
Warning
This component will be available in the Palette of
Talend Studio on the condition that you have subscribed to one of
the Talend Platform products.
|
Component family |
Data Quality |
|
|
Function |
tRuleSurvivorship receives |
|
|
Purpose |
tRuleSurvivorship creates the |
|
|
Basic settings |
Schema and Edit |
A schema is a row description, it defines the number of fields to be processed and Since version 5.6, both the Built-In mode and the Repository mode are This component provides two read-only columns:
|
|
|
|
Built-in: The schema will be |
|
|
|
Repository: The schema already |
|
Group identifier |
Select the column whose content indicates the required group |
|
|
Group size |
Select the column whose content indicates the required group size |
|
|
|
Rule package name |
Type in the name of the rule package you want to create with this |
| Generate rules and survivorship flow |
Once you have defined all of the rules of a rule package or NoteThis step is necessary to validate these changes and take them |
|
|
|
Rule table |
Complete this table to create a complete survivor validation flow. Order: From the list, select the
Rule Name: Type in the name of Reference column: Select the Function: Select the type of
Value: enter the expression of Target column: when a step is Ignore blanks: Select the check |
|
Advanced settings |
tStatCatcher Statistics |
Select this check box to collect log data at the Job and the |
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see Talend Studio |
|
|
Usage |
This component requires an input component and an output As it needs grouped data to process, this component works It also requires that the input data are sorted by the group When you export a Job using tRuleSurvivorship, you need to select the Export dependencies check box in order to |
|
The Job in this scenario uses five components to group the duplicate data and create
one single representation of these duplicates. This representation is the “survivor” at
the end of the selection process and you can use this survivor, for example, to create a
master copy of data for MDM.

The components used in this Job are:
-
tFixedFlowInput: it provides the input data
to be processed by this Job. In the real-world use case, you may use another
input component of interest to replace tFixedFlowInput for providing the required data. -
tMatchGroup: it groups the duplicates of the
input data and gives each group the information about its group ID and group
size. The technical names of the information are GID and GRP_SIZE respectively
and they are required by tRuleSurvivorship. -
tRuleSurvivorship: it creates the
user-defined survivor validation flow to select the best-of-breed data that
composes the single representation of each duplicates group. -
tFilterColumns: it rules out the technical
columns and outputs the columns that carry the actual information of interest. -
tLogRow: it presents the result of the Job
execution.
-
Drop tFixedFlowInput, tMatchGroup, tRuleSurvivorship, tFilterColumns and tLogRow
from Palette onto the Design
workspace. -
Right-click tFixedFlowInput to open its
contextual menu and select the Row >
Main link from this menu to connect
this component to tMatchGroup. -
Do the same to create the Main link from
tMatchGroup to tRuleSurvivorship, then to tFilterColumns and to tLogRow.
Setting up the input records
-
Double-click tFixedFlowInput to open its
Component view.
-
Click the three-dot button next to Edit
schema to open the schema editor.
-
Click the plus button nine times to add nine rows and rename these rows
respectively. In this example, they are: acctName, addr, city, state,
zip, country, phone, data, credibility. They are the nine columns of the schema of the
input data. -
In the Type column, select the data types
for the rows of interest. In this example, select Date for the data column
and Double for the credibility column.Note
Be aware of setting the proper data type so that later you are able to
define the validation rules easily. -
In the Date Pattern column, type in the
data pattern to reflect the date format of interest. In this scenario, this
format is yyyyMMdd. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Mode area of the Basic settings view, select Use Inline Content (delimited file) to enter the input data
of interest. -
In the Content field, enter the input
data to be processed. This data should correspond to the schema you have
defined and in this example, the contents of the data are:1234GRIZZARD CO.;110 N MARYLAND AVE;GLENDALE;CA;912066;FR;8185431314;20110101;5GRIZZARD;110 NORTH MARYLAND AVENUE;GLENDALE;CA;912066;US;9003254892;20110118;4GRIZZARD INC;110 N. MARYLAND AVENUE;GLENDALE;CA;91206;US;(818) 543-1315;20110103;2GRIZZARD CO;1480 S COLORADO BOULEVARD;LOS ANGELES;CA;91206;US;(800) 325-4892;20110115;1
Grouping the duplicate records
-
Right-click tMatchGroup to open its
contextual menu and select Configuration
Wizard.From the wizard, you can see how your groups look like and you can adjust
the component settings in order to correctly get the similar matches.
