tGenKey
Generates a functional key from the input columns, by applying different types of
algorithms on each column and grouping the computed results in one key, then outputs this
key with the input columns.
tGenKey enables you to apply several
kinds of algorithms on each input column and use the computed results to generate a
functional key, which can be used, for example, to narrow down your data filter/matching
results. These algorithms can be key or optional algorithms.
The values returned by the key algorithms will be concatenated, according to
the column order in the Key composition table.
Depending on the Talend solution you
are using, this component can be used in one, some or all of the following Job
frameworks:
-
Standard: see tGenKey Standard properties.
The component in this framework is available when you have subscribed to one of
the Talend Platform products or Talend Data
Fabric. -
MapReduce: see tGenKey MapReduce properties.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric. -
Spark Batch: see tGenKey properties for Apache Spark Batch.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric. -
Spark Streaming: see tGenKey properties for Apache Spark Streaming.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
tGenKey Standard properties
These properties are used to configure tGenKey running in the Standard Job framework.
The Standard
tGenKey component belongs to the Data Quality family.
The component in this framework is available when you have subscribed to one of
the Talend Platform products or Talend Data
Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Sync columns to retrieve the schema from |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Click the import icon to import blocking keys from the match rules that are defined and When you click the import icon, a [Match Rule Selector] You can import blocking keys only from match rules that are defined with the VSR algorithm |
|
Column |
Select the column(s) from the main flow on which you want to define certain algorithms to Note:
When you select a date column on which to apply an algorithm or a matching algorithm, For example, if you want to only compare the year in the date, in the component schema |
|
Pre-Algorithm |
If required, select the relevant matching algorithm from the list:
Remove diacritical marks: removes any diacritical
Remove diacritical marks and lower case: removes any
Remove diacritical marks and upper case: removes any
Lower case: converts the field to lower case before
Upper case: converts the field to upper case before
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the algorithm value, where applicable. |
|
Algorithm |
Select the relevant algorithm from the list:
First character of each word: includes in the functional
N first characters of each word: includes in the
First N characters of the string: includes in the
Last N characters of the string: includes in the
First N consonants of the string: includes in the
First N vowels of the string: includes in the functional
Pick characters: includes in the functional key the
Exact: includes in the functional key the full
Substring(a,b): includes in the functional key character
Soundex code: generates a code according to a standard
Metaphone code: generates a code according to the
Double-metaphone code: generates a code according to the
Fingerprint key: generates the functional key from a
string value through the following sequential process:
nGramkey: this algorithm is similar to the fingerPrintkey method described above. But instead of using
whitespace separated tokens, it uses n-grams, where the n can be specified by the user. This method generates the functional key from a string value through the following sequential process:
Note:
If the column on which you want to use the nGramkey
Cologne phonetics: a soundex phonetic algorithm optimized |
|
Value |
Set the algorithm value, where applicable. If you do not set a value for the algorithms which need one, the Job runs with a |
|
Post-Algorithm |
If required, select the relevant matching algorithm from the list:
Use default value (string): enables you to choose a
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the option value, where applicable. |
|
Show help |
Select this check box to display instructions on how to set algorithms/options |
Advanced settings
|
tStat |
Select this check box to gather the Job processing metadata at the Job level Note that this check box is not available in the Map/Reduce version of |
Global
Variables
|
Global |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is usually used as an intermediate component, and it requires an This component can be used with other components, such as tMatchGroup, in order to create a blocking |
Scenario 1: Generating functional keys in the output flow
This scenario applies only to a subscription-based Talend Platform solution or Talend Data Fabric.
This three-component scenario describes a basic Job that generates a
functional key for each of the data records using one algorithm on one of
the input columns, PostalCode.
This functional key can be used in different ways to narrow down the results
of data filtering or data matching, for example. So the tGenKey component can be used with so many other data
quality and data integration components to form different useful use cases.
For an example of one use case of tGenKey,
see Scenario 2: Comparing columns and grouping in the output flow duplicate records that have the same functional key.
