tFuzzyMatch
outputs the main flow data displaying the distance.
tFuzzyMatch Standard properties
These properties are used to configure tFuzzyMatch running in the Standard Job framework.
The Standard
tFuzzyMatch component belongs to the Data Quality family.
The component in this framework is available in all Talend
products.
Basic settings
|
Schema and Edit |
A schema is a row description, it defines the number of fields to Two read-only columns, Value and Match are added to the output |
|
|
Built-in: The schema will be |
|
|
Repository: The schema already |
|
Matching type |
Select the relevant matching algorithm among:
Levenshtein: Based on the edit
Metaphone: Based on a
Double Metaphone: a new |
|
Min distance |
(Levenshtein only) Set the minimum number of changes allowed to |
|
Max distance |
(Levenshtein only) Set the maximum number of changes allowed to |
|
Matching column |
Select the column of the main flow that needs to be checked |
|
Unique matching |
Select this check box if you want to get the best match possible, |
|
Matching item separator |
In case several matches are available, all of them are displayed |
Advanced settings
|
tStatCatcher Statistics |
Select this check box to collect log data at the component level. |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is not startable (green background) and it requires |
Checking the Levenshtein distance of 0 in first names
This scenario describes a four-component Job aiming at checking the edit distance
between the First Name column of an input file with the data of the
reference input file. The output of this Levenshtein type check is displayed along with
the content of the main flow on a table
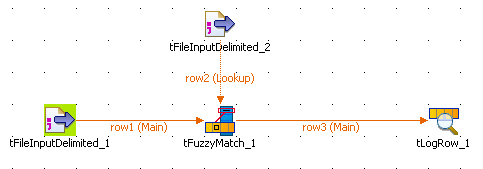
Setting up the Job
- Drag and drop the following components from the Palette to the design workspace: tFileInputDelimited (x2), tFuzzyMatch, tLogRow.
-
Link the first tFileInputDelimited
component to the tFuzzyMatch component
using a Row > Main connection. -
Link the second tFileInputDelimited
component to the tFuzzyMatch using a
Row > Main connection (which appears as a Lookup row on the design workspace). -
Link the tFuzzyMatch component to the
standard output tLogRow using a Row > Main
connection.
Configuring the components
-
Define the first tFileInputDelimited in
its Basic settings view. Browse the system
to the input file to be analyzed. -
Define the schema of the component. In this example, the input schema has
two columns, firstname and gender. -
Define the second tFileInputDelimited
component the same way.Warning:Make sure the reference column is set as key column in the
schema of the lookup flow.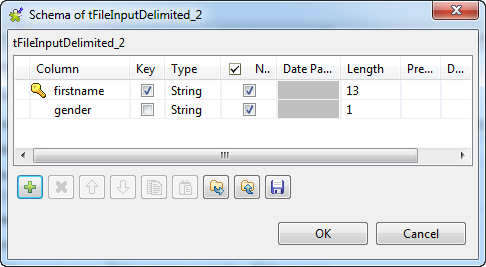
-
Double-click the tFuzzyMatch component to
open its Basic settings view, and check its
schema.The Schema should match the Main input flow schema in order for the main flow
to be checked against the reference. Note that two columns, Value and
Note that two columns, Value and
Matching, are added to the output
schema. These are standard matching information and are read-only. -
Select the method to be used to check the incoming data. In this scenario,
Levenshtein is the Matching
type to be used. -
Then set the distance. In this method, the distance is the number of char
changes (insertion, deletion or substitution) that needs to be carried out
in order for the entry to fully match the reference. In this use case, we set both the minimum distance and the maximum
In this use case, we set both the minimum distance and the maximum
distance to 0. This means only the exact
matches will be output. -
Also, clear the Case sensitive check
box. -
Check that the matching column and look up column are correctly
selected. - Leave the other parameters as default.
Executing the Job
Job.
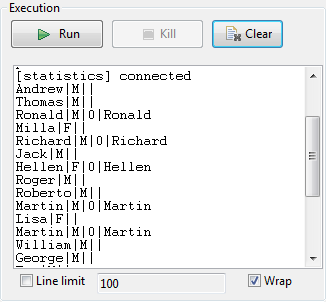
As the edit distance has been set to 0 (min and max), the output shows the result
of a regular join between the main flow and the lookup (reference) flow, hence only
full matches with Value of 0 are displayed.
A more obvious example is with a minimum distance of 1 and a maximum distance of
2, see Procedure
Checking the Levenshtein distance of 1 or 2 in first names
distance settings in the tFuzzyMatch component are
modified, which will change the output displayed.
Procedure
-
In the Component view of the tFuzzyMatch, change the minimum distance from
0 to 1. This excludes straight away the exact matches (which would show a
distance of 0). -
Change also the maximum distance to 2. The
output will provide all matching entries showing a discrepancy of 2 characters
at most. No other changes are required.
No other changes are required. -
Make sure the Matching item separator is
defined, as several references might be matching the main flow entry. -
Save the new Job and press F6 to run
it.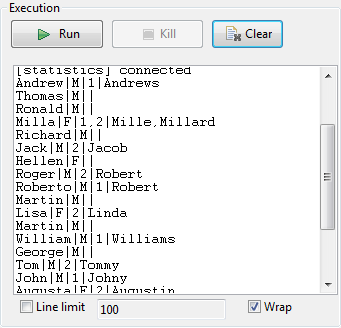 As the edit distance has been set to 2,
As the edit distance has been set to 2,
some entries of the main flow match more than one reference entry.
You can also use another method, the metaphone, to assess the distance between the
main flow and the reference, which will be described in the next scenario.
Checking the Metaphonic distance in first name
Procedure
-
Change the Matching type to Metaphone. There is no minimum nor maximum distance
to set as the matching method is based on the discrepancies with the phonetics
of the reference.
-
Save the Job and press F6. The phonetics
value is displayed along with the possible matches.