-
Click the plus button under the Key
Definition table to add one row. -
In the Input Key Attribute column of this
row, select acctName. This way, this
column becomes the reference used to match the duplicates of the input data. -
In the Matching Function column, select
the Jaro-Winkler matching algorithm. -
In the Match threshold field, enter the
numerical value to indicate at which value two record fields match each
other. In this example, type in 0.6. -
Click Chart to execute this matching rule
and show the result in this wizard.If the input records are not put into one single group, replace 0.6 with a smaller value and click Chart again to check the result until all of the
four records are in the same group.The Job in this scenario puts four similar records into one single
duplicates group so that tRuleSurvivorship
is able to create one survivor from them. This simple sample allows you to
have a clear picture about how tRuleSurvivorship works along with other components to
create the best data. However, in the real-world case, you may need to
process much more data with complex duplicate situation and thus put the
data into much more groups. -
Click OK to close this Configuration wizard and the Basic settings view of the tMatchGroup component is automatically filled with the
parameters you have set.For further information about the Configuration
wizard, see Configuration wizard
Having configured and grouped the input data, you need to create the survivor
validation flow using tRuleSurvivorship. To do
this, proceed as follows:
-
Double-click tRuleSurvivorship to open
its Component view.
-
Select GID for the Group identifier field and GRP_SIZE for the Group
size field. -
In the Rule package name field, enter the
name of the rule package you need to create to define the survivor
validation flow of interest. In this example, this name is org.talend.survivorship.sample. -
In the Rule table, click the plus button
to add as many rows as required and complete them using the corresponding
rule definitions. In this example, add ten rows and complete them using the
contents as follows:Order
Rule name
Reference column
Function
Value
Target column
Sequential
"1_LengthAcct"acctName
Expression
".length >11"acctName
Sequential
"2_LongestAddr"addr
Longest
n/a
addr
Sequential
"3_HighCredibility"credibility
Expression
"> 3"credibility
Sequential
"4_MostCommonCity"city
Most common
n/a
city
Sequential
"5_MostCommonZip"zip
Most common
n/a
zip
Multi-condition
n/a
zip
Match regex
"\d{5}"n/a
Multi-target
n/a
n/a
n/a
n/a
state
Multi-target
n/a
n/a
n/a
n/a
country
Sequential
"6_LatestPhone"date
Most recent
n/a
phone
Multi-target
n/a
n/a
n/a
n/a
date
These rules are executed in the top-down order. The Multi-condition rule is one of the conditions of the
5_MostCommonZip rule, so the
rule-compliant zip code should be the most common zip code and meanwhile
have five digits. The zip column is the
target column of the 5_MostCommonZip rule
and the two Multi-target rules below it add
another two target columns, state and
country, so the zip, the state and the country
columns will be the source of the best-of-breed data. Thus once a zip code
is validated, the corresponding record field values from these three columns
will be selected.The same is true to the Sequential rule
6_LatestPhone. Once a date value is
validated, the corresponding record field values will be selected from the
phone and the date columns.Note
In this table, the fields reading n/a indicate that these fields are not available to the
corresponding Order types or Function types you have selected. In the
Rule table of the Basic settings view of tRuleSurvivorship, these unavailable fields are greyed
out. For further information about this rule table, see the properties
table at the beginning of this tRuleSurvivorShip section. -
Next to Generate rules and survivorship
flow, click the icon to generate the rule package with its contents you
icon to generate the rule package with its contents you
have defined.Once done, you can find the generated rule package in the Metadata > Rules Management >
Survivorship Rules directory of your Studio
Repository. From there, you are able to
open the newly created survivor validation flow of this example and read its
diagram. For further information, see Talend Studio
User Guide.