In this scenario, the input data flow has four columns:
Firstname, Lastname,
DOB (date of birth), and
PostalCode. This data has problems such as
duplication, first or last names spelled differently or wrongly, different
information for the same customer, etc. This scenario generates a functional
key for each data record using an algorithm that concatenates the first two
characters of the postal code.

Setting up the Job
-
Drop the following components from the Palette onto the design
workspace: tFixedFlowInput, tGenKey and tLogRow.
-
Connect all the components together using the
Main link.
Configuring the data input
-
Double-click tFixedFlowInput to display the
Basic settings
view and define the component properties.
-
Click the […]
button next to Edit
Schema to open the [Schema] dialog box.
-
Click the plus button to add as many lines as needed
for the input schema you want to create from
internal variables.In this example, the schema is made of four columns:
Firstnam,
Lastname,
DOB and
PostalCode.Then, click OK to
close the dialog box. -
In the Mode area,
select the Use Inline
Table option.The Value table
displays as Inline
Table.
-
Click the plus button to add as many line as needed
and then click in each of the lines to define the
input data for the four columns.
Configuring key generation
-
Double-click tGenKey to
display the Basic settings
view and define the component properties.You can click

and import blocking keys from the match
rules created with the VSR algorithm and tested in the
Profiling
perspective of
Talend Studio
and use them in your
Job. Otherwise, define the blocking key parameters as
described in the below steps. -
Under the Algorithm table,
click the plus button to add a row in this table. -
In the column column, click
the newly added row and select from the list the column you
want to process using an algorithm. In this example, select
PostalCode.Note:When you select a date column on which to apply an algorithm or a matching algorithm,
you can decide what to compare in the date format.For example, if you want to only compare the year in the date, in the component schema
set the type of the date column to Date and then enter
“yyyy” in the Date
Pattern field. The component then converts the date format to a string
according to the pattern defined in the schema before starting a string
comparison. -
Select the Show help check
box to display instructions on how to set algorithms/options
parameters. -
In the algorithm column,
click the newly added row and select from the list the
algorithm you want to apply to the corresponding column. In
this example, select first N
characters of the string. -
Click in the Value column and
enter the value for the selected algorithm, when needed. In
this scenario, type in 2.In this example, we want to generate a functional key that
holds the first two characters of the postal code for each
of the data rows and we do not want to define any extra
options on these columns.Make sure to set a value for the algorithm which need one,
otherwise you may have a compilation error when you run the
Job.
Once you have defined the tGenKey
properties, you can display a statistical view of these parameters.
To do so:
-
Right-click the tGenKey
component and select View Key
Profile in the contextual menu.The View Key Profile editor
displays, allowing you to visualize the statistics regarding
the number of rows per block and to adapt them according to
the results you want to get.When you are processing a large amount of data and when this
component is used to partition data in order to use them in
a matching component (such as tRecordMatching or tMatchGroup), it is preferable to have a
limited number of rows in one block. An amount of about 50
rows per block is considered optimal, but it depends on the
number of fields to compare, the total number of rows and
the time considered acceptable for data processing.For a use example of the View Key
Profile option, see Scenario 2: Comparing columns and grouping in the output flow duplicate records that have the same functional key.
Configuring the console output
-
Double-click the tLogRow
component to display the Basic settings view. -
In the Mode area,
select Table to
display the Job execution result in table cells.
Executing the Job

T_GEN_KEY column are listed
in the Run console.
The functional key for each data record is
concatenated from the first two characters of the
corresponding value in the PostalCode
column.
Scenario 2: Comparing columns and grouping in the output flow duplicate
records that have the same functional key
This scenario applies only to a subscription-based Talend Platform solution or Talend Data Fabric.
This second scenario describes a Job that aims at:
-
generating a functional key using one algorithm on one of the
input columns, DoB as described in
scenario 1. -
matching two input columns using the
Jaro-Winkler algorithm. -
grouping the output columns by the generated functional key to
optimize the matching operation and compare only the records
that have the same blocking value, functional key in this
scenario. For more information on grouping output columns
and using blocking values, see tMatchGroup.

Setting up the Job
-
Drop the following components from the Palette onto the design
workspace: tRowGenerator, tGenKey and tMatchGroup. -
Connect all the components together using the
Main link.
