tTransliterate
Converts strings from many languages of the world to a standard set of characters
(Universal Coded Character Set, UCS).
This is a phonetic operation where the tTransliterate component attempts to create in UCS an equivalent of the
original string based on the sounds the string represents.
This component encodes text expressed in many of the world’s writing systems to readable
characters based on the repertoire of the Unicode Standard. This makes it easier for you
to recognize and interpret words from different languages than if the letters are left
in the original script. For further information about Unicode and Unicode Standard,
check Unicode and Unicode Standard.
Depending on the Talend solution you
are using, this component can be used in one, some or all of the following Job
frameworks:
-
Standard: see tTransliterate Standard properties.
The component in this framework is available when you have subscribed to one of
the Talend Platform products or Talend Data
Fabric. -
Spark Batch: see tTransliterate properties for Apache Spark Batch.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric. -
Spark Streaming: see tTransliterate properties for Apache Spark Streaming.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
tTransliterate Standard properties
These properties are used to configure tTransliterate running in the Standard Job framework.
The Standard
tTransliterate component belongs to the Data Quality family.
The component in this framework is available when you have subscribed to one of
the Talend Platform products or Talend Data
Fabric.
Basic settings
|
Schema |
A schema is a row description. It defines the number of fields (columns) to |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Edit Schema |
Click Edit schema to make changes to the schema.
|
|
Transliteration |
This table lists the columns defined in the schema of the tTransliterate component. Select the Transliterate check box |
Advanced settings
|
tStatCatcher Statistics |
Select this check box to collect log data at the component |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is an intermediary step. It requires an input and |
Scenario: Converting words from different languages to standard set of characters
This scenario applies only to a subscription-based Talend Platform solution or Talend Data Fabric.
This scenario describes a Job which uses:
-
the tFixedFlowInput component to generate the
data you want to process, -
the tTransliterate component to encode initial
data expressed in different languages to readable characters based on the repertoire
of the Unicode Standard, -
the tFileOutputExcel component to output
converted data in an .xls file.

Setting up the Job
-
Drop the following components from the Palette onto the design workspace: tFixedFlowInput, tTransliterate and
tFileOutputExcel. - Connect the three components together using the Main links.
Configuring the input component
-
Double-click tFixedFlowInput to open its
Basic settings view in the Component tab.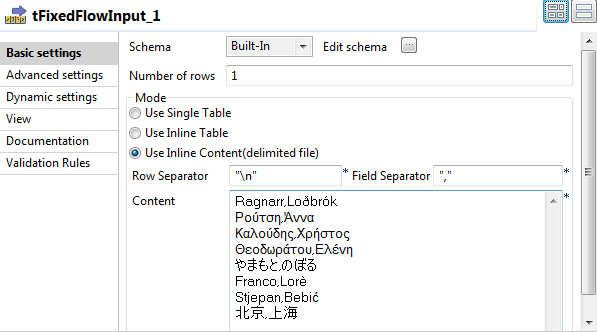
-
Create the schema through the Edit Schema
button.In the open dialog box, click the [+] button
and add the columns that will hold input data. For this example, add
column1, column2,
column3 and column4. The first two
columns hold names written in different languages. - Click OK.
-
In the Number of rows field, enter
1. - In the Mode area, select the Use Inline Content option.
-
In the Content table, enter the data you want
to convert to readable characters based on the Unicode Standard repertoire as
shown in the above image.
Transliterating data
-
Double-click tTransliterate to display the
Basic settings view and define the component
properties.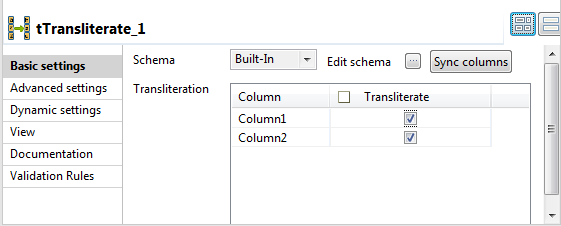
-
If required, click Sync columns to retrieve
the schema defined in the input component.In this example, only the first two columns are processed. You can click the
Edit schema button to open the schema dialog
box and see the input and output schemas.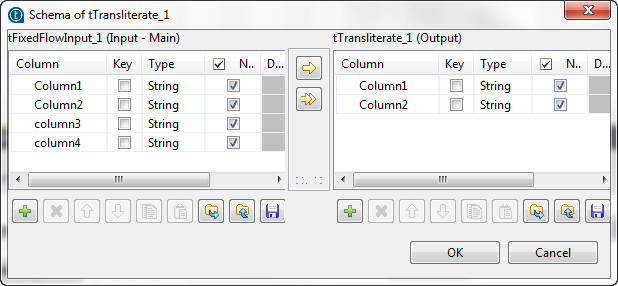
-
In the Transliteration table of the component
basic settings view, select the check boxes next to the columns you want to
convert to standard characters.
Configuring the output component and executing the Job
-
Double-click the tFileOutputExcel component
to display the Basic settings view and define
the component properties.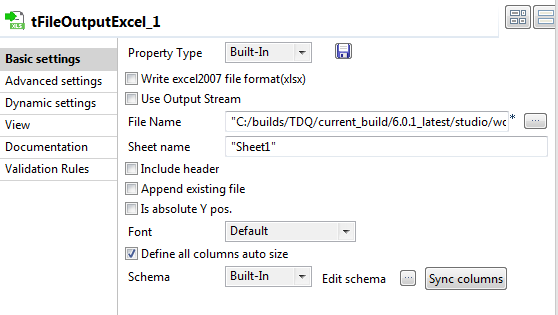
-
Set the destination file name as well as the sheet name and then select the
Define all columns auto size check box. -
Save your Job and press F6 to execute
it.The tTransliterate component encodes input
data to readable characters based on the repertoire of the Unicode
Standard. -
Right-click the output component and select Data
Viewer to display the transliterated data.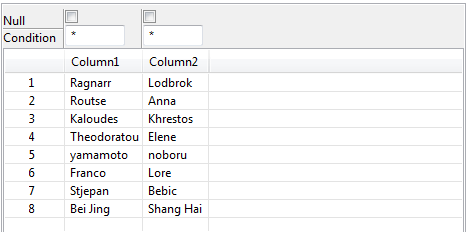 All names written in characters from diverse languages have been phonetically
All names written in characters from diverse languages have been phonetically
converted to a standard set of characters based on the Universal Coded Character
Set, UCS. For example, the names in the first and second rows in the below image
have been changed to Ragnarr,Lodbrok and to
Routse,Anna respectively.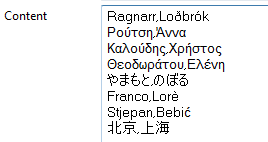
tTransliterate properties for Apache Spark Batch
These properties are used to configure tTransliterate running in the Spark Batch Job framework.
The Spark Batch
tTransliterate component belongs to the Data Quality family.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric.
Basic settings
|
Schema |
A schema is a row description. It defines the number of fields (columns) to |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Edit Schema |
Click Edit schema to make changes to the schema.
|
|
Transliteration |
This table lists the columns defined in the schema of the tTransliterate component. Select the Transliterate check box |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, appears only Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tTransliterate properties for Apache Spark Streaming
These properties are used to configure tTransliterate running in the Spark Streaming Job framework.
The Spark Streaming
tTransliterate component belongs to the Data Quality family.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
Basic settings
|
Schema |
A schema is a row description. It defines the number of fields (columns) to |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Edit Schema |
Click Edit schema to make changes to the schema.
|
|
Transliteration |
This table lists the columns defined in the schema of the tTransliterate component. Select the Transliterate check box |
Usage
|
Usage rule |
This component, along with the Spark Streaming component Palette it belongs to, appears This component is used as an intermediate step. You need to use the Spark Configuration tab in the This connection is effective on a per-Job basis. For further information about a Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.