tFlowToIterate
global variables.
tFlowToIterate Standard properties
These properties are used to configure tFlowToIterate running in the Standard Job framework.
The Standard
tFlowToIterate component belongs to the Orchestration family.
The component in this framework is available in all Talend
products.
Basic
settings
|
Use the default (key, value) in global |
When selected, the system uses the default value |
|
Customize |
key: Type in a |
|
|
value: Click in |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the
NB_LINE: the number of rows processed. This is an After
CURRENT_ITERATION: the sequence number of the current A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
You cannot use this |
|
Connections |
Outgoing links (from this component to another): Row: Iterate
Trigger: Run if; On Component Ok; Incoming links (from one component to this one): Row: Main; For further information regarding connections, see |
Transforming data flow to a list
The following scenario describes a Job that reads a list of files from a defined input
file, iterates on each of the files and displays their content row by row on the
Run console.
Setting up the Job
- Drop the following components from the Palette onto the design workspace: two tFileInputDelimited components, a tFlowToIterate, and a tLogRow.
-
Connect the first tFileInputDelimited to
tFlowToIterate using a Row > Main link,
tFlowToIterate to the second tFileInputDelimited using an Iterate link, and the second tFileInputDelimited to tLogRow using a Row >
Main link.
Configuring the Components
- Double-click the first tFileInputDelimited to display its Basic settings view.
-
Click the […] button next to the
File Name field to select the path to
the input file.Note:The File Name field is
mandatory. The input file used in this scenario is
The input file used in this scenario is
Customers.txt. It is a text file that contains a list
of names of three other simple text files: Name.txt,
E-mail.txt and Address.txt.
The first text file, Name.txt, is made of one column
holding customers’ names. The second text file,
E-mail.txt, is made of one column holding
customers’ e-mail addresses. The third text file,
Address.txt, is made of one column holding
customers’ postal addresses.Fill in all other fields as needed. For more information, see tFileInputDelimited Standard properties. In this scenario, the header and the footer
are not set and there is no limit for the number of processed rows. -
Click Edit schema to describe the data
structure of this input file. In this scenario, the schema is made of one
column, FileName.

-
Double-click tFlowToIterate to display
its Basic settings view. Click the plus button to add new parameter lines and define your
Click the plus button to add new parameter lines and define your
variables, and click in the key cell to
enter the variable name as desired. In this scenario, one variable is
defined:"Name_of_File".Alternatively, you can select the Use the default
(key, value) in global variables check box to use the default
in global variables. -
Double-click the second tFileInputDelimited to display its Basic settings view.
 In the File name field, enter the
In the File name field, enter the
directory of the files to be read, and then press Ctrl+Space to select the global variable “Name_of_File”. In this scenario, the syntax is
as follows:1"C:/scenario/flow_to_iterate/"+((String)globalMap.get("Name_of_File"))Click Edit schema to define the schema
column name. In this scenario, it is RowContent.Fill in all other fields as needed. For more information, see tFileInputDelimited Standard properties. -
In the design workspace, select the last component, tLogRow, and click the Component tab to define its basic settings.
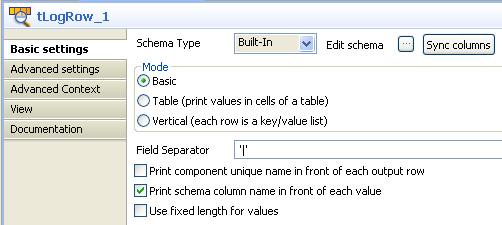 Define your settings as needed. For more information, see tLogRow Standard properties.
Define your settings as needed. For more information, see tLogRow Standard properties.
Saving and executing the Job
- Save your Job by pressing Ctrl+S.
-
Execute the Job by pressing F6 or
clicking Run on the Run tab.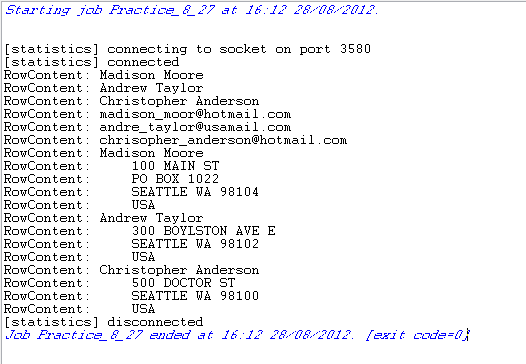
Customers’ names, customers’ e-mails, and customers’ postal addresses appear on
the console preceded by the schema column name.