Blocking
or many blocking keys to split the input dataset into smaller datasets called
blocks.
In each block, the blocking keys must have the same value. Then, each block is processed
independently.
Using blocking keys reduces the time needed by the Simple VSR Matcher and the T-Swoosh
algorithms to process data. For example, if 100,000 records are split into 100 blocks of
1,000 records each, the number of comparisons are reduced by a factor 100. This means
the algorithm runs around 100 times faster.
It is recommended to use the tGenKey component to generate
blocking keys and to visualize the statistics regarding the number of blocks. In a Job,
right-click the tGenKey component and select View Key
Profile in the contextual menu to visualize the distribution of the
number of blocks according to their size.
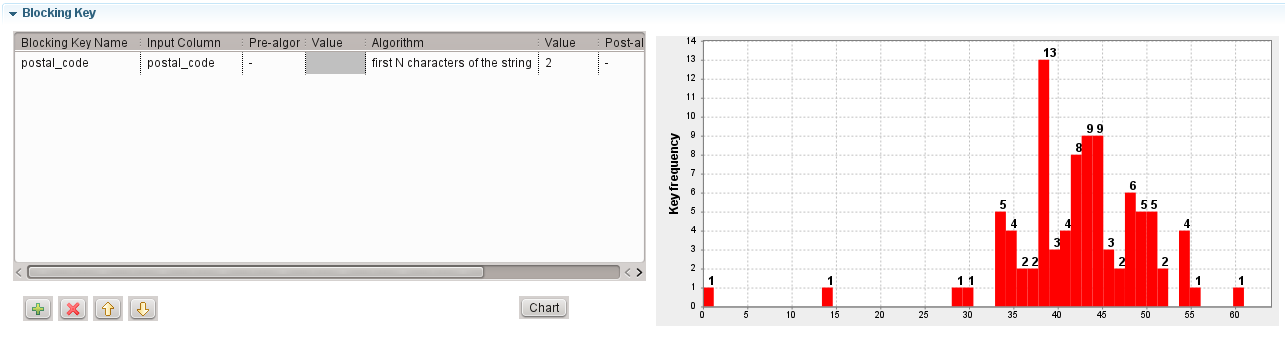
In this example, the average block size is around 40.
For the 13 blocks with 38 rows, there a 18,772 comparisons in these 13 blocks (13 × 382).
If records are compared with four columns, this means there will be 75,088 string
comparisons in these 13 blocks (18,772 × 4).