Configuring the data input
-
Double-click tRowGenerator to define its schema as
follows: The tRowGenerator
The tRowGenerator
component will generate an input data flow that has
three columns: Firstname,
Lastname, and DoB
(date of birth). This data may have problems such as
duplication, first or last names spelled differently
or wrongly, different information for the same
customer, etc. -
Click OK to validate
the settings and close the dialog box, and accept to
propagate the changes when prompted.
Configuring key generation
-
Double-click tGenKey
to display the Basic
settings view and define the component
properties.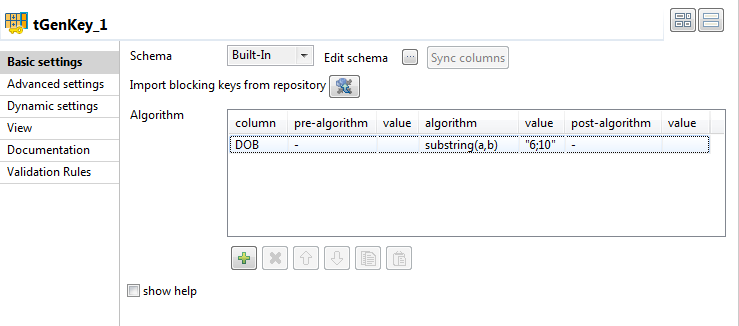 You can click
You can clickand import blocking keys from
the match rules created with the VSR algorithm and
tested in the
Profiling
perspective of
Talend Studio
and use them in your
Job. Otherwise, define the blocking key parameters
as described in the below steps. -
Under the Algorithm
table, click the [+] button to add a row in this
table. -
On the column column,
click the newly added row and select from the list
the column you want to process using an algorithm.
In this example, select
DoB. -
On the algorithm
column, click the newly added row and select from
the list the algorithm you want to apply to the
corresponding column. In this example, select
substring(a,b). -
Click in the value column and enter the value
for the selected algorithm, when needed. In this scenario, type in
6;10.The substring(a,b) algorithm allows you to extract the
characters from a string, between two specified indices, and to return the new
substring. First character is at index 0. In this scenario,
for a given DoB
“21-01-1995“, 6;10 will return only
the year of birth, that is to say “1995” which is the substring from the 7th to
the 10th character.In this example, we want to generate a functional key that holds the last four
characters of the date of birth, which correspond to the year of birth, for each
of the data rows and we do not want to define any extra options on these
columns.You can select the Show help check box to
display instructions on how to set algorithms/options parameters.Once you have defined the tGenKey properties,
you can display a statistical view of these parameters. To do so: -
Right-click on the tGenKey component and
select View Key Profile in the contextual
menu.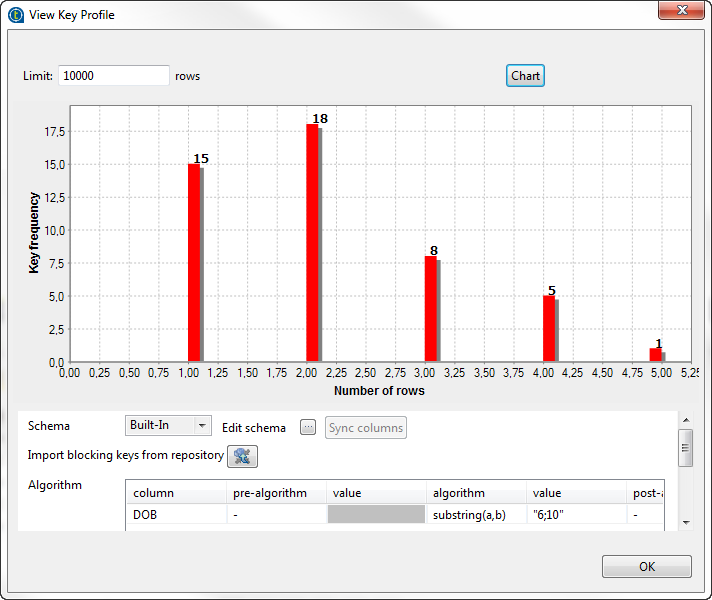 The View Key Profile editor displays,
The View Key Profile editor displays,
allowing you to visualize statistics regarding the number of blocks and to adapt
the parameters according to the results you want to get.Note:When you are processing a large amount of data and when this component is
used to partition data in order to use them in a matching component (such as
tRecordMatching or tMatchGroup), it is preferable to have a limited number of rows
in one block. An amount of about 50 rows per block is considered optimal,
but it depends on the number of fields to compare, the total number of rows
and the time considered acceptable for data processing.From the key editor, you can:-
edit the Limit
of rows used to calculate the statistics. -
click
and import blocking keys
from the Studio repository and use them in your Job. -
edit the input column you want to process using an
algorithm. -
edit the parameters of the algorithm you want to
apply to input columns.