The schema of tRuleSurvivorship includes several
technical columns like GID, GRP_SIZE, which are not interesting in this example, so you may need
to use tFilterColumns to rule these technical
columns out and leave the columns carrying actual data to be output. To do this,
proceed as follows:
-
Double-click tFilterColumns to open its
Component view. -
Click Sync columns to retrieve the schema
from its preceding component. If a dialog box pops up to prompt the
propagation, click Yes to accept it. -
Click the three-dot button next to Edit
schema to open the schema editor. -
On the tFilterColumns side of this
editor, select the GID, GRP_SIZE, MASTER
and SCORE columns and click the red cross
icon below to remove them.
-
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box.
The tLogRow component is used to present the
execution result of the Job. You can configure the presentation mode on its
Component view.
To do this, double-click tLogRow to open the
Component view and in the Mode area, select the Table (print values in
cells of a table) check box.
To execute this Job, press F6.
Once done, the Run view is opened automatically,
where you can check the execution result.
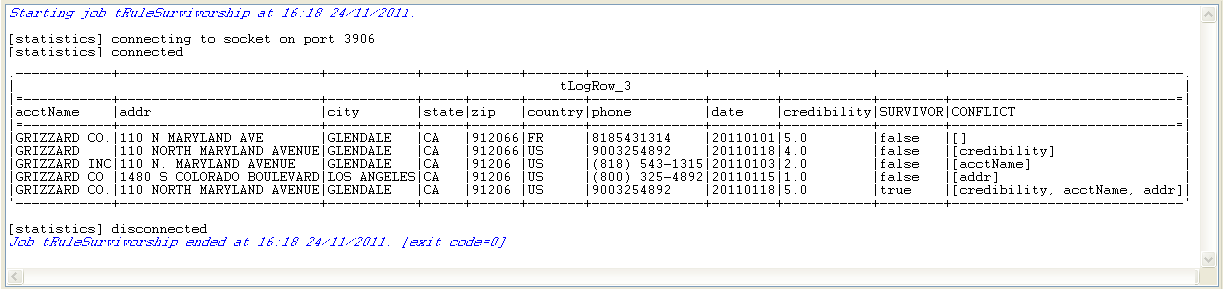
You can read that the last row is the survivor record because its SURVIVOR column indicates true. This record is composed of the best-of-breed data of each
column from the four other rows which are the duplicates of the same group.
The CONFLICT column presents the columns carrying
more than one record field values compliant with the given validation rules. Take
the credibility column for example: apart from
the survivor record whose credibility is 5.0, the
CONFLICT column indicates that the credibility
of the second record GRIZZARD is 4.0, also bigger than 3, the threshold set in the rules you have defined, however, as the
credibility 5.0 appears in the first record
GRIZZARD CO., tRuleSurvivorship selects it as best-of-breed data.
In a Job, the tRuleSurvivorship component generates a
survivorship rule package based on the conditions you define in the Rule table in the component Basic
settings view.
If you want the rule to survive records based on some more advanced criteria, you must
manually code the conditions in the rule using the Drools language.
The Job in this scenario gives an example about how to modify the code in the rule
generated by the component to use specific conditions to create a survivor. Later, you
can use this survivor, for example, to create a master copy of data for MDM.

The components used in this Job are:
-
tFixedFlowInput: it provides the input data
to be processed by this Job. -
tRuleSurvivorship: it creates the survivor
validation flow based on the conditions you code in the rule. This component
selects the best-of-breed data that composes the single representation of each
duplicate group. -
tLogRow: it shows the result of the Job
execution.
-
Drop tFixedFlowInput, tRuleSurvivorship and tLogRow from the palette of the studio onto the Design
workspace. -
Right-click tFixedFlowInput and select
the Row > Main link to connect this component to tRuleSurvivorship. -
Do the same to connect tRuleSurvivorship
to tLogRow using the Row > Main link.
-
Double-click tFixedFlowInput to open its
Component view.
-
Click the three-dot button next to Edit
schema to open the schema editor.
-
Click the plus button and add five rows.
