tFileInputJSON
etc.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tFileInputJSON Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tFileInputJSON MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tFileInputJSON properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tFileInputJSON properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tFileInputJSON Standard properties
These properties are used to configure tFileInputJSON running in the Standard Job framework.
The Standard
tFileInputJSON component belongs to the Internet and the File families.
The component in this framework is available in all Talend
products.
Basic settings
|
Property Type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Schema and Edit schema |
A schema is a row description. It defines the number of fields
Click Edit
schema to make changes to the schema. Note: If you
make changes, the schema automatically becomes built-in.
|
|
Read By |
Select a way of extracting JSON data in the
|
|
Use Url |
Select this check box to retrieve data directly from the Web. |
|
URL |
Enter the URL path from which you will retrieve data. This field is available only when the Use Url check box is selected. |
|
Filename |
Specify the file from which you will retrieve data. This field is not visible if the Use Warning: Use absolute path (instead of relative path) for
this field to avoid possible errors. |
|
Loop Jsonpath query |
Enter the path pointing to the node within the JSON field, on which the loop is Note if you have selected Xpath from the Read |
|
Mapping |
Complete this table to map the columns defined in the schema to the
|
|
Die on error |
Select this check box to stop the execution of the Job when an |
Advanced settings
|
Advanced separator (for numbers) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.).
Thousands separator: define
Decimal separator: define separators |
|
Use the loop node as root |
Select this check box to use the loop node as the root for querying the file. The loop node is set in the Loop Json query text frame This check box is available only when JsonPath is |
|
Validate date |
Select this check box to check the date format strictly against the input schema. This check box is available only if the Read By |
|
Encoding |
Select the encoding type from the list or select Custom and define it manually. This field is compulsory for |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a Job |
Global Variables
|
Global Variables |
NB_LINE: the number of rows processed. This is an After
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is a start component of a Job and always needs an |
Extracting JSON data from a file using JSONPath without setting a loop
node
This scenario describes a two-component Job that extracts data from the JSON file
Store.json by specifying the complete JSON path for
each node of interest and displays the flat data extracted on the console.

The JSON file Store.json contains information about a
department store and the content of the file is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{"store": { "name": "Sunshine Department Store", "address": "Wangfujing Street", "goods": { "book": [ { "category": "Reference", "title": "Sayings of the Century", "author": "Nigel Rees", "price": 8.88 }, { "category": "Fiction", "title": "Sword of Honour", "author": "Evelyn Waugh", "price": 12.66 } ], "bicycle": { "type": "GIANT OCR2600", "color": "White", "price": 276 } } }} |
In the following example, we will extract the store name, the store address, and the
bicycle information from this file.
Adding and linking the components
-
Create a new Job and add a tFileInputJSON
component and a tLogRow component by typing
their names in the design workspace or dropping them from the Palette. -
Link the tFileInputJSON component to the
tLogRow component using a Row > Main
connection.
Configuring the components
-
Double-click the tFileInputJSON component to
open its Basic settings view.
-
Select JsonPath without loop from the
Read By drop-down list. With this option,
you need to specify the complete JSON path for each node of interest in the
JSONPath query fields of the Mapping table. -
Click the […] button next to Edit schema to open the schema editor.

-
Click the [+] button to add five columns,
store_name, store_address, bicycle_type,
and bicycle_color of String type, and bicycle_price of Double
type.Click OK to close the schema editor. In the
pop-up dialog box, click Yes to propagate the
schema to the subsequent component. -
In the Filename field, specify the path to
the JSON file that contains the data to be extracted. In this example, it is
“E:/Store.json”. -
In the Mapping table, the Column fields are automatically filled with the
schema columns you have defined.In the JSONPath query fields, enter the
JSONPath query expressions between double quotation marks to specify the nodes
that hold the desired data.-
For the columns store_name and
store_address, enter the JSONPath
query expressions “$.store.name” and
“$.store.address” relative to the
nodes name and address respectively. -
For the columns bicycle_type,
bicycle_color, and bicycle_price, enter the JSONPath query
expressions “$.store.goods.bicycle.type”, “$.store.goods.bicycle.color”, and “$.store.goods.bicycle.price” relative to
the child nodes type, color, and price of the bicycle
node respectively.
-
-
Double-click the tLogRow component to display
its Basic settings view.
-
In the Mode area, select Table (print values in cells of a table) for better
readability of the result.
Executing the Job
- Press Ctrl+S to save the Job.
-
Press F6 to execute the Job.
 As shown above, the store name, the store address, and the bicycle information
As shown above, the store name, the store address, and the bicycle information
are extracted from the source JSON data and displayed in a flat table on the
console.
Extracting JSON data from a file using JSONPath
extracts data under the book array of the JSON file
Store.json by specifying a loop node and the relative
JSON path for each node of interest, and then displays the flat data extracted on the
console.
Procedure
-
In the Studio, open the Job used in Extracting JSON data from a file using JSONPath without setting a loop node to display it in
the design workspace. -
Double-click the tFileInputJSON component to open
its Basic settings view.
- Select JsonPath from the Read By drop-down list.
-
In the Loop Json query field, enter the JSONPath
query expression between double quotation marks to specify the node on which the
loop is based. In this example, it is “$.store.goods.book[*]”. -
Click the […] button next to Edit schema to open the schema editor.
 Select the five columns added previously and click the x button to remove all of them.Click the [+] button to add four columns,
Select the five columns added previously and click the x button to remove all of them.Click the [+] button to add four columns,
book_title, book_category, and book_author of
String type, and book_price of Double type.Click OK to close the schema editor. In the
pop-up dialog box, click Yes to propagate the
schema to the subsequent component. -
In the Json query fields of the Mapping table, enter the JSONPath query expressions between double
quotation marks to specify the nodes that hold the desired data. In this example,
enter the JSONPath query expressions “title”,
“category”, “author”, and “price” relative to
the four child nodes of the book node
respectively. - Press Ctrl+S to save the Job.
-
Press F6 to execute the Job.
 As shown above, the book information is extracted from the source JSON data and displayed
As shown above, the book information is extracted from the source JSON data and displayed
in a flat table on the console.
Extracting JSON data from a file using XPath
scenario extracts the store name and the book information from the JSON file Store.json using XPath queries and displays the flat data
extracted on the console.
Procedure
-
In the Studio, open the Job used in Extracting JSON data from a file using JSONPath without setting a loop node to display it in
the design workspace. -
Double-click the tFileInputJSON component to open
its Basic settings view.
-
Select Xpath from the Read
By drop-down list. -
Click the […] button next to Edit schema to open the schema editor.
 Select the five columns added previously and click the x button to remove all of them.Click the [+] button to add five columns,
Select the five columns added previously and click the x button to remove all of them.Click the [+] button to add five columns,
store_name, book_title, book_category, and
book_author of String type, and book_price of
Double type.Click OK to close the schema editor. In the
pop-up dialog box, click Yes to propagate the
schema to the subsequent component. -
In the Loop XPath query field, enter the XPath
query expression between double quotation marks to specify the node on which the
loop is based. In this example, it is “/store/goods/book”. -
In the XPath query fields of the Mapping table, enter the XPath query expressions between
double quotation marks to specify the nodes that hold the desired data.-
For the column store_name, enter the
XPath query “../../name” relative to the
name node. -
For the columns book_title, book_category, book_author, and book_price, enter the XPath query expressions “title”, “category”, “author”, and
“price” relative to the four child
nodes of the book node
respectively.
-
- Press Ctrl+S to save the Job.
-
Press F6 to execute the Job.
 As shown above, the store name and the book information are extracted from the
As shown above, the store name and the book information are extracted from the
source JSON data and displayed in a flat table on the console.
