
|
Component family |
Processing/Fields |
|
|
Function |
Denormalizes the input flow based on one column. |
|
|
Purpose |
tDenormalize helps synthesize the |
|
|
Basic settings |
Schema and Edit |
A schema is a row description, it defines the number of fields to be processed and Since version 5.6, both the Built-In mode and the Repository mode are Click Edit schema to make changes to the schema. If the
|
|
|
|
Built-in: The schema will be |
|
Repository: The schema already |
||
|
To denormalize |
In this table, define the parameters used to denormalize your
Column: Select the column to
Delimiter: Type in the separator
Merge same value: Select this check |
|
|
Advanced settings |
tStatCatcher Statistics |
Select this check box to collect the log data at component |
|
Global Variables |
ERROR_MESSAGE: the error message generated by the NB_LINE: the number of rows read by an input component or A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see Talend Studio |
|
|
Usage |
This component can be used as intermediate step in a data |
|
|
Usage in Map/Reduce Jobs |
If you have subscribed to one of the Talend solutions with Big Data, you can also For further information about a Talend Map/Reduce Job, see the sections Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
|
Log4j |
The activity of this component can be logged using the log4j feature. For more information on this feature, see Talend Studio User For more information on the log4j logging levels, see the Apache documentation at http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html. |
|
|
Limitation |
n/a |
|
This scenario illustrates a Job denormalizing one column in a delimited file.

-
Drop the following components: tFileInputDelimited, tDenormalize, tLogRow from the
Palette to the design workspace. -
Connect the components using Row main
connections. -
On the tFileInputDelimited Component view, set the filepath to the file to be
denormalized.

-
Define the Header, Row
Separator and Field Separator
parameters. -
The input file schema is made of two columns, Fathers and
Children.
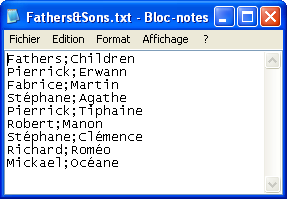
-
In the Basic settings of tDenormalize, define the column that contains
multiple values to be grouped. -
In this use case, the column to denormalize is
Children.

-
Set the Delimiter to separate the grouped
values. Beware as only one column can be denormalized. -
Select the Merge same value check box, if you
know that some values to be grouped are strictly identical. -
Save your Job and press F6 to execute
it.

All values from the column Children (set as column to
denormalize) are grouped by their Fathers column. Values are
separated by a comma.
This scenario illustrates a Job denormalizing two columns from a delimited
file.

-
Drop the following components: tFileInputDelimited, tDenormalize, tLogRow from the
Palette to the design workspace. -
Connect all components using a Row main
connection. -
On the tFileInputDelimited
Basic settings panel, set the filepath to the
file to be denormalized.
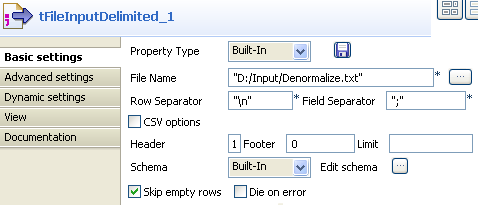
-
Define the Row and Field separators, the Header and other information if required.
-
The file schema is made of four columns including: Name, FirstName, HomeTown, WorkTown.

-
In the tDenormalize component Basic settings, select the columns that contain the
repetition. These are the column which are meant to occur multiple times in the
document. In this use case, FirstName,
HomeCity and WorkCity are the
columns against which the denormalization is performed. -
Add as many line to the table as you need using the plus button. Then select
the relevant columns in the drop-down list.

-
In the Delimiter column, define the separator
between double quotes, to split concanated values. For
FirstName column, type in “#”, for
HomeCity, type in “§”, ans for
WorkCity, type in “¤”. -
Save your Job and press F6 to execute
it.

-
The result shows the denormalized values concatenated using a comma.
-
Back to the tDenormalize components Basic settings, in the To denormalize table, select
the Merge same value check box to remove the
duplicate occurrences. -
Save your Job again and press F6 to execute
it.

This time, the console shows the results with no duplicate instances.