tBigQueryOutput
Transfers the data provided by its preceding component to Google
BigQuery.
This component writes the data it receives in a user-specified
directory and transfers the data to Google BigQuery via Google Cloud
Storage.
tBigQueryOutput Standard properties
These properties are used to configure tBigQueryOutput running in the Standard Job framework.
The Standard
tBigQueryOutput component belongs to the Big Data family.
The component in this framework is available in all Talend
products.
Basic settings
|
Schema and Edit schema |
A schema is a row description. It defines the number of fields
Click Edit
schema to make changes to the schema. Note: If you
make changes, the schema automatically becomes built-in.
This This |
|
|
|
Property type |
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Local filename |
Browse to, or enter the path to the file you want to write the |
|
Append |
Select this check box to add rows to the existing data in the |
| Authentication mode | Select the mode to be used to authenticate to your project.
|
| Service account credentials file | Enter the path to the credentials file created for the service account to be used. This file must be stored in the machine in which your Talend Job is actually launched and executed. For further information about how to create a Google service |
|
Client ID and Client secret |
Paste the client ID and the client secret, both created and viewable on the To enter the client secret, click the […] button next |
|
Project ID |
Paste the ID of the project hosting the Google BigQuery service you The ID of your project can be found in the URL of the Google |
|
Authorization code |
Paste the authorization code provided by Google for the access you are To obtain the authorization code, you need to execute the Job using this |
|
Dataset |
Enter the name of the dataset you need to transfer data to. |
|
Table |
Enter the name of the table you need to transfer data to. If this table does not exist, select the Create the table if it doesn’t exist check box. |
|
Action on data |
Select the action to be performed from the drop-down list when
|
|
Access key and Secret key |
Paste the authentication information obtained from Google for making To enter the secret key, click the […] button next to These keys can be consulted on the Interoperable Access tab view under the |
|
Bucket |
Enter the name of the bucket, the Google Cloud Storage |
|
File |
Enter the directory of the data stored on Google Cloud Storage If the data is not on Google Cloud Storage, this directory is Note that this file name must be identical with |
| Header |
Set values to ignore the header of the transferred data. For |
|
Die on error |
This check box is cleared by default, meaning to skip the row on |
Advanced settings
|
token properties File Name |
Enter the path to, or browse to the refresh token file you need to use. At the first Job execution using the Authorization With only the token file name entered, For further information about the refresh token, see the manual of Google |
|
Field Separator |
Enter character, string or regular expression to separate fields for the transferred |
| Drop table if exists |
Select the Drop table if exists check box to remove the table specified in the Table field, if this table already exists. |
| Create directory if not exists |
Select this check box to create the directory you defined in the |
|
Custom the flush buffer size |
Enter the number of rows to be processed before the memory is freed. |
|
Check disk space |
Select this check box to throw an exception during execution if |
|
Encoding |
Select the encoding from the list or select Custom |
|
tStatCatcher Statistics |
Select this check box to collect the log data at the component |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This is an output component used at the end of a Job. It receives This component automatically detects and |
Writing data in Google BigQuery
This scenario uses two components to write data in Google BigQuery.

Linking the components
-
In the
Integration
perspective
of
Talend Studio
,
create an empty Job, named WriteBigQuery for example, from the Job Designs node in the Repository tree view.For further information about how to create a Job, see the
Talend Studio
User
Guide. -
Drop tRowGenerator and tBigQueryOutput onto the workspace.
The tRowGenerator component generates the
data to be transferred to Google BigQuery in this scenario. In the
real-world case, you can use other components such as tMysqlInput or tMap in the
place of tRowGenerator to design a
sophisticated process to prepare your data to be transferred. -
Connect them using the Row > Main
link.
Preparing the data to be transferred
-
Double-click tRowGenerator to open its
Component view.
-
Click RowGenerator Editor to open the
editor. -
Click

