Scenario: Replacing values and filtering columns using Map/Reduce
components
This scenario applies only to a subscription-based Talend solution with Big data.
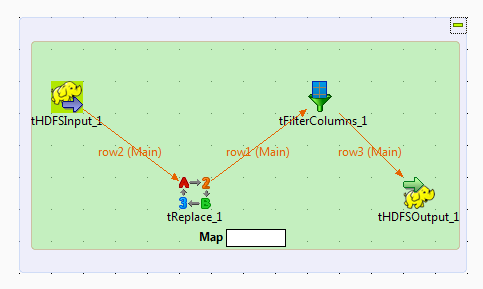
You can use the Map/Reduce version of the Job described earlier using Map/Reduce
components. This
Talend
Map/Reduce Job generates Map/Reduce code and is run
natively in Hadoop.
Note that the
Talend
Map/Reduce components are available to
subscription-based Big Data users only and this scenario can be replicated only with
Map/Reduce components.
earlier, reading as follows:
|
1 2 3 4 5 6 7 |
streat;John;Kennedy;98.30$ streat;Richad;Nikson;78.23$ streat;Richard;Nikson;78.2$ streat;toto;Nikson;78.23$ streat;Richard;Nikson;78.23$ street;Georges *t;bush;99.99$ |
Since
Talend Studio
allows you to convert a Job between its
Map/Reduce and Standard (Non Map/Reduce) versions, you can convert the scenario
explained earlier to create this Map/Reduce Job. This way, many components used can keep
their original settings so as to reduce your workload in designing this Job.
Before starting to replicate this scenario, ensure that you have appropriate rights
and permissions to access the Hadoop distribution to be used. Then proceed as
follows: