 7.1 onwards. Use Talend Jobs for Apache Spark Streaming to accomplish your Streaming related tasks.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields Note that the schema of this component is read-only. It stores the |
|
Zookeeper host |
Enter the address of the Zookeeper service of the Kafka system to be used. |
|
Port |
Enter the number of the client listening port of the Zookeeper |
| Topic name | Enter the name of the topic from which tKafkaInput receives the feed of messages. |
Usage
|
Usage rule |
In a For further information about a Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Storm Connection |
You need to use the Storm Configuration tab in the This connection is effective on a per-Job basis. |
Analyzing people’s activities using a Storm topology (deprecated)
The Storm framework is deprecated from Talend 7.1 onwards. Use Talend Jobs for Apache Spark Streaming to accomplish your Streaming related tasks.
This scenario applies only to Talend Real Time Big Data Platform and Talend Data Fabric.
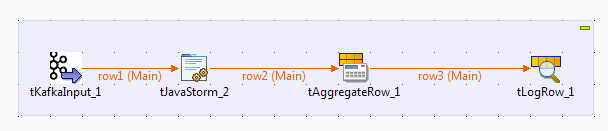
In this scenario, a four-component Storm Job (a topology) is created to transmit
messages about the activities of some given people to the topology you are designing in
order to analyze the popularities of those activities.
This Job subscribes to the related topic created by the Kafka topic producer, which means
you need to install the Kafka cluster in your messagingg system to maintain the feeds of
messages. For further information about the Kafka messaging service, see Apache’s
documentation about Kafka.
On the other hand, since this Job runs on top of Storm, you need to ensure that your Storm
system is ready for use. For further information about Storm, see Apache’s documentation
about Storm.
Note that when you use the Storm system installed in the Hortonwork Data Platform 2.1
(HDP2.1), ensure that the Storm DRPC (distributed remote procedure call) servers’ names
have been properly defined in the Custom storm.yaml section of the Config tab of Storm
in Ambari’s web console. For example, you need to use two Storm DRPC servers which are
Server1 and Server2, then you must define them in the Custom storm.yaml secton as
follows: [Server1,Server2].
To replicate this scenario, proceed as follows.
Producing the sample messages
In the real-world practice, the system that produces messages to Kafka is completely
decoupled. While in this scenario, Kafka itself is used to produce the sample
messages. You need to perform the following operations to produce these
messages:
-
Create the Kafka topic to be used to categorize the messages. The
following command is used for demonstration purposes only. If you need
further information about the creation of a Kafka topic, see Apache’s
documentation for
Kafka./usr/lib/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic activities --partitions 1 --replication-factor 1
This command creates a topic named activities, using
the Kafka brokers managed by the Zookeeper service on the localhost machine. -
Publish the message you want to analyze to the activities topic you have just created. In this scenario,
Kafka is used to perform this publication using, for example, the following
command:12345678910echo 'Ryan|M|PoolRemy|M|DrinkRemy|M|HikingIrene|F|DrinkPierre|M|MovieIrene|F|PoolThomas|M|DrinkRyan|M|CookingWang|F|CookingChen|M|Drink | /usr/lib/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic activities
This
command publishes 10 simple messages
12345678910Ryan|M|PoolRemy|M|DrinkRemy|M|HikingIrene|F|DrinkPierre|M|MovieIrene|F|PoolThomas|M|DrinkRyan|M|CookingWang|F|CookingChen|M|DrinkAs explained previously, you can use your actual message producer system instead to
perform the publication.
Linking the components
-
In the
Integration
perspective
of the Studio, create an empty Storm Job from the Job
Designs node in the Repository tree view.For further information about how to create a Storm Job, see
Talend Open Studio for Big Data Getting Started Guide
. -
In the workspace, enter the name of the component to be used and select
this component from the list that appears. In this scenario, the components
are tKafkaInput, tJavaStorm, tAggregateRow,
and tLogRow. - Connect them using Row > Main links.
Configuring the connection
-
Click Run to open its view and then click
Storm configuration to set up the
connection to the Storm system to be used.
-
In the Storm node roles
area, indicate the locations of the Nimbus server and the DRPC endpoint of the
Storm cluster to be used:Option/Fields
Description
Local mode
Select this check box to build the Storm environment within the
Studio. In this situation, the Storm Job you are designing is run
locally within the Studio and you do not need to define any specific
Nimbus and DRPC endpoint addresses.Nimbus host and
PortIn these two fields, enter the location of the Storm Nimbus server
and its port number, respectively.DRPC endpoint and
PortIn these two fields, enter the location of the Storm DRPC endpoint
and its port number, respectively. -
In the Topology name field, enter the
name you want the Storm system to use for the Storm Job, or topology in
terms of the Storm, you are designing. It is recommended to use the same
name as you have named this Storm Job so that you can easily recognize this
Job even within the Storm system. -
Select the Kill existing topology check box to make the
Storm system stop any topology that has the same name as the Job you are
designing and want to run.If you clear this check box and that Job of the same name is already running in the Storm
system, the current Job will fail when you send it to Storm to run. -
Select the Submit topology check box to submit the
current Job to the Storm system. This feature is used when you need to send
a new topology to Storm or used together with the Kill
existing topology feature when you need to update a running
topology in the Storm system.If you clear this check box, when you run the current Job, the submission
of this Job is ignored while the other configuration information is still
taken into account, for example, killing an existing topology. -
Select the Monitor topology after
submission check box to monitor the current Storm Job in the
console of the Run view.If you clear this check box, you cannot read the monitoring information in
the console. -
In the Stop monitoring after timeout
reached field, enter, without the double quotation marks, the
numeric value to indicate whether to stop the monitoring when a running
topology reaches its timeout. The default value is -1, which means no timeout is applied. -
Select the Kill topology on quitting Talend Job check
box to allow the Studio to kill, if it is still running, the current Job
from the Storm system when you stop this Job from the Studio.If you clear this check box, the topology for this Job continues to run in the Storm
system even though you kill it within the Studio or eventually shut down the
Studio. -
If you need to use any other Storm properties specific to your situation,
add them to the Storm configuration
table.
