tPigFilterRow
Applies filtering conditions on one or more specified columns, in a Pig process, in
order to split or filter data from a relation.
The tPigFilterRow filters or splits
the input flow in a Pig process based on conditions set on given column(s).
tPigFilterRow Standard properties
These properties are used to configure tPigFilterRow running in the Standard Job framework.
The Standard
tPigFilterRow component belongs to the Big Data and the Processing families.
The component in this framework is available when you are using one of the Talend solutions with Big Data.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Filter configuration |
Click the Add button beneath the Note that when the column to be used by a condition is of the Note:
This table disappears if you select Use |
|
Use advanced filter |
Select this check box to define advanced filter condition by |
Advanced settings
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is commonly used as an intermediate step in a Pig |
|
Prerequisites |
The Hadoop distribution must be properly installed, so as to guarantee the interaction
For further information about how to install a Hadoop distribution, see the manuals |
|
Limitation |
Knowledge of Pig scripts is required. |
Scenario: Filtering rows of data based on a condition and saving the result to a
local file
This scenario applies only to a Talend solution with Big Data.
This scenario describes a four-component Job that filters a list of customers to find
out customers from a particular country, and saves the result list to a local file.
Before the input data is filtered, duplicate entries are first removed from the list.
The input file contains three columns: Name,
Country, and Age, and it has some duplicate entries, as shown below:
|
1 2 3 4 5 6 7 8 9 10 11 |
Mario;PuertoRico;49 Mike;USA;22 Ricky;PuertoRico;37 Silvia;Spain;20 Billy;Canada;21 Ricky;PuertoRico;37 Romeo;UK;19 Natasha;Russia;25 Juan;Cuba;23 Bob;Jamaica;55 Mario;PuertoRico;49 |
Dropping and linking components
-
Drop the following components from the Palette to the design workspace: tPigLoad, tPigDistinct,
tPigFilterRow, and tPigStoreResult. -
Right-click tPigLoad, select Row > Pig
Combine from the contextual menu, and click tPigDistinct to link these two components. -
Repeat this operation to link tPigDistinct to tPigFilterRow, and tPigFilterRow to tPigStoreResult using Row >
Pig Combine connections to form a Pig
process.
Configuring the components
Loading the input data and removing duplicates
-
Double-click tPigLoad to open its
Basic settings view.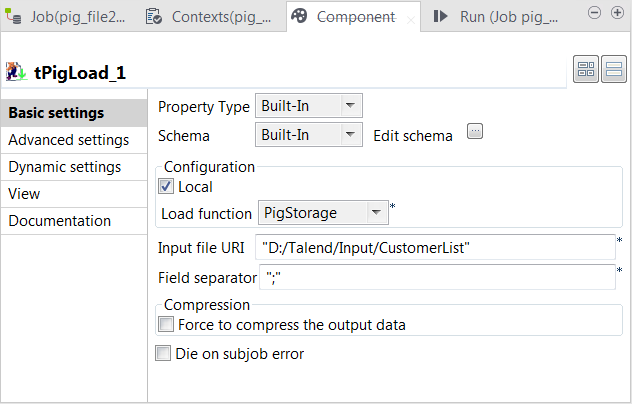
-
Click the […] button next to Edit schema to open the [Schema] dialog box.
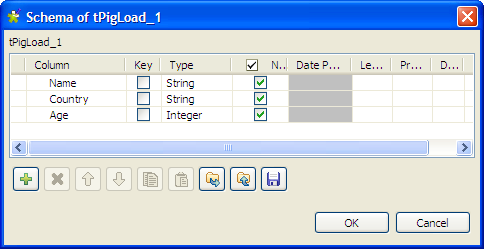
-
Click the [+] button to add three columns
according to the data structure of the input file: Name
(string), Country (string) and Age
(integer), and then click OK to save the
setting and close the dialog box. - Click Local in the Mode area.
-
Fill in the Input file URI field with the
full path to the input file. -
Select PigStorage from the Load function list, and leave rest of the
settings as they are. -
Double-click tPigDistinct to open its
Basic settings view, and click
Sync columns to make sure that the
input schema structure is correctly propagated from the preceding
component.This component will remove any duplicates from the data flow.
Configuring the filter
-
Double-click tPigFilterRow to open its
Basic settings view.
-
Click Sync columns to make sure that the
input schema structure is correctly propagated from the preceding
component. -
Select Use advanced filter and fill in
the Filter field with filter
expression:1"Country matches 'PuertoRico'"This filter expression selects rows of data that contains “PuertoRico” in
the Country column.
Configuring the file output
-
Double-click tPigStoreResult to open its
Basic settings view.
-
Click Sync columns to make sure that the
input schema structure is correctly propagated from the preceding
component. -
Fill in the Result file field with the
full path to the result file. -
If the target file already exists, select the Remove
result directory if exists check box. -
Select PigStorage from the Store function list, and leave rest of the
settings as they are.
Saving and executing the Job
- Press Ctrl+S to save your Job.
-
Press F6 or click the Run button on the Run tab to run the Job.
The result file contains the information of customers from the specified
country.