Extracting JSON data from a URL
In this scenario, tFileInputJSON retrieves data of the
friends node from the JSON file facebook.json on the Web that contains the data of a Facebook
user and tExtractJSONFields extracts the data from the
friends node for flat data output.

The JSON file facebook.json is deployed on the Tomcat
server, specifically, located in the folder <tomcat
path>/webapps/docs, and the content of the file is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
{"user": { "id": "9999912398", "name": "Kelly Clarkson", "friends": [ { "name": "Tom Cruise", "id": "55555555555555", "likes": {"data": [ { "category": "Movie", "name": "The Shawshank Redemption", "id": "103636093053996", "created_time": "2012-11-20T15:52:07+0000" }, { "category": "Community", "name": "Positiveretribution", "id": "471389562899413", "created_time": "2012-12-16T21:13:26+0000" } ]} }, { "name": "Tom Hanks", "id": "88888888888888", "likes": {"data": [ { "category": "Journalist", "name": "Janelle Wang", "id": "136009823148851", "created_time": "2013-01-01T08:22:17+0000" }, { "category": "Tv show", "name": "Now With Alex Wagner", "id": "305948749433410", "created_time": "2012-11-20T06:14:10+0000" } ]} } ] }} |
Adding and linking the components
-
Create a new Job and add a tFileInputJSON
component, a tExtractJSONFields component, and
two tLogRow components by typing their names in
the design workspace or dropping them from the Palette. -
Link the tFileInputJSON component to the
first tLogRow component using a Row > Main
connection. -
Link the first tLogRow component to the
tExtractJSONFields component using a
Row > Main connection. -
Link the tExtractJSONFields component to the
second tLogRow component using a Row > Main
connection.
Configuring the components
-
Double-click the tFileInputJSON component to
open its Basic settings view.
-
Select JsonPath without
loop from the Read By
drop-down list. Then select the Use Url
check box and in the URL field displayed
enter the URL of the file facebook.json from which the data
will be retrieved. In this example, it is
http://localhost:8080/docs/facebook.json. -
Click the […] button
next to Edit schema and in the Schema dialog box define the schema by adding one
column friends of String type. Click OK to close the
Click OK to close the
dialog box and accept the propogation prompted by the pop-up dialog box. -
In the Mapping table,
enter the JSONPath query "$.user.friends[*]" next to the
friends column to retrieve the entire
friends node from the source file. -
Double-click tExtractJSONFields to open its
Basic settings view.
- Select Xpath from the Read By drop-down list.
-
In the Loop XPath query
field, enter the XPath expression between double quotation marks to specify the
node on which the loop is based. In this example, it is
"/likes/data". -
Click the […] button
next to Edit schema and in the Schema dialog box define the schema by adding five
columns of String type,
id, name,
like_id, like_name, and
like_category, which will hold the data of relevant nodes under the JSON field
friends.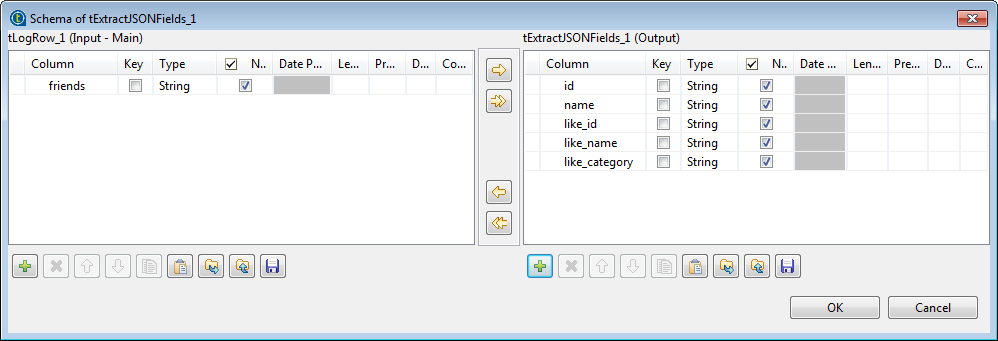 Click OK to close the
Click OK to close the
dialog box and accept the propogation prompted by the pop-up dialog box. -
In the XPath query
fields of the Mapping table, type in the
XPath query expressions between double quotation marks to specify the JSON nodes
that hold the desired data. In this example:-
"../../id" (querying the
“/friends/id” node) for the column id, -
"../../name" (querying the
“/friends/name” node) for the column name, -
"id" for the column
like_id, -
"name" for the column
like_name, and -
"category" for the column
like_category.
-
-
Double-click the second tLogRow component to
open its Basic settings view. In the Mode area, select Table (print values in cells of a table) for better
In the Mode area, select Table (print values in cells of a table) for better
readability of the result.
Executing the Job
- Press Ctrl + S to save the Job.
-
Click F6 to execute the Job.
 As shown above, the friends data in the JSON file specified using the URL is
As shown above, the friends data in the JSON file specified using the URL is
extracted and then the data from the node friends is extracted and displayed in a flat table.
tFileInputJSON MapReduce properties (deprecated)
These properties are used to configure tFileInputJSON running in the MapReduce Job framework.
The MapReduce
tFileInputJSON component belongs to the MapReduce family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The fields that come after are pre-filled in using the fetched For further information about the File |
|
|
Schema et Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Read by |
Select a way of extracting the JSON data in the file.
|
|
Folder/File |
Enter the path to the file or folder on HDFS from which the data If the path you entered points to a folder, all files stored in If the file to be read is a compressed one, enter the file name
Note that you need |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
|
Loop Jsonpath query |
Enter the path pointing to the node within the JSON field, on which the loop is Note if you have selected Xpath from the Read |
|
Mapping |
Complete this table to map the columns defined in the schema to the
|
Advanced settings
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). |
|
Validate date |
Select this check box to check the date format strictly against the input schema. |
|
Encoding |
Select the encoding from the list or select Custom and define it manually. |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a Once a Map/Reduce Job is opened in the workspace, tFileInputJSON as well as the MapReduce For further information about a Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
|
Prerequisites |
The Hadoop distribution must be properly installed, so as to guarantee the interaction
For further information about how to install a Hadoop distribution, see the manuals |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tFileInputJSON properties for Apache Spark Batch
These properties are used to configure tFileInputJSON running in the Spark Batch Job framework.
The Spark Batch
tFileInputJSON component belongs to the File family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The fields that come after are pre-filled in using the fetched For further information about the File |
|
|
Schema et Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Read by |
Select a way of extracting the JSON data in the file.
|
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you entered points to a folder, all files stored in If the file to be read is a compressed one, enter the file name
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
|
Loop Jsonpath query |
Enter the path pointing to the node within the JSON field, on which the loop is Note if you have selected Xpath from the Read |
|
Mapping |
Complete this table to map the columns defined in the schema to the
|
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). |
|
Encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. |
Usage
|
Usage rule |
This component is used as a start component and requires an output This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tFileInputJSON properties for Apache Spark Streaming
These properties are used to configure tFileInputJSON running in the Spark Streaming Job framework.
The Spark Streaming
tFileInputJSON component belongs to the File family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The fields that come after are pre-filled in using the fetched For further information about the File |
|
|
Schema et Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
|
Read by |
Select a way of extracting the JSON data in the file.
|
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you entered points to a folder, all files stored in If the file to be read is a compressed one, enter the file name
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
|
Loop Jsonpath query |
Enter the path pointing to the node within the JSON field, on which the loop is Note if you have selected Xpath from the Read |
|
Mapping |
Complete this table to map the columns defined in the schema to the
|
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). |
|
Encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. |
Usage
|
Usage rule |
This component is used as a start component and requires an output link. This component is only used to provide the lookup flow (the right side of a join This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.