tExtractXMLField
the schema to the following component.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tExtractXMLField Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tExtractXMLField MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tExtractXMLField properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tExtractXMLField properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tExtractXMLField Standard properties
These properties are used to configure tExtractXMLField running in the Standard Job framework.
The Standard
tExtractXMLField component belongs to the Processing and the XML families.
The component in this framework is available in all Talend
products.
Basic settings
|
Property type |
Either Built-In or Repository. Click Edit
|
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the When this file is selected, the fields that |
|
Schema type and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
XML field |
Name of the XML field to be processed. Related topic: see |
|
Loop XPath query |
Node of the XML tree, which the loop is based on. |
|
Mapping |
Column: reflects the schema as
XPath Query: Enter the fields to be
Get nodes: Select this check box to |
|
Limit |
Maximum number of rows to be processed. If Limit is 0, no rows are |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Ignore the namespaces |
Select this check box to ignore namespaces when reading and |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a Job |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the
NB_LINE: the number of rows processed. This is an After A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is an intermediate component. It needs an input and |
Extracting XML data from a field in a database table
of a database table and then extracts the data.
Procedure
-
Drop the following components from the Palette onto the design workspace: tMysqlInput, tExtractXMLField,
and tFileOutputDelimited.Connect the three components using Main
links.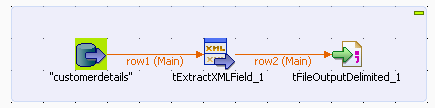
-
Double-click tMysqlInput to display its
Basic settings view and define its
properties.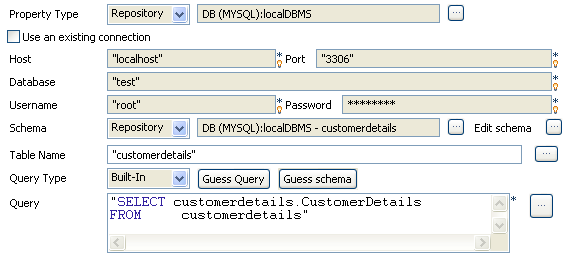
-
If you have already stored the input schema in the Repository tree view, select Repository first from the Property
Type list and then from the Schema list to display the Repository
Content dialog box where you can select the relevant metadata.For more information about storing schema metadata in the Repository tree view, see
Talend Studio User
Guide.If you have not stored the input schema locally, select Built-in in the Property Type
and Schema fields and enter the database
connection and the data structure information manually. For more information
about tMysqlInput properties, see tMysqlInput. -
In the Table Name field, enter the name of
the table holding the XML data, customerdetails in this
example.Click Guess Query to display the query
corresponding to your schema. -
Double-click tExtractXMLField to display its
Basic settings view and define its
properties.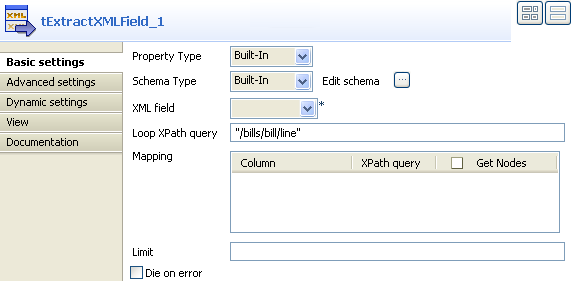
-
Click Sync columns to retrieve the schema
from the preceding component. You can click the three-dot button next to
Edit schema to view/modify the
schema.The Column field in the Mapping table will be automatically populated with the defined
schema. -
In the Xml field list, select the column from
which you want to extract the XML data. In this example, the filed holding the
XML data is called CustomerDetails.In the Loop XPath query field, enter the node
of the XML tree on which to loop to retrieve data.In the Xpath query column, enter between
inverted commas the node of the XML field holding the data you want to extract,
CustomerName in this example. -
Double-click tFileOutputDelimited to display
its Basic settings view and define its
properties.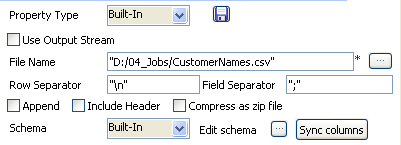
-
In the File Name field, define or browse to
the path of the output file you want to write the extracted data in.Click Sync columns to retrieve the schema
from the preceding component. If needed, click the three-dot button next to
Edit schema to view the schema. -
Save your Job and click F6 to execute
it.

tExtractXMLField read and extracted the clients names
under the node CustomerName of the CustomerDetails
field of the defined database table.
Extracting correct and erroneous data from an XML field in a delimited
file
delimited file, outputs the main data and rejects the erroneous data.
Procedure
-
Drop the following components from the Palette to the design workspace: tFileInputDelimited, tExtractXMLField, tFileOutputDelimited and tLogRow.
Connect the first three components using Row
Main links.Connect tExtractXMLField to tLogRow using a Row
Reject link.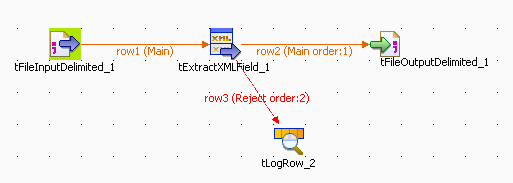
-
Double-click tFileInputDelimited to open its
Basic settings view and define the
component properties.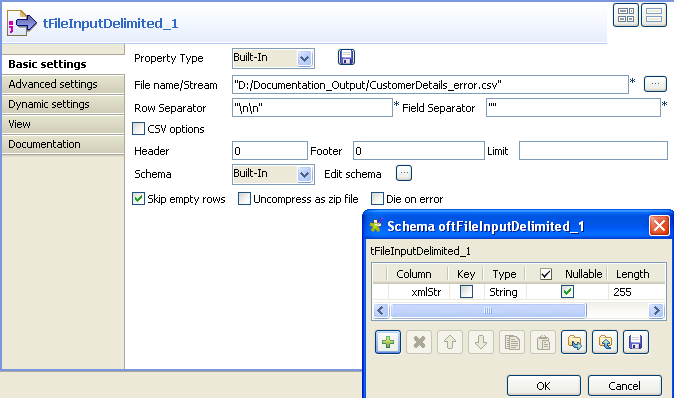
-
Select Built-in in the Schema list and fill in the file metadata manually in the
corresponding fields.Click the three-dot button next to Edit
schema to display a dialog box where you can define the structure
of your data.Click the plus button to add as many columns as needed to your data structure.
In this example, we have one column in the schema:
xmlStr.Click OK to validate your changes and close
the dialog box.Note:If you have already stored the schema in the Metadata folder under File
delimited, select Repository
from the Schema list and click the
three-dot button next to the field to display the Repository Content dialog box where you can select the
relevant schema from the list. Click Ok to
close the dialog box and have the fields automatically filled in with the
schema metadata.For more information about storing schema metadata in the Repository tree
view, see
Talend Studio User Guide. -
In the File Name field, click the three-dot
button and browse to the input delimited file you want to process,
CustomerDetails_Error in this example.This delimited file holds a number of simple XML lines separated by double
carriage return.Set the row and field separators used in the input file in the corresponding
fields, double carriage return for the first and nothing for the second in this
example.If needed, set Header, Footer and Limit. None is used
in this example. -
In the design workspace, double-click tExtractXMLField to display its Basic
settings view and define the component properties.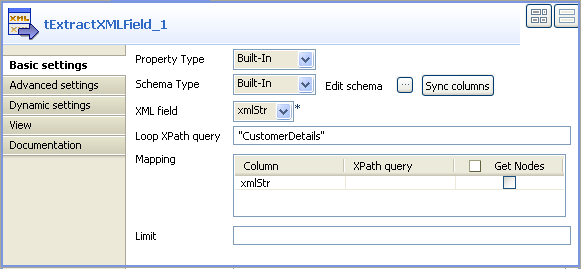
-
Click Sync columns to retrieve the schema
from the preceding component. You can click the three-dot button next to
Edit schema to view/modify the
schema.The Column field in the Mapping table will be automatically populated with the defined
schema. -
In the Xml field list, select the column from
which you want to extract the XML data. In this example, the filed holding the
XML data is called xmlStr.In the Loop XPath query field, enter the node
of the XML tree on which to loop to retrieve data. -
In the design workspace, double-click tFileOutputDelimited to open its Basic
settings view and display the component properties.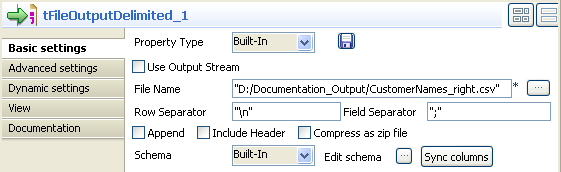
-
In the File Name field, define or browse to
the output file you want to write the correct data in,
CustomerNames_right.csv in this example.Click Sync columns to retrieve the schema of
the preceding component. You can click the three-dot button next to Edit schema to view/modify the schema. -
In the design workspace, double-click tLogRow
to display its Basic settings view and define
the component properties.Click Sync Columns to retrieve the schema of
the preceding component. For more information on this component, see tLogRow. -
Save your Job and press F6 to execute it.

tExtractXMLField reads and extracts in the output
delimited file, CustomerNames_right, the client information for
which the XML structure is correct, and displays as well erroneous data on the console
of the Run view.
tExtractXMLField MapReduce properties (deprecated)
These properties are used to configure tExtractXMLField running in the MapReduce Job framework.
The MapReduce
tExtractXMLField component belongs to the XML family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. Click Edit
|
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the When this file is selected, the fields that |
|
Schema type and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
XML field |
Name of the XML field to be processed. Related topic: see |
|
Loop XPath query |
Node of the XML tree, which the loop is based on. |
|
Mapping |
Column: reflects the schema as
XPath Query: Enter the fields to be
Get nodes: Select this check box to |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Ignore the namespaces |
Select this check box to ignore namespaces when reading and |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a For further information about a Note that in this documentation, unless otherwise |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tExtractXMLField properties for Apache Spark Batch
These properties are used to configure tExtractXMLField running in the Spark Batch Job framework.
The Spark Batch
tExtractXMLField component belongs to the XML family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Property type |
Either Built-In or Repository. Click Edit
|
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the When this file is selected, the fields that |
|
Schema type and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
XML field |
Name of the XML field to be processed. Related topic: see |
|
Loop XPath query |
Node of the XML tree, which the loop is based on. |
|
Mapping |
Column: reflects the schema as
XPath Query: Enter the fields to be
Get nodes: Select this check box to |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Advanced settings
|
Ignore the namespaces |
Select this check box to ignore namespaces when reading and |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tExtractXMLField properties for Apache Spark Streaming
These properties are used to configure tExtractXMLField running in the Spark Streaming Job framework.
The Spark Streaming
tExtractXMLField component belongs to the XML family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Property type |
Either Built-In or Repository. Click Edit
|
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the When this file is selected, the fields that |
|
Schema type and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
XML field |
Name of the XML field to be processed. Related topic: see |
|
Loop XPath query |
Node of the XML tree, which the loop is based on. |
|
Mapping |
Column: reflects the schema as
XPath Query: Enter the fields to be
Get nodes: Select this check box to |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Ignore the namespaces |
Select this check box to ignore namespaces when reading and |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.