Rename these rows respectively as the following: Record_ID, File,
Acctname, GRP_ID and GRP_SIZE.The input data has information about group ID and group size. In real life
scenario, such information can be gathered by the tMatchGroup component as shown in scenario 1. tMatchGroup groups duplicates in the input data
and gives each group a group ID and a group size. These two columns are
required by tRuleSurvivorship. -
In the Type column, select the data types
for your columns. In this example, set the type to Integer for Record_ID and
GRP_SIZE, and set it to String for the other columns.Note
Make sure to set the proper data type so that you can define the
validation rules without error messages. -
Click OK to validate these changes and
accept the propagation when prompted by the pop-up dialog box. -
In the Mode area of the Basic settings view, select Use Inline Content (delimited file).
-
In the Content field, enter the input
data to be processed.This data should correspond to the schema you have defined. In this
example, the input data is as the following:1234561;2;AcmeFromFile2;1;22;1;AcmeFromFile1;1;03;1;AAA;2;14;2;BBB;3;15;1; ;4;26;2;NotNull;4;0 -
Set the row and field separators in the corresponding fields.
-
Double-click tRuleSurvivorship to open
its Component view.
-
Select GRP_ID from the Group Identifier list and GRP_SIZE from the Group
size list. -
In the Rule package name field, replace
the by-default name org.talend.survivorship.sample with a name of your choice,
if needed.The survivor validation flow will be generated and saved under this name
in the Repository tree view of the
Integration perspective. -
In the Rule table, click the plus button
to add a row per rule.In this example, define one rule and complete it as the following:
Order
Rule name
Reference column
Function
Value
Target column
Sequential
“Rule1”
File
Expression
.equals("1")Acctname
One rule, “Rule1”, will be generated and executed by
tRuleSurvivorship. This rule validates
the records in the File column that
comply with the expression you enter in the Value column of the Rule
table. The component will then select the corresponding value
as the best breed from the Acctname
target column. -
Next to Generate rules and survivorship
flow, click the icon to generate the rule package according to the
conditions you have defined.The rule package is generated and saved under Metadata > Rules Management >
Survivorship Rules in the Repository tree view of the Integration perspective. -
In the Repository tree view, browse to
the rule file under the Survivorship Rules
folder and double-click “Rule1” to open it.
But this rule will select the values that come from file 1. However, you
may also want to survive records based on specific criteria; for example, if
Acctname has a value in file1, you
may want to use that value, or else use the value from file2 instead. To do
this, you must modify the code manually in the rule file. -
Modify the rule with the following Drools code:
123456789101112131415161718192021222324252627package org.talend.survivorship.samplerule "ExistInFile1"no-loop truedialect "mvel"ruleflow-group "Rule1Group"when$input : RecordIn( file.equals("1"), acctname!= null, !acctname.trim().equals("") )thenSystem.out.println("ExistInFile1 fired " + $input.record_id);dataset.survive( $input.TALEND_INTERNAL_ID, "Acctname" );dataset.survive( $input.TALEND_INTERNAL_ID, "File" );endrule "NotExistFile1"no-loop truedialect "mvel"ruleflow-group "Rule1Group"when$input : RecordIn( file.equals("2"), acctname!= null && !acctname.trim().equals("") )(not (exists (RecordIn( file.equals("1") )))or exists( RecordIn( file.equals("1"), acctname== null || acctname.trim().equals("") ) ))thenSystem.out.println("NotExistFile1 fired " + $input.record_id);dataset.survive( $input.TALEND_INTERNAL_ID, "Acctname" );dataset.survive( $input.TALEND_INTERNAL_ID, "File" );endWarning
After you modify the rule file, you must not click the
icon. Otherwise, your modifications will be
replaced by the new generation of the rule package.
-
Double-click tLogRow to open the
Component view and in the Mode area, select the Table
(print values in cells of a table) option.The execution result of the Job will be printed in a table.
-
Press F6 to execute the Job.
The Run view is opened automatically
showing the execution results.
You can read that four rows are the survivor records because their
SURVIVOR column indicates true. In the survivor records, the
Acctname value is selected from file 1, if the
value exists. If not, the value is selected from file 2, as you defined in
the rule. Other rows are the duplicates of same groups.The CONFLICT column shows that no column
has more than one value compliant with the given validation rules.