tAvroInput
Extracts records from any given Avro format files for other components to process
the records.
tAvroInput parses Avro format files in
a given distributed file system and loads data to a data flow to pass the data to the
transformation component that follows.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
MapReduce: see tAvroInput MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tAvroInput properties for Apache Spark Batch
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tAvroInput properties for Apache Spark Streaming
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tAvroInput MapReduce properties (deprecated)
These properties are used to configure tAvroInput running in the MapReduce Job framework.
The MapReduce
tAvroInput component belongs to the MapReduce family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will read all of the files stored in that folder, for example,/user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property mapreduce.input.fileinputformat.input.dir.recursive to be If you want to specify more than one files or directories in this Note that you need |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a Once a Map/Reduce Job is opened in the workspace, tAvroInput as well as the MapReduce family appears in the Palette of the Studio. Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
Filtering Avro format employee data
This scenario applies only to subscription-based Talend products with Big
Data.
This scenario illustrates how to create a
Talend
Map/Reduce Job to
read, transform and write Avro format data by using Map/Reduce components. This Job
generates Map/Reduce code and directly runs in Hadoop. In addition, the Map bar in the workspace indicates that only a mapper will be
used in this Job and at runtime, it shows the progress of the Map computation.

Note that the
Talend
Map/Reduce components are available to
subscription-based Big Data users only and this scenario can be replicated only with
Map/Reduce components.
records virtually reading as follows but actually only visible as Avro format files:
|
1 2 3 4 5 6 7 8 9 10 11 |
1;Lyndon;Fillmore;21-05-2008 2;Ronald;McKinley;15-08-2008 3;Ulysses;Roosevelt;05-10-2008 4;Harry;Harrison;23-11-2007 5;Lyndon;Garfield;19-07-2007 6;James;Quincy;15-07-2008 7;Chester;Jackson;26-02-2008 8;Dwight;McKinley;16-07-2008 9;Jimmy;Johnson;23-12-2007 10;Herbert;Fillmore;03-04-2008 |
Before starting to replicate this scenario, ensure that you have appropriate rights
and permissions to access the Hadoop distribution to be used. Then proceed as
follows:
Linking the components
-
In the
Integration
perspective
of the Studio, create an empty Map/Reduce Job from the
Job Designs node in the Repository tree view.For further information about how to create a Map/Reduce Job, see
Talend Open Studio for Big Data Getting Started Guide
. -
Drop tAvroInput, tMap, tHDFSOutput and
tAvroOutput onto the workspace. -
Connect tAvroInput to tMap using the Row >
Main link. -
Do the same to connect tMap to tHDFSOutput and tAvroOutput, respectively. In doing it, you are prompted to
name each link. In this example, name the link to tHDFSOutput to out1 and
the link to tAvroOutput to reject.
Setting up Hadoop connection
-
Click Run to open its view and then click the
Hadoop Configuration tab to display its
view for configuring the Hadoop connection for this Job. -
From the Property type list,
select Built-in. If you have created the
connection to be used in Repository, then
select Repository and thus the Studio will
reuse that set of connection information for this Job. -
In the Version area, select the
Hadoop distribution to be used and its version.-
If you use Google Cloud Dataproc, see Google Cloud Dataproc.
-
If you cannot
find the Cloudera version to be used from this drop-down list, you can add your distribution
via some dynamic distribution settings in the Studio. -
If you cannot find from the list the distribution corresponding to
yours, select Custom so as to connect to a
Hadoop distribution not officially supported in the Studio. For a
step-by-step example about how to use this
Custom option, see Connecting to a custom Hadoop distribution.
-
-
In the Name node field, enter the location of
the master node, the NameNode, of the distribution to be used. For example,
hdfs://tal-qa113.talend.lan:8020.-
If you are using a MapR distribution, you can simply leave maprfs:/// as it is in this field; then the MapR
client will take care of the rest on the fly for creating the connection. The
MapR client must be properly installed. For further information about how to set
up a MapR client, see the following link in MapR’s documentation: http://doc.mapr.com/display/MapR/Setting+Up+the+Client -
If you are using WebHDFS, the location should be
webhdfs://masternode:portnumber; WebHDFS with SSL is not
supported yet.
