tBlockedFuzzyJoin (deprecated)
Helps ensuring the data quality of any
source data against a reference data
source.
tBlockedFuzzyJoin joins two tables by doing a fuzzy match on several columns. It
compares columns from the main flow with reference columns from the lookup flow and outputs
the match data, the possible match data and the rejected data.
tBlockedFuzzyJoin Standard properties
These properties are used to configure tBlockedFuzzyJoin running in the Standard Job framework.
The Standard
tBlockedFuzzyJoin component belongs to the Data Quality family.
This component is available in the Palette of the Studio only if you have subscribed to one of the Talend Platform products.
Basic
settings
|
Schema and |
A schema is a row description, it defines |
|
|
Built-in: |
|
|
Repository: |
|
Replace output column with lookup |
Select this check box to replace the output |
|
Input key |
Select the column(s) from the main flow that |
|
Lookup key |
Select the lookup key columns that you will |
|
Matching type |
Select the relevant matching algorithm from
Exact Match:
Levenshtein:
Metaphone: Based
Double Metaphone: |
|
Case sensitive |
Select this check box to consider the letter |
|
Min. distance |
Only for Levenshtein. Set the minimum number of Note:
You can create and store context variables |
|
Max. distance |
Only for Levenshtein. Set the maximum number of |
Advanced
settings
|
tStat |
Select this check box to collect log data at |
Global
Variables
|
Global |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is deprecated, use the tRecordMatching This component is not startable (green |
Scenario: Doing a fuzzy match on two columns and outputting the match,
possible match and non match values (deprecated)
This scenario applies only to a subscription-based Talend Platform solution or Talend Data Fabric.
This scenario describes a six-component Job that aims at:
-
matching each processed group number in the grp column against the entries that have exactly the same values in the
reference input file, -
checking the edit distance between the entries in the firstname column of an input file against those of the
reference input file.
The outputs of these two matching types are written in three output files:
the first for match values, the second for possible match values and the third for the
values for which there are no matches in the lookup file.
In this scenario, we have already stored the main and reference input
schemas in the Repository. For more information about storing schema metadata in the
Repository, see
Talend Studio User Guide.
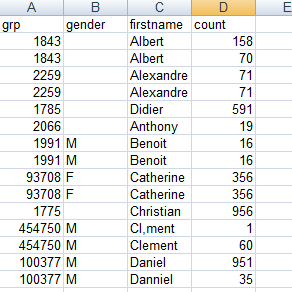
The main input file contains four columns: grp, gender, firstname and count. The data in this input file have problems such as duplication, first names
spelled differently or wrongly, different information for the same customer.
Setting up the Job
-
In the Repository tree view,
expand Metadata and the
FileExcel node
where you have stored the main input schemas and then drop
it onto the design workspace.A tFileInputExcel component holding your schema
displays on the workspace. -
Do the same with the reference input schema to display the
reference tFileInputExcel
on the workspace. -
Drop a tBlockedFuzzyJoin and
tLogRow (x3) from
the Palette onto the design
workspace.
-
Connect the main and reference input Excel files to tBlockedFuzzyJoin using
Main links. The
link between the reference input Excel file and tBlockedFuzzyJoin displays as
a Lookup link on the design
workspace. -
Connect tBlockedFuzzyJoin to
the three tLogrow
components using the Matches, Possible
Matches and Non
Matches links.
Configuring the input components
their Basic settings views.
The capture below shows the properties of the main input
file.

The capture below shows the properties of the reference input
file.

The property fields for both tFileInputExcel components are automatically filled in. If you
do not define your input schemas locally in the Repository, fill in the
details manually after selecting Built-in in the Schema
and Property Type fields.
Configuring the tBlockedFuzzyJoin component
-
Double-click tBlockedFuzzyJoin to display its
Basic settings view
and define its properties.
-
Click the Edit schema button
to open a dialog box. Here you can define the data you want
to pass to the output components.In this example we want to pass the four input columns to the output
components in addition to the new column ref_firstname.
-
Click OK to close the dialog
box and proceed to the next step. -
In the Key definition area of
the Basic settings view of
tBlockedFuzzyJoin,
click the plus button to add two columns to the list. -
Select the input columns and the output columns you want to do
the fuzzy matching on from the Input
key attribute and Lookup key attribute lists respectively,
grp and
firstname in this
example. -
Click in the first cell of the Matching
type column and select from the list the
method to be used to check the incoming data against the
reference data, Exact match in this
example. There is no minimum nor maximum distance to
set. -
Set the matching type for the second column,
Levenshtein in this
example. -
Then set the minimum and maximum distances. In this method,
the distance is the number of character changes (insertion,
deletion or substitution) that needs to be carried out in
order for the entry to fully match the reference. In this
example, we want the min. distance to be 0 and the max.
distance to be 2. This will output all entries in the
firstname column that exactly
match or that have maximum two character changes.
Executing the Job
-
Double-click the first tLogRow
component to display its Basic settings view and define its
properties.
-
In the Mode area, select
Table to display
the source file and the tBlockedFuzzyJoin results together to be
able to compare them. -
Do the same for the other two
tLogRow components. -
Save your Job and press F6 to
execute it.
Three output tables are written on the console. The first shows the match entries,
the second show the possible match entries and the third shows the non match entries
according to the used matching method in the defined columns.
The figure below illustrates extractions of the three output tables.
