tFileOutputJSON
file.
Depending on the Talend solution you
are using, this component can be used in one, some or all of the following Job
frameworks:
-
Standard: see tFileOutputJSON Standard properties.
The component in this framework is generally available.
-
MapReduce: see tFileOutputJSON MapReduce properties.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data. -
Spark Batch: see tFileOutputJSON properties for Apache Spark Batch.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data. -
Spark Streaming: see tFileOutputJSON properties for Apache Spark Streaming.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
tFileOutputJSON Standard properties
These properties are used to configure tFileOutputJSON running in the Standard Job framework.
The Standard
tFileOutputJSON component belongs to the File family.
The component in this framework is generally available.
Basic settings
|
File Name |
Name and path of the output file. |
|
Generate an array json |
Select this check box to generate an array JSON file. |
|
Name of data block |
Enter a name for the data block to be written, between double This field disappears when the Generate an |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Sync columns |
Click to synchronize the output file schema with the input file |
Advanced settings
|
Create directory if not exists |
This check box is selected by default. This option creates the |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to rewrite received data in a JSON structured |
Scenario: Writing a JSON structured file
This is a 2 component scenario in which a
tRowGenerator component generates random data which a tFileOutputJSON component then writes to a JSON structured
output file.

Procedure
-
Drop a tRowGenerator and a tFileOutputJSON component onto the workspace from the
Palette. -
Link the components using a Row > Main
connection. -
Double click tRowGenerator to define
its Basic Settings properties in the
Component view.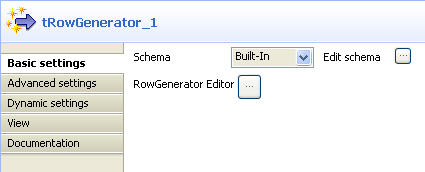
-
Click […] next to Edit Schema to display the corresponding dialog box and define
the schema.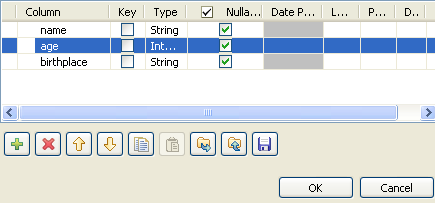
-
Click [+] to add the number of columns
desired. -
Under Columns type in the column
names. -
Under Type, select the data type from the
list. - Click OK to close the dialog box.
-
Click [+] next to RowGenerator Editor to open the corresponding dialog box.
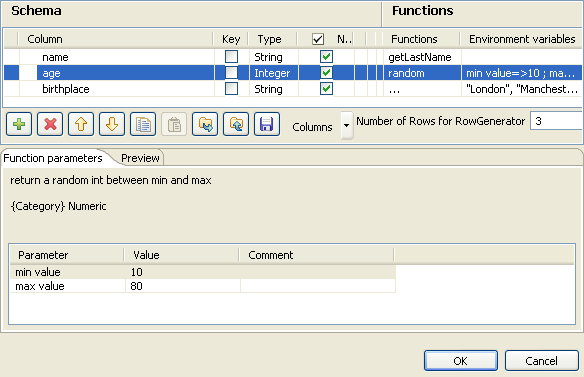
-
Under Functions, select pre-defined functions
for the columns, if required, or select […]
to set customized function parameters in the Function
parameters tab. - Enter the number of rows to be generated in the corresponding field.
- Click OK to close the dialog box.
-
Click tFileOutputJSON to set its Basic Settings properties in the Component view.
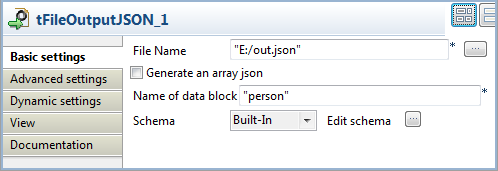
-
Click […] to browse to where you want the
output JSON file to be generated and enter the file name. -
Enter a name for the data block to be generated in the corresponding field,
between double quotation marks. - Select Built-In as the Schema type.
-
Click Sync Columns to retrieve the schema
from the preceding component. -
Press F6 to run the Job.

The data from the input schema is written in a JSON structured data block in the
output file.
tFileOutputJSON MapReduce properties
These properties are used to configure tFileOutputJSON running in the MapReduce Job framework.
The MapReduce
tFileOutputJSON component belongs to the MapReduce family.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Folder |
Enter the folder on HDFS where you want to store the JSON output The folder will be created automatically if it does not Note that you need |
|
Output type |
Select the structure for the JSON output file(s).
|
|
Name of data block |
Type in the name of the data block for the JSON output This field will be available only if you select All in one block from the Output type list. |
|
Action |
Select the action that you want to perform on the data:
|
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to rewrite received data in a JSON structured output file. In a Once a Map/Reduce Job is opened in the workspace, tFileOutputJSON as well as the MapReduce Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
|
Prerequisites |
The Hadoop distribution must be properly installed, so as to guarantee the interaction
For further information about how to install a Hadoop distribution, see the manuals |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tFileOutputJSON properties for Apache Spark Batch
These properties are used to configure tFileOutputJSON running in the Spark Batch Job framework.
The Spark Batch
tFileOutputJSON component belongs to the File family.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. For |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Folder |
Browse to, or enter the path pointing to the data to be used in the file system. Note that this path must point to a folder rather than a file. The button for browsing does not work with the Spark Local mode; if you are using the Spark Yarn or the Spark Standalone mode, |
|
Output type |
Select the structure for the JSON output file(s).
|
|
Name of data block |
Type in the name of the data block for the JSON output This field will be available only if you select All in one block from the Output type list. |
|
Action |
Select the action that you want to perform on the data:
|
Usage
|
Usage rule |
This component is used as an end component and requires an input link. This component, along with the Spark Batch component Palette it belongs to, appears only Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tFileOutputJSON properties for Apache Spark Streaming
These properties are used to configure tFileOutputJSON running in the Spark Streaming Job framework.
The Spark Streaming
tFileOutputJSON component belongs to the File family.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. For |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Folder |
Browse to, or enter the path pointing to the data to be used in the file system. Note that this path must point to a folder rather than a file. The button for browsing does not work with the Spark Local mode; if you are using the Spark Yarn or the Spark Standalone mode, |
|
Output type |
Select the structure for the JSON output file(s).
|
|
Name of data block |
Type in the name of the data block for the JSON output This field will be available only if you select All in one block from the Output type list. |
|
Action |
Select the action that you want to perform on the data:
|
Usage
|
Usage rule |
This component is used as an end component and requires an input link. This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.