-
-
In the Resource Manager field,
enter the location of the ResourceManager of your distribution. For example,
tal-qa114.talend.lan:8050.-
Then you can continue to set the following parameters depending on the
configuration of the Hadoop cluster to be used (if you leave the check
box of a parameter clear, then at runtime, the configuration about this
parameter in the Hadoop cluster to be used will be ignored):-
Select the Set resourcemanager
scheduler address check box and enter the Scheduler address in
the field that appears. -
Select the Set jobhistory
address check box and enter the location of the JobHistory
server of the Hadoop cluster to be used. This allows the metrics information of
the current Job to be stored in that JobHistory server. -
Select the Set staging
directory check box and enter this directory defined in your
Hadoop cluster for temporary files created by running programs. Typically, this
directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files
such as yarn-site.xml or mapred-site.xml of your distribution. -
Select the Use datanode hostname check box to allow the
Job to access datanodes via their hostnames. This actually sets the dfs.client.use.datanode.hostname
property to true. When connecting to a
S3N filesystem, you must select this check box.
-
-
-
If you are accessing the Hadoop cluster running
with Kerberos security, select this check box, then, enter the Kerberos
principal name for the NameNode in the field displayed. This enables you to use
your user name to authenticate against the credentials stored in Kerberos.
-
If this cluster is a MapR cluster of the version 5.0.0 or later, you can set the
MapR ticket authentication configuration in addition or as an alternative by following
the explanation in Connecting to a security-enabled MapR.Keep in mind that this configuration generates a new MapR security ticket for the username
defined in the Job in each execution. If you need to reuse an existing ticket issued for the
same username, leave both the Force MapR ticket
authentication check box and the Use Kerberos
authentication check box clear, and then MapR should be able to automatically
find that ticket on the fly.
In addition, since this component performs Map/Reduce computations, you
also need to authenticate the related services such as the Job history server and
the Resource manager or Jobtracker depending on your distribution in the
corresponding field. These principals can be found in the configuration files of
your distribution. For example, in a CDH4 distribution, the Resource manager
principal is set in the yarn-site.xml file and the Job history
principal in the mapred-site.xml file.If you need to use a Kerberos keytab file to log in, select Use a keytab to authenticate. A keytab file contains
pairs of Kerberos principals and encrypted keys. You need to enter the principal to
be used in the Principal field and the access
path to the keytab file itself in the Keytab
field. This keytab file must be stored in the machine in which your Job actually
runs, for example, on a Talend
Jobserver.Note that the user that executes a keytab-enabled Job is not necessarily
the one a principal designates but must have the right to read the keytab file being
used. For example, the user name you are using to execute a Job is user1 and the principal to be used is guest; in this
situation, ensure that user1 has the right to read the keytab
file to be used. -
-
In the User name field, enter the login user
name for your distribution. If you leave it empty, the user name of the machine
hosting the Studio will be used. -
In the Temp folder field, enter the path in
HDFS to the folder where you store the temporary files generated during
Map/Reduce computations. -
Leave the default value of the Path separator in
server as it is, unless you have changed the separator used by your
Hadoop distribution’s host machine for its PATH variable or in other words, that
separator is not a colon (:). In that situation, you must change this value to the
one you are using in that host.
-
Leave the Clear temporary folder check box
selected, unless you want to keep those temporary files. -
Leave the Compress intermediate map output to reduce
network traffic check box selected, so as to spend shorter time
to transfer the mapper task partitions to the multiple reducers.However, if the data transfer in the Job is negligible, it is recommended to
clear this check box to deactivate the compression step, because this
compression consumes extra CPU resources. -
If you need to use custom Hadoop properties, complete the Hadoop properties table with the property or
properties to be customized. Then at runtime, these changes will override the
corresponding default properties used by the Studio for its Hadoop
engine.For further information about the properties required by Hadoop, see Apache’s
Hadoop documentation on http://hadoop.apache.org, or
the documentation of the Hadoop distribution you need to use. -
If the HDFS transparent encryption has been enabled in your cluster, select
the Setup HDFS encryption configurations check
box and in the HDFS encryption key provider field
that is displayed, enter the location of the KMS proxy.
For further information about the HDFS transparent encryption and its KMS proxy, see Transparent Encryption in HDFS.
-
You can tune the map and reduce computations by
selecting the Set memory check box to set proper memory allocations
for the computations to be performed by the Hadoop system.The memory parameters to be set are Map (in Mb),
Reduce (in Mb) and ApplicationMaster (in Mb). These fields allow you to dynamically allocate
memory to the map and the reduce computations and the ApplicationMaster of YARN.For further information about the Resource Manager, its scheduler and the
ApplicationMaster, see YARN’s documentation such as http://hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/.For further information about how to determine YARN and MapReduce memory configuration
settings, see the documentation of the distribution you are using, such as the following
link provided by Hortonworks: http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.6.0/bk_installing_manually_book/content/rpm-chap1-11.html. -
If you are using Cloudera V5.5+, you can select the Use Cloudera Navigator check box to enable the Cloudera Navigator
of your distribution to trace your Job lineage to the component level, including the
schema changes between components.
With this option activated, you need to set the following parameters:
-
Username and Password: this is the credentials you use to connect to your Cloudera
Navigator. -
Cloudera Navigator URL : enter the location of the
Cloudera Navigator to be connected to. -
Cloudera Navigator Metadata URL: enter the location
of the Navigator Metadata. -
Activate the autocommit option: select this check box
to make Cloudera Navigator generate the lineage of the current Job at the end of the
execution of this Job.Since this option actually forces Cloudera Navigator to generate lineages of
all its available entities such as HDFS files and directories, Hive queries or Pig
scripts, it is not recommended for the production environment because it will slow the
Job. -
Kill the job if Cloudera Navigator fails: select this check
box to stop the execution of the Job when the connection to your Cloudera Navigator fails.Otherwise, leave it clear to allow your Job to continue to run.
-
Disable SSL validation: select this check box to
make your Job to connect to Cloudera Navigator without the SSL validation
process.This feature is meant to facilitate the test of your Job but is not
recommended to be used in a production cluster.
-
-
If you are using Hortonworks Data Platform V2.4.0 onwards and you have
installed Atlas in your cluster, you can select the Use
Atlas check box to enable Job lineage to the component level, including the
schema changes between components.
With this option activated, you need to set the following parameters:
-
Atlas URL: enter the location of the Atlas to be
connected to. It is often http://name_of_your_atlas_node:port -
Die on error: select this check box to stop the Job
execution when Atlas-related issues occur, such as connection issues to Atlas.Otherwise, leave it clear to allow your Job to continue to run.
In the Username and Password fields, enter the authentication information for access to
Atlas. -
Reading Avro data
-
Double-click tAvroInput to open its
Component view.
-
Click the

button next to Edit
schemato open the schema editor. -
Click the

button four times to add four rows and in the Column column, rename them to Id, FirstName, LastName and
Reg_date, respectively.
-
In the Type column, select Integer for Id
and Date for Reg_date. The date pattern used in this scenario is
dd-MM-yyyy. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Folder/File field, enter the path,
or browse to the source file you need the Job to read.
Configuring tAvroInput
-
Double-click tAvroInput to open its
Component view.
-
Click the
button next to Edit
schemato open the schema editor. -
Click the
button four times to add four rows and in the Column column, rename them to Id, FirstName, LastName and
Reg_date, respectively.
-
In the Type column, select Integer for Id
and Date for Reg_date. The date pattern used in this scenario is
dd-MM-yyyy. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Folder/File field, enter the path,
or browse to the source file you need the Job to read.
Transforming the data
-
Double-click tMap to open the Map Editor.

