tMap
Transforms and routes data from single or multiple sources to single or multiple
destinations.
tMap is an advanced component, which integrates itself as plugin to
Talend Studio.
There is no order among the output flows of
tMap. To make the output flows to be executed one by one,
you can output them to temporary files or memory, and then read and insert them into
files or databases using different subjobs linked by Trigger > OnSubjobOK connections.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tMap Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tMap MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch:
see tMap properties for Apache Spark Batch.The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming:
see tMap properties for Apache Spark Streaming.This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tMap Standard properties
These properties are used to configure tMap running in the Standard Job framework.
The Standard
tMap component belongs to the Processing family.
The component in this framework is available in all Talend
products.
Basic settings
|
Map editor |
It allows you to define the tMap If needed, click the button at the top of the input area to open the
This This |
|
Mapping links display as |
Auto: the default setting is curves Curves: the mapping display as curves
Lines: the mapping displays as straight |
| Temp data directory path | Enter the path where you want to store the temporary data generated for lookup loading. For more information on this folder, see Talend Studio User Guide. |
|
Preview |
The preview is an instant shot of the Mapper data. It becomes |

Advanced settings
| Max buffer size (nb of rows) | Type in the size of physical memory, in number of rows, you want to allocate to processed data. |
| Ignore trailing zeros for BigDecimal | Select this check box to ignore trailing zeros for BigDecimal data. |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the Job |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Possible uses are from a simple reorganization of fields to the most |
|
Limitation |
The use of tMap supposes minimum Java This component is a junction step, and for this reason cannot be a |
Mapping data using a filter and a simple explicit join
The Job described below aims at reading data from a csv file with its schema stored in
the Repository, looking up at a reference file, the schema of which is also stored in
the Repository, then extracting data from these two files based on a defined filter to
an output file and reject files.
Linking the components
-
Drop two tFileInputDelimited components,
tMap and three tFileOutputDelimited components onto the design workspace.
-
Rename the two tFileInputDelimited
components as Cars and Owners,
either by double-clicking the label in the design workspace or via the
View tab of the Component view. -
Connect the two input components to tMap
using Row > Main connections and label the connections as
Cars_data and Owners_data
respectively. -
Connect tMap to the three output
components using Row > New Output (Main) connections and name the output
connections as Insured, Reject_NoInsur and Reject_OwnerID
respectively.
Configuring the components
-
Double-click the tFileInputDelimited
component labelled Cars to display its Basic settings view.
-
Select Repository from the Property type list and select the component’s
schema, cars in this scenario, from the Repository Content dialog box. The rest fields
are automatically filled. -
Double-click the component labelled Owners and repeat
the setting operation. Select the appropriate metadata entry,
owners in this scenario.Note:In this scenario, the input schemas are stored in the Metadata node of the Repository tree view for easy retrieval. For further
information regarding metadata creation in the Repository, see
Talend Studio User Guide. -
Double-click the tMap component to open
the Map Editor.Note that the input area is already filled with the defined input tables
and that the top table is the main input table, and the respective row
connection labels are displayed on the top bar of the table. -
Create a join between the two tables on the ID_Owner
column by simply dropping the ID_Owner column from the
Cars_data table onto the
ID_Owner column in the
Owners_data table. -
Define this join as an inner join by clicking the tMap settings button, clicking in the Value field for Join Model,
clicking the small button that appears in the field, and selecting Inner Join from the Options dialog box.
-
Drag all the columns of the Cars_data table to the
Insured table. -
Drag the ID_Owner,
Registration, and ID_Reseller
columns of the Cars_data table and the
Name column of the Owners_data
table to the Reject_NoInsur table. -
Drag all the columns of the Cars_data table to the
Reject_OwnerID table.For more information regarding data mapping, see
Talend Studio
User Guide. -
Click the plus arrow button at the top of the Insured
table to add a filter row.Drag the ID_Insurance column of the
Owners_data table to the filter condition area and
enter the formula meaning ‘not undefined’:Owners_data.ID_Insurance !=
null.With this filter, the Insured table will gather all
the records that include an insurance ID.
-
Click the tMap settings button at the top
of the Reject_NoInsur table and set Catch output reject to true to define the table as a standard reject output flow to
gather the records that do not include an insurance ID.
-
Click the tMap settings button at the top
of the Reject_OwnerID table and set Catch lookup inner join reject to true so that this output table will gather the
records from the Cars_data flow with missing or
unmatched owner IDs.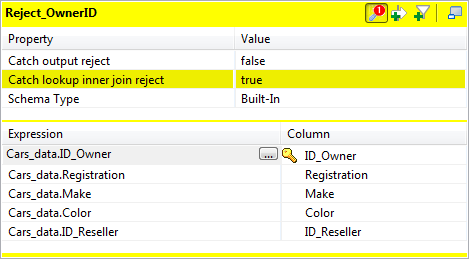 Click OK to validate the mappings and
Click OK to validate the mappings and
close the Map Editor. -
Double-click each of the output components, one after the other, to define
their properties. If you want a new file to be