Every time you make a modification, you can see its implications by clicking
the Refresh button which is located at the top
right part of the editor. -
-
Click OK to close the
View Key Profile
editor.
Configuring the grouping of the output data
-
Click the tMatchGroup
component, and then in its basic settings click the
Edit schema
button to view the input and output columns and do
any modifications in the output schema, if
needed. In the output schema of this component, there are
In the output schema of this component, there are
output standard columns that are read-only. For more
information, see tMatchGroup Standard properties. -
Click OK to close the
dialog box. -
Double-click the tMatchGroup component to
display its Configuration Wizard and define the
component properties.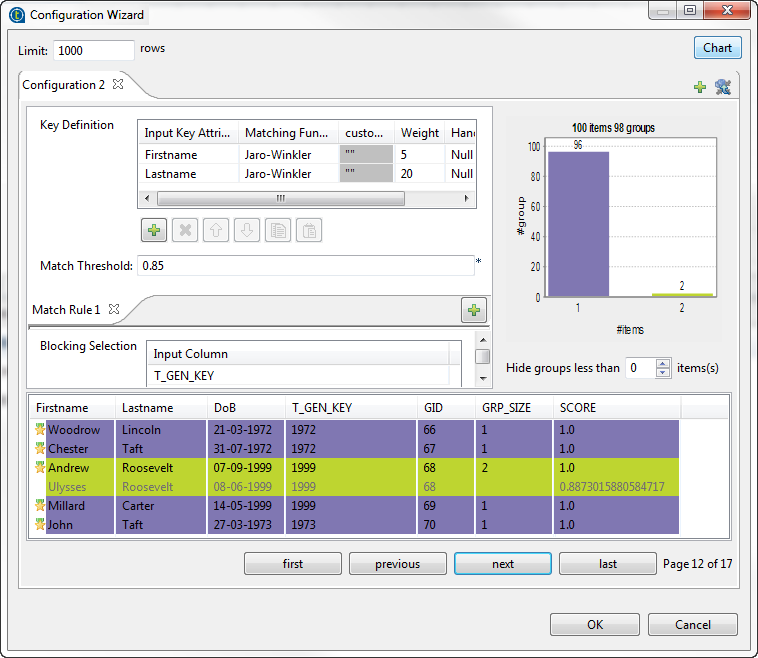 If you want to add a fixed output column,
If you want to add a fixed output column,
MATCHING_DISTANCES, which gives the details of the distance
between each column, click the Advanced
settings tab and select the Output distance
details check box. For more information, see tMatchGroup Standard properties. -
In the Key definition
table, click the plus button to add to the list the
columns on which you want to do the matching
operation, FirstName and
LastName in this
scenario. -
Click in the first and second cells of the Matching Function column
and select from the list the algorithm(s) to be used
for the matching operation,
Jaro-Winkler in this
example. -
Click in the first and second cells of the Weight column and set the
numerical weights for each of the columns used as
key attributes. -
In the Match
threshold field, enter the match
probability threshold. Two data records match when
the probability threshold is above this value.
-
Click the plus button below the Blocking Selection table to add a line
in the table, then click in the line and select from
the list the column you want to use as a blocking
value, T_GEN_KEY in this
example.Using a blocking value reduces the number of pairs of
records that needs to be examined. The input data is
partitioned into exhaustive blocks based on the
functional key. This will decrease the number of
pairs to compare, as comparison is restricted to
record pairs within each block. -
Click the Chart
button in the top right corner of the wizard to
execute the Job in the defined configuration and
have the matching results directly in the
wizard.The matching chart gives a global picture about the
duplicates in the analyzed data. The matching table
indicates the details of items in each group and
colors the groups in accordance with their color in
the matching chart.
Configuring the console output
-
Double-click the tLogRow
component to display the Basic settings view. -
In the Mode area,
select Table to
display the Job execution result in table cells.
Executing the Job

T_GEN_KEY column that holds
the functional key generated by the tGenKey component.
functional key are grouped together in different
blocks “groups”. The identifier for each group is
listed in the GID column next
to the corresponding record. The number of records
in each of the output blocks is listed in the
GRP_SIZE column and computed
only on the master record. The
MASTER column indicates with
true/false if the corresponding record is a master
record or not a master record. The
SCORE column lists the
calculated distance between the input record and the
master record according to the
Jaro-Winkler matching
algorithm.
different blocking keys and using them with multiple
tMatchGroup
components, see tMatchGroup.
tGenKey MapReduce properties
These properties are used to configure tGenKey running in the MapReduce Job framework.
The MapReduce
tGenKey component belongs to the Data Quality family.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Sync columns to retrieve the schema from |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Click the import icon to import blocking keys from the match rules that are defined and When you click the import icon, a [Match Rule Selector] You can import blocking keys only from match rules that are defined with the VSR algorithm |
|
Column |
Select the column(s) from the main flow on which you want to define certain algorithms to Note:
When you select a date column on which to apply an algorithm or a matching algorithm, For example, if you want to only compare the year in the date, in the component schema |
|
Pre-Algorithm |
If required, select the relevant matching algorithm from the list:
Remove diacritical marks: removes any diacritical
Remove diacritical marks and lower case: removes any
Remove diacritical marks and upper case: removes any
Lower case: converts the field to lower case before
Upper case: converts the field to upper case before
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the algorithm value, where applicable. |
|
Algorithm |
Select the relevant algorithm from the list:
First character of each word: includes in the functional
N first characters of each word: includes in the
First N characters of the string: includes in the
Last N characters of the string: includes in the
First N consonants of the string: includes in the
First N vowels of the string: includes in the functional
Pick characters: includes in the functional key the
Exact: includes in the functional key the full
Substring(a,b): includes in the functional key character
Soundex code: generates a code according to a standard
Metaphone code: generates a code according to the
Double-metaphone code: generates a code according to the
Fingerprint key: generates the functional key from a
string value through the following sequential process:
nGramkey: this algorithm is similar to the fingerPrintkey method described above. But instead of using
whitespace separated tokens, it uses n-grams, where the n can be specified by the user. This method generates the functional key from a string value through the following sequential process:
Note:
If the column on which you want to use the nGramkey
Cologne phonetics: a soundex phonetic algorithm optimized |
|
Value |
Set the algorithm value, where applicable. |
|
Post-Algorithm |
If required, select the relevant matching algorithm from the list:
Use default value (string): enables you to choose a
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the option value, where applicable. |
|
Show help |
Select this check box to display instructions on how to set algorithms/options |
Advanced settings
|
tStat |
Select this check box to gather the Job processing metadata at the Job level Note that this check box is not available in the Map/Reduce version of |
Global
Variables
|
Global |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a For further information about a Note that in this documentation, unless otherwise |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tGenKey properties for Apache Spark Batch
These properties are used to configure tGenKey running in the Spark Batch Job framework.
The Spark Batch
tGenKey component belongs to the Data Quality family.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Sync columns to retrieve the schema from |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Click the import icon to import blocking keys from the match rules that are defined and When you click the import icon, a [Match Rule Selector] You can import blocking keys only from match rules that are defined with the VSR algorithm |
|
Column |
Select the column(s) from the main flow on which you want to define certain algorithms to Note:
When you select a date column on which to apply an algorithm or a matching algorithm, For example, if you want to only compare the year in the date, in the component schema |
|
Pre-Algorithm |
If required, select the relevant matching algorithm from the list:
Remove diacritical marks: removes any diacritical
Remove diacritical marks and lower case: removes any
Remove diacritical marks and upper case: removes any
Lower case: converts the field to lower case before
Upper case: converts the field to upper case before
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the algorithm value, where applicable. |
|
Algorithm |
Select the relevant algorithm from the list:
First character of each word: includes in the functional
N first characters of each word: includes in the
First N characters of the string: includes in the
Last N characters of the string: includes in the
First N consonants of the string: includes in the
First N vowels of the string: includes in the functional
Pick characters: includes in the functional key the
Exact: includes in the functional key the full
Substring(a,b): includes in the functional key character
Soundex code: generates a code according to a standard
Metaphone code: generates a code according to the
Double-metaphone code: generates a code according to the
Fingerprint key: generates the functional key from a
string value through the following sequential process:
nGramkey: this algorithm is similar to the fingerPrintkey method described above. But instead of using
whitespace separated tokens, it uses n-grams, where the n can be specified by the user. This method generates the functional key from a string value through the following sequential process:
Note:
If the column on which you want to use the nGramkey
Cologne phonetics: a soundex phonetic algorithm optimized |
|
Value |
Set the algorithm value, where applicable. If you do not set a value for the algorithms which need one, the Job runs with a |
|
Post-Algorithm |
If required, select the relevant matching algorithm from the list:
Use default value (string): enables you to choose a
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the option value, where applicable. |
|
Show help |
Select this check box to display instructions on how to set algorithms/options |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, appears only Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tGenKey properties for Apache Spark Streaming
These properties are used to configure tGenKey running in the Spark Streaming Job framework.
The Spark Streaming
tGenKey component belongs to the Data Quality family.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Sync columns to retrieve the schema from |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
|
Click the import icon to import blocking keys from the match rules that are defined and When you click the import icon, a [Match Rule Selector] You can import blocking keys only from match rules that are defined with the VSR algorithm |
|
Column |
Select the column(s) from the main flow on which you want to define certain algorithms to Note:
When you select a date column on which to apply an algorithm or a matching algorithm, For example, if you want to only compare the year in the date, in the component schema |
|
Pre-Algorithm |
If required, select the relevant matching algorithm from the list:
Remove diacritical marks: removes any diacritical
Remove diacritical marks and lower case: removes any
Remove diacritical marks and upper case: removes any
Lower case: converts the field to lower case before
Upper case: converts the field to upper case before
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the algorithm value, where applicable. |
|
Algorithm |
Select the relevant algorithm from the list:
First character of each word: includes in the functional
N first characters of each word: includes in the
First N characters of the string: includes in the
Last N characters of the string: includes in the
First N consonants of the string: includes in the
First N vowels of the string: includes in the functional
Pick characters: includes in the functional key the
Exact: includes in the functional key the full
Substring(a,b): includes in the functional key character
Soundex code: generates a code according to a standard
Metaphone code: generates a code according to the
Double-metaphone code: generates a code according to the
Fingerprint key: generates the functional key from a
string value through the following sequential process:
nGramkey: this algorithm is similar to the fingerPrintkey method described above. But instead of using
whitespace separated tokens, it uses n-grams, where the n can be specified by the user. This method generates the functional key from a string value through the following sequential process:
Note:
If the column on which you want to use the nGramkey
Cologne phonetics: a soundex phonetic algorithm optimized |
|
Value |
Set the algorithm value, where applicable. If you do not set a value for the algorithms which need one, the Job runs with a |
|
Post-Algorithm |
If required, select the relevant matching algorithm from the list:
Use default value (string): enables you to choose a
Add left position character: enables you to add a
Add right position character: enables you to add a |
|
Value |
Set the option value, where applicable. |
|
Show help |
Select this check box to display instructions on how to set algorithms/options |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component, along with the Spark Streaming component Palette it belongs to, appears This component is used as an intermediate step. You need to use the Spark Configuration tab in the This connection is effective on a per-Job basis. For further information about a Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.