-
Drop the four columns of the input schema from the input side (left) into
each of the output flows of the output side (right), that is to say,
out1 and reject. This way the input flow and the output flows are
mapped. -
In the table representing the out1
flow, click
to display the filter editing area and enter the
following expression to select the employee records that were registered
before January 1st, 2008 (01-01-2008).
row1.Reg_date.before( new Date(108,0,1))
-
In the table representing the reject
flow, click
to display the property settings panel.
-
In the Value field of the Catch output reject row, click the
and select true in the
pop-up dialog box. This allows you to output the records rejected by the
out1 flow. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box.
Configuring tMap
-
Double-click tMap to open the Map Editor.
-
Drop the four columns of the input schema from the input side (left) into
each of the output flows of the output side (right), that is to say,
out1 and reject. This way the input flow and the output flows are
mapped. -
In the table representing the out1
flow, clickto display the filter editing area and enter the
following expression to select the employee records that were registered
before January 1st, 2008 (01-01-2008).
row1.Reg_date.before( new Date(108,0,1))
-
In the table representing the reject
flow, clickto display the property settings panel.
-
In the Value field of the Catch output reject row, click the
and select true in the
pop-up dialog box. This allows you to output the records rejected by the
out1 flow. -
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box.
Writing data in HDFS
Configuring the selected employee data
-
Double-click tHDFSOutput to open its
Component view.
-
In the Folder field, enter the path, or
browse to the folder you want to write the employee records registered
before January 1st, 2008. -
From the Type list, select the data
format for the records to be written. In this example, select Text file. -
From the Action list, select the
operation you need to perform on the file in question. If the file already
exists, select Overwrite; otherwise, select
Create. -
Select the Merge result to single file
check box and enter the path, or browse to the file you need to write the
merged output data in. -
If the file for the merged data exists, select the Override target file check box to overwrite that
file.
Configuring the rejected employee data
-
Double-click tAvroOutput to open its
Component view.
-
In the Folder field, enter the path, or
browse to the folder you want to write the employee records registered after
January 1st, 2008. -
From the Action list, select the
operation you need to perform on the folder in question. If the folder
already exists, select Overwrite;
otherwise, select Create.
Executing the Job
Then you can press F6 to run this Job and the
Map bar in the workspace shows the progress of
the Map computation.
Once done, you can check the results in the web console of the Hadoop distribution
being used.
The records in the out1 flow is outputted and
merged into one text file.
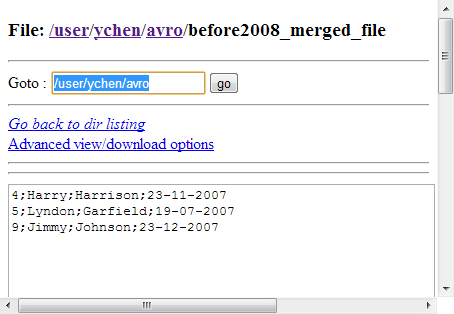
The records in the reject flow is outputted as
Avro format files.

If you need to obtain more execution information about this Job, you can check the
web console of the Jobtracker of the Hadoop distribution being used.
tAvroInput properties for Apache Spark Batch
These properties are used to configure tAvroInput running in the Spark Batch Job framework.
The Spark Batch
tAvroInput component belongs to the File family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more than one files or directories in this The button for browsing does not work with the Spark tHDFSConfiguration |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Use hierarchical mode |
Select this check box to map the binary (including hierarchical) Avro schema to the Once selecting it, you need set the following parameter(s):
|
Usage
|
Usage rule |
This component is used as a start component and requires an output This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tAvroInput properties for Apache Spark Streaming
These properties are used to configure tAvroInput running in the Spark Streaming Job framework.
The Spark Streaming
tAvroInput component belongs to the File family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more than one files or directories in this The button for browsing does not work with the Spark tHDFSConfiguration |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Use hierarchical mode |
Select this check box to map the binary (including hierarchical) Avro schema to the Once selecting it, you need set the following parameter(s):
|
Usage
|
Usage rule |
This component is used as a start component and requires an output link. This component is only used to provide the lookup flow (the right side of a join This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.