Receiving the message from the Kafka channel
-
Double-click tKafkaInput to open its
Component view.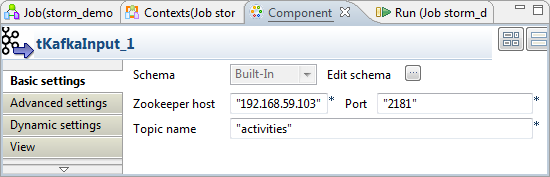
-
In the Zookeeper host field, enter the location of the
Zookeeper service used to coordinate the Kafka cluster to be used. -
In the Port field, enter the port number of this
Zookeeper service. -
In the Topic name field, enter the name of the topic in
which you need to receive messages. In this scenario, the topic is activities.
Extracting information from the message
-
Double-click tJavaStorm to open its
Component view.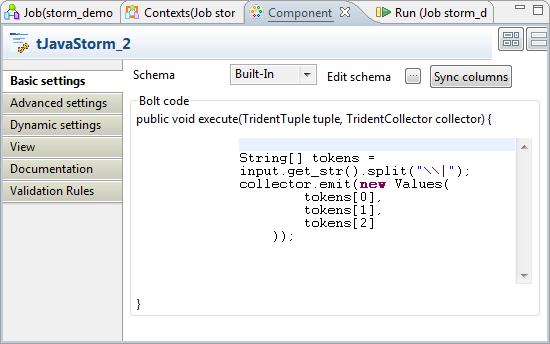
- Click the […] button next to Edit schema to open the schema editor.
-
On the output side (right), click the [+] button three
times to add three rows and in the Column
column, rename them to firstname,
gender and activity, respectively. These columns correspond to the
information you can extract from the sample message.
-
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Bolt code area, enter the main
method of the bolt to be executed. In this scenario, the code is as
follows:
String[] tokens = input.get_str().split("\|");
collector.emit(new Values(
tokens[0],
tokens[1],
tokens[2]
));
Aggregating the extracted information
-
Double-click tAggregateRow to open its
Component view. This component allows
you to find out the most popular activity recorded in the received
messages.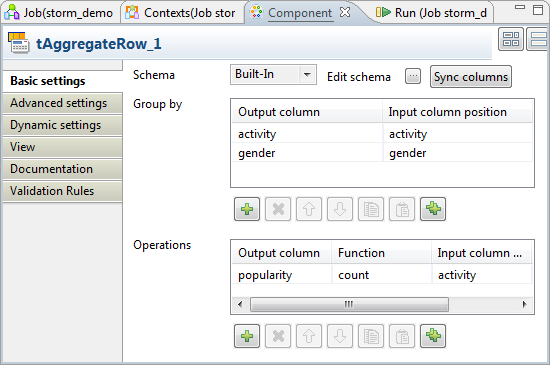
- Click the […] button next to Edit schema to open the schema editor.
-
On the output side (right), click the [+] button three times to add three rows and in the
Column column, rename them to
activity, gender and
popularity, respectively.
-
In the Type column of
the popularity row of the output side, select Double. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Group by table, add
two rows by clicking the [+] button twice
and configure these two rows as follows to group the outputted data:Column
Description
Output column
Select the columns from the output schema to be used as the
conditions to group the outputted data. In this example, they are
activity and gender.Input column position
Select the columns from the input schema to send data to the output
columns you have selected in the Output
column column. In this scenario, they are
activity and gender. -
In the Operations table, add
one row by clicking the [+] button once
and configure this row as follows to calculate the popularity of each activity:Column
Description
Output column
Select the column from the output schema to carry the calculated
results. In this scenario, it is popularity.Function
Select the function to be used to process the incoming data. In this
scenario, select count. It counts the
frequency of each activity in the received messages.Input column position
Select the column from the input schema to provide the data to be
processed. In this scenario, it is activity.
Executing the Job
Then you can run this Job.
The tLogRow component is used to present the
execution result of the Job.
Press F6 to run this Job
Once done, the Run view is opened automatically,
where you can check the execution result.

You can read that the activity Drink is the most
popular with 3 occurrences for the gender M
(Male) and 1 occurrence for the gender F (Female)
in the messages.
The Storm topology continues to run, waiting for messages to appear on the Kafka
message broker until you kill the Job. In this scenario, because the Kill topology on quitting Talend Job check box is
selected, the Storm topology will be stopped and removed from the cluster when this
Job is stopped.