tJava
Extends the functionalities of a Talend Job using custom Java
commands.
tJava enables you to enter personalized
code in order to integrate it in Talend program. You can execute
this code only once.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tJava Standard properties.
The component in this framework is available in all Talend
products. -
Spark Batch: see tJava properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tJava properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tJava Standard properties
These properties are used to configure tJava running in the Standard Job framework.
The Standard
tJava component belongs to the Custom Code family.
The component in this framework is available in all Talend
products.
Basic settings
|
Code |
Type in the Java code you want to execute according to the task For a complete Java reference, check http://docs.oracle.com/javaee/6/api/ Note:
This component offers the advantage of the dynamic schema Note: If your custom Java code references
org.talend.transform.runtime.api.ExecutionStatus, change itto org.talend.transform.runtime.common.MapExecutionStatus. |
Advanced settings
|
Import |
Enter the Java code to import, if necessary, external libraries |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a Job |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is generally used as a one-component subJob. |
|
Limitation |
You should know Java language. |
Printing out a variable content
The following scenario is a simple demo of the extended application of the
tJava component. The Job aims at printing out the
number of lines being processed using a Java command and the global variable provided in
Talend Studio
.
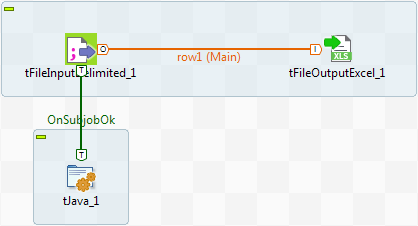
Setting up the Job
- Select and drop the following components from the Palette onto the design workspace: tFileInputDelimited, tFileOutputExcel, tJava.
-
Connect the tFileInputDelimited to the
tFileOutputExcel using a Row Main connection. The content from a delimited
txt file will be passed on through the connection to an xls-type of file
without further transformation. -
Then connect the tFileInputDelimited
component to the tJava component using a
Trigger > On
Subjob Ok link. This link sets a sequence ordering tJava to be executed at the end of the main
process.
Configuring the input component
-
Set the Basic settings of the tFileInputDelimited component.

-
Define the path to the input file in the File
name field.The input file used in this example is a simple text file made of two
columns: Names and their respective
Emails. -
Click the Edit Schema button, and set the
two-column schema. Then click OK to close
the dialog box.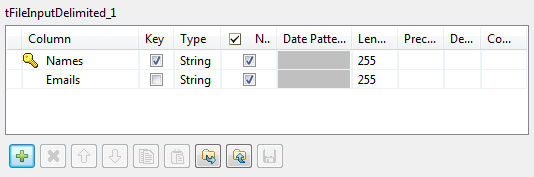
-
When prompted, click OK to accept the
propagation, so that the tFileOutputExcel
component gets automatically set with the input schema.
Configuring the output component
Set the output file to receive the input content without changes. If the file does
not exist already, it will get created.

In this example, the Sheet name is
Email and the Include
Header box is selected.
Configuring the tJava component
-
Then select the tJava component to set
the Java command to execute.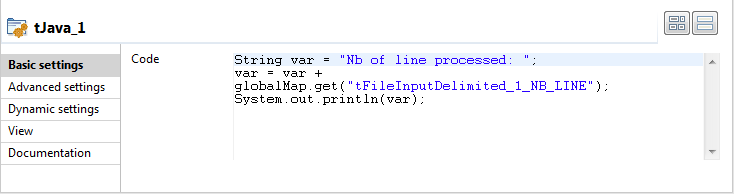
-
In the Code area, type in the following
command:123String var = "Nb of line processed: ";var = var + globalMap.get("tFileInputDelimited_1_NB_LINE");System.out.println(var);In this use case, we use the NB_Line variable. To
access the global variable list, press Ctrl + Space bar on your keyboard and
select the relevant global parameter.
Executing the Job
-
Press Ctrl+S to save
your Job. -
Press F6 to execute
it.
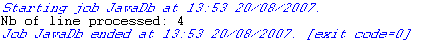
The content gets passed on to the Excel file defined and the Number of lines
processed are displayed on the Run
console.
tJava properties for Apache Spark Batch
These properties are used to configure tJava running in the Spark Batch Job framework.
The Spark Batch
tJava component belongs to the Custom Code family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Schema et Edit Schema |
A schema is a row description. It defines the number of fields Click Edit
Note that if the input value of any non-nullable primitive field is |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Code |
Type in the Java code you want to execute to process the incoming RDD You need to leverage the schema, the link and the component name to For more detailed instructions, see the default comment provided in For further information about Spark’s Java API, see Apache’s Spark |
Advanced settings
|
Classes |
Define the classes that you need to use in the code written in the Code field in the Basic settings It is recommended to define new classes in this field, instead of in the Code field, so as to avoid |
|
Import |
Enter the Java code to import, if necessary, external libraries |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. |
||||
| Code example | In the Code field of the Basic settings view, enter the following code to create an output RDD by using custom transformations on the input RDD. mapInToOut is a class to be defined in theClasses field in the Advanced settings view.
In
the Classes field of the Advanced settings view, enter the following code to define the mapInToOutclass:
|
||||
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
||||
|
Limitation |
Knowledge of Spark and Java language is required. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tJava properties for Apache Spark Streaming
These properties are used to configure tJava running in the Spark Streaming Job framework.
The Spark Streaming
tJava component belongs to the Custom Code family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Schema et Edit Schema |
A schema is a row description. It defines the number of fields Click Edit
Note that if the input value of any non-nullable primitive field is |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Code |
Type in the Java code you want to execute to process the incoming RDD You need to leverage the schema, the link and the component name to For more detailed instructions, see the default comment provided in For further information about Spark Java API, see |
Advanced settings
|
Classes |
Define the classes that you need to use in the code written in the Code field in the Basic settings It is recommended to define new classes in this field, instead of in the Code field, so as to avoid |
|
Import |
Enter the Java code to import, if necessary, external libraries |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. |
||||
| Code example | In the Code field of the Basic settings view, enter the following code to create an output RDD by using custom transformations on the input RDD. mapInToOut is a class to be defined in theClasses field in the Advanced settings view.
In
the Classes field of the Advanced settings view, enter the following code to define the mapInToOutclass:
|
||||
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.