
|
Component family |
Processing |
|
|
Function |
Sorts input data based on one or several columns, by sort type and |
|
|
Purpose |
Helps creating metrics and classification table. |
|
|
Basic settings |
Schema and Edit |
A schema is a row description, it defines the number of fields to be processed and Since version 5.6, both the Built-In mode and the Repository mode are Click Edit schema to make changes to the schema. If the
Click Sync columns to retrieve This component offers the advantage of the dynamic schema feature. This allows you to This dynamic schema feature is designed for the purpose of retrieving unknown columns |
|
|
|
Built-in: The schema will be |
|
|
|
Repository: The schema already |
|
|
Criteria |
Click + to add as many lines as required for the sort to be |
|
|
|
Schema column: Select the column |
|
|
|
Sort type: Numerical and |
|
|
|
Order: Ascending or descending |
|
Advanced settings |
Sort on disk NoteNot available for the Map/Reduce version of this |
Customize the memory used to temporarily store output data.
Temp data directory path: Set the
Create temp data directory if not
Buffer size of external sort: Type |
|
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the |
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see Talend Studio |
|
|
Usage |
This component handles flow of data therefore it requires input |
|
|
Usage in Map/Reduce Jobs |
If you have subscribed to one of the Talend solutions with Big Data, you can also For further information about a Talend Map/Reduce Job, see the sections For a scenario demonstrate a Map/Reduce Job using this component, Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
|
Limitation |
n/a |
|
This scenario describes a three-component Job. A tRowGenerator is used to create random entries which are directly sent
to a tSortRow to be ordered following a defined value
entry. In this scenario, we suppose the input flow contains names of salespersons along
with their respective sales and their years of presence in the company. The result of
the sorting operation is displayed on the Run
console.

-
Drop the three components required for this use case: tRowGenerator, tSortRow and
tLogRow from the Palette to the design workspace. -
Connect them together using Row
main links. -
On the tRowGenerator editor, define the
values to be randomly used in the Sort component. For more information regarding
the use of this particular component, see tRowGenerator

-
In this scenario, we want to rank each salesperson according to its
Sales value and to its number of years in the
company. -
Double-click tSortRow to display the
Basic settings tab panel. Set the sort
priority on the Sales value and as secondary criteria, set the number of years
in the company.
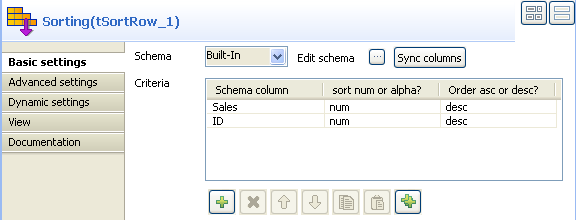
-
Use the plus button to add the number of rows required. Set the type of
sorting, in this case, both criteria being integer, the sort is numerical. At
last, given that the output wanted is a rank classification, set the order as
descending. -
Display the Advanced Settings tab and select
the Sort on disk check box to modify the
temporary memory parameters. In the Temp data directory
path field, type the path to the directory where you want to
store the temporary data. In the Buffer size of external
sort field, set the maximum buffer value you want to allocate to
the processing.
Warning
The default buffer value is 1000000 but the more rows and/or columns you
process, the higher the value needs to be to prevent the Job from automatically
stopping. In that event, an “out of memory” error message displays.
-
Make sure you connected this flow to the output component, tLogRow, to display the result in the Job
console. -
Press F6 to run the Job. The ranking is based
first on the Sales value and then on the number of years of experience.

In this scenario we will sort entries in an input file based on a dynamic schema,
display the sorting result on the Run console, and save
the sorting result in an output file. For more information about the dynamic schema
feature, see Talend Studio User
Guide.

-
Drop the components required for this use case: tFileInputDelimited, tSortRow,
tLogRow and tFileOutputDelimited from the Palette to the design workspace. -
Connect these components together using Row
> Main links. -
Double-click the tFileInputDelimited
component to display its Basic settings view.

Warning
The dynamic schema feature is only supported in Built-In mode and requires the input file to have a
header row.
-
Select Built-In from the Property Type list.
-
Click the […] button next to the File Name field to browse to your input file. In this
use case, the input file cars.csv has five columns:
ID_Owner, Registration,
Make, Color, and
ID_Reseller. -
Specify the header row in Header field. In
this use case the first row is the header row. -
Select Built-In from the Schema list, and click Edit
schema to set the input schema.

Warning
The dynamic column must be defined in the last row of the
schema.
-
In the schema editor, add two columns and name them
ID_Owner and Other respectively.
Set the data type of the Other column to Dynamic to retrieve all the columns undefined in the
schema. -
Click OK to propagate the schema and close
the schema editor. -
Double-click tSortRow to display the
Basic settings view.

-
Add a row in the Criteria table by clicking
the plus button, select Other under Schema column, select alpha as the sorting
type, and select the ascending or
descending order for data output.
Warning
Dynamic column sorting works only when the sorting type is
set to alpha.
-
To view the output in the form of a table on the Run console, double-click the tLogRow component and select the Table option in the Basic
settings view. -
Double-click the tFileOutputDelimited
component to display its Basic Settings
view.

-
Click the […] button next to the File Name field to browse to the directory where you
want to save the output file, and then enter a name for the file. -
Select the Include Header check box to
retrieve the column names as well as the sorted data. -
Save your Job and press F6 to run it.
The sorting result is displayed on the Run
console and written into the output file.
