tSQLTemplateAggregate
Provides a set of matrix based on values or calculations.
tSQLTemplateAggregate collects data
values from one or more columns with the intent to manage the collection as a single
unit. This component has real-time capabilities since it runs the data transformation on
the DBMS itself.
tSQLTemplateAggregate Standard properties
These properties are used to configure tSQLTemplateAggregate running in the Standard Job framework.
The Standard
tSQLTemplateAggregate component belongs to the ELT family.
The component in this framework is available in all Talend
products.
Basic settings
|
Database Type |
Select the database type you want to connect to from the |
|
Component List |
Select the relevant DB connection component in the list if you use |
|
Database name |
Name of the database. |
|
Source table name |
Name of the table holding the data you want to collect values |
|
Target table name |
Name of the table you want to write the collected and transformed |
|
Schema and Edit |
A schema is a row description, that is to say, it defines the Click Edit
|
|
|
Built-in: You create and store |
|
|
Repository: You have already |
|
Operations |
Select the type of operation along with the value to use for the |
|
|
Output Column: Select the |
|
|
Function: Select any of the |
|
|
Input column position: Select the |
|
Group by |
Define the aggregation sets, the values of which will be used for |
|
|
Output Column: Select the column |
|
|
Input Column position: Match the |
Advanced settings
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
QUERY: the query statement being processed. This is a Flow
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is used as an intermediate component with other |
|
SQL Template |
SQL Template List |
Filtering and aggregating table columns directly on the
DBMS
The following scenario creates a Job that opens a connection to a Mysql
database and:
-
instantiates the schemas from a database table whose rows match
the column names specified in the filter, -
filters a column in the same database table to have only the data
that matches a WHERE clause, -
collects data grouped by specific value(s) from the filtered
column and writes aggregated data in a target database table.
To filter and aggregate database table columns:
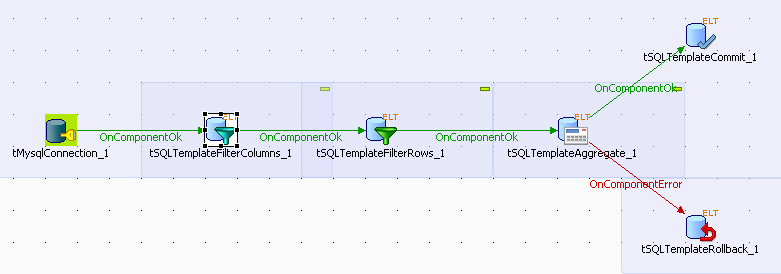
-
Drop the following components from the Palette onto the design workspace: tELTMysqlconnection, tSQLTemplateFilterColumns, tSQLTemplateFilterRows, tSQLTemplateAggregate, tSQLTemplateCommit, and tSQLTemplateRollback.
-
Connect the five first components using OnComponentOk links.
-
Connect tSQLTemplateAggregate to tSQLTemplateRollback using an OnComponentError link.
-
In the design workspace, select tMysqlConnection and click the Component tab to define the basic settings for tMysqlConnection.
-
In the Basic settings
view, set the database connection details manually or select Repository from the Property Type list and select your DB connection if it has
already been defined and stored in the Metadata area of the Repository tree view.
For more information about Metadata, see
Talend Studio User Guide.

-
In the design workspace, select tSQLTemplateFilterColumns and click the Component tab to define its basic settings.
-
On the Database type list,
select the relevant database. -
On the Component list,
select the relevant database connection component if more than one connection is
used. -
Enter the names for the database, source table, and target table
in the corresponding fields and click the three-dot buttons next to Edit schema to define the data structure in the
source and target tables.
When you define the data structure for the source table, column names
automatically appear in the Column list in
the Column filters panel.
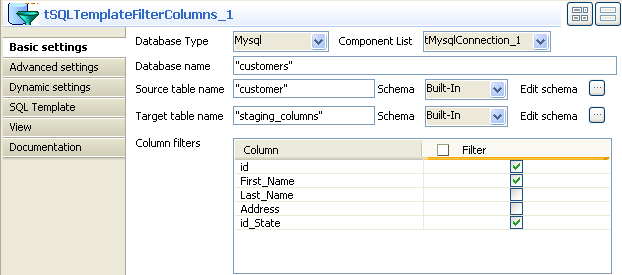
In this scenario, the source table has five columns: id, First_Name, Last_Name, Address, and id_State.
-
In the Column filters
panel, set the column filter by selecting the check boxes of the columns you
want to write in the source table.
In this scenario, the tSQLTemplateFilterColumns component instantiates only three columns: id, First_Name, and id_State from the
source table.
In the Component view, you can
click the SQL Template tab and add system SQL
templates or create your own and use them within your Job to carry out the coded
operation. For more information, see tSQLTemplateFilterColumns Standard properties.
-
In the design workspace, select tSQLTemplateFilterRows and click the Component tab to define its basic settings.

-
On the Database type list,
select the relevant database. -
On the Component list,
select the relevant database connection component if more than one connection is
used. -
Enter the names for the database, source table, and target table
in the corresponding fields and click the three-dot buttons next to Edit schema to define the data structure in the
source and target tables.
In this scenario, the source table has the three initially instantiated
columns: id, First_Name, and id_State and
the source table has the same three-column schema.
-
In the Where condition
field, enter a WHERE clause to extract only those records that fulfill the
specified criterion.
In this scenario, the tSQLTemplateFilterRows
component filters the First_Name column in the source
table to extract only the first names that contain the “a” letter.
-
In the design workspace, select tSQLTemplateAggregate and click the Component tab to define its basic settings.
-
On the Database type list,
select the relevant database. -
On the Component list,
select the relevant database connection component if more than one connection is
used. -
Enter the names for the database, source table, and target table
in the corresponding fields and click the three-dot buttons next to Edit schema to define the data structure in the
source and target tables.
The schema for the source table consists of the three columns: id, First_Name, and id_State. The schema
for the target table consists of two columns: customers_status
and customers_number. In this scenario, we want to group
customers by their marital status and count customer number in each marital group. To do
that, we define the Operations and Group by panels accordingly.

-
In the Operations panel,
click the plus button to add one or more lines and then click in the Output column line to select the output column
that will hold the counted data. -
Click in the Function line
and select the operation to be carried on. -
In the Group by panel,
click the plus button to add one or more lines and then click in the Output column line to select the output column
that will hold the aggregated data. -
In the design workspace, select tSQLTemplateCommit and click the Component tab to define its basic settings.
-
On the Database type list,
select the relevant database. -
On the Component list,
select the relevant database connection component if more than one connection is
used. -
Do the same for tSQLTemplateRollback.
-
Save your Job and press F6
to execute it.
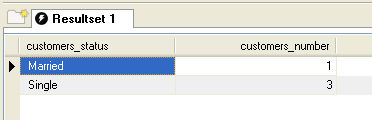
A two-column table aggregate_customers is created
in the database. It groups customers according to their marital status and count
customer number in each marital group.