three times to add three rows in the Schema table.
-
In the Column column, enter the name of
your choice for each of the new rows. For example, fname, lname and
States. -
In the Functions column, select TalendDataGenerator.getFirstName for the
fname row, TalendDataGenerator.getLastName for the lname row and TalendDataGenerator.getUsState for the States row. -
In the Number of Rows for RowGenerator
field, enter, for example, 100 to define
the number of rows to be generated. -
Click OK to validate these
changes.
Configuring the access to BigQuery and Cloud Storage
Building access to Cloud Storage
-
Double-click tBigQueryOutput to
open its Component view.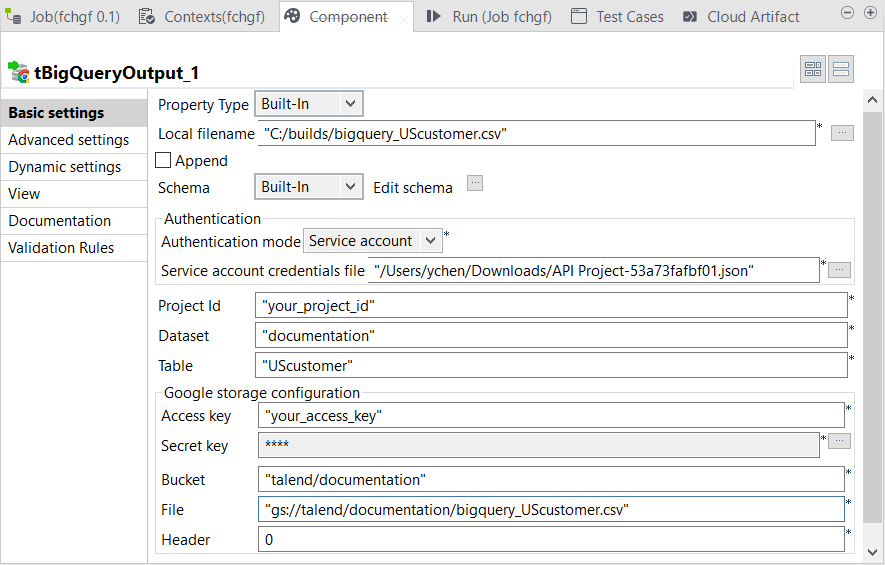
-
Click Sync columns to retrieve
the schema from its preceding component. -
In the Local filename field,
enter the directory where you need to create the file to be transferred to
BigQuery. -
Navigate to the Google APIs Console in your web browser to access the
Google project hosting the BigQuery and the Cloud Storage services you need to
use. -
Click Google Cloud Storage > Interoperable Access to open its
view. -
In Google storage configuration area of the
Component view, paste Access key, Access
secret from the Interoperable Access tab view to the corresponding fields,
respectively. -
In the Bucket field, enter the
path to the bucket you want to store the transferred data in. In this example, it is
talend/documentation
This bucket must exist in the directory in Cloud Storage
-
In the File field, enter the
directory where in Google Clould Storage you receive and create the file to be
transferred to BigQuery. In this example, it is gs://talend/documentation/biquery_UScustomer.csv. The file name must be the
same as the one you defined in the Local
filename field.Troubleshooting: if you encounter issues such as Unable to read source URI of the file stored in Google Cloud Storage,
check whether you put the same file name in these two fields. - Enter 0 in the Header field to ignore no rows in the transferred data.
Building access to BigQuery
-
In the Dataset field of the
Component view, enter the dataset you need to transfer data
in. In this scenario, it is documentation.This dataset must exist in BigQuery. The following figure shows the
dataset used by this scenario.
-
In the Table field, enter the
name of the table you need to write data in, for example, UScustomer. -
In the Action on data field,
select the action. In this example, select Truncate to empty the contents, if there are any, of target table and
to repopulate it with the transferred data. -
In the Authentication area, add the authentication
information. In most cases, the Service account mode is more
straight-forward and easy to handle.Authentication mode Description Service account Authenticate using a Google account that is associated with your Google
Cloud Platform project.When selecting this mode, the Service
account credentials file field is displayed. In this field,
enter the path to the credentials file created for the service account to be
used. This file must be stored in the machine in which your Talend Job is actually
launched and executed.For further information about how to create a
Google service account and obtain the credentials file, see Getting Started with Authentication
from the Google documentation.OAuth 2.0 Authenticate the access using OAuth credentials. When selecting this mode,
the parameters to be defined in the Basic settings view
are Client ID, Client secret and
Authorization code.- Navigate to the Google APIs Console in your web browser to access the
Google project hosting the BigQuery and the Cloud Storage services you
need to use. - Click the API Access tab to open its view.
- In the Component view of the Studio, paste Client
ID, Client secret and Project ID from the API Access tab view to the
corresponding fields, respectively.In the Advanced
settings tab, see the file path in the token
properties File Name field. The Studio automatically
generates this file during the first successful login and stores all
future successful logins in it. - In the Run view of the Studio,
click Run to execute this Job. The
execution will pause at a given moment to print out in the console the
URL address used to get the authorization code. - Navigate to this address in your web browser and copy the authorization
code displayed. - In the Component view of tBigQueryOutput, paste the authorization
code in the Authorization Code
field.
- Navigate to the Google APIs Console in your web browser to access the
-
If you have been using the OAuth 2.0 authentication mode, in
the Action on data field, select the action to be performed on
your data. In this example, select Truncate to empty the
contents, if there are any, of target table and to repopulate it with the transferred
data. If your are using Service account, ignore this
step.If the table to be used does not exist in BigQuery, select Create the table if it doesn’t exist.
Executing the Job
Once done, the Run view is opened automatically,
where you can check the execution result.

The data is transferred to Google BigQuery.

tBigQueryOutput properties for Apache Spark Batch
These properties are used to configure tBigQueryOutput running in the Spark Batch Job framework.
The Spark Batch
tBigQueryOutput component belongs to the Databases family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Dataset |
Enter the name of the dataset to which the table to be created or updated When you use Google BigQuery with Dataproc, in |
|
Table |
Enter the name of the table to be created or updated. |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Table operations |
Select the operation to be performed on the defined table:
|
|
Data operation |
Select the operation to be performed on the incoming data:
|
Usage
|
Usage rule |
This is an input component. It sends data extracted from Place a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
tBigQueryOutput properties for Apache Spark Streaming
These properties are used to configure tBigQueryOutput running in the Spark Streaming Job framework.
The Spark Streaming
tBigQueryOutput component belongs to the Databases family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Dataset |
Enter the name of the dataset to which the table to be created or updated When you use Google BigQuery with Dataproc, in |
|
Table |
Enter the name of the table to be created or updated. |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
Usage
|
Usage rule |
This component is used as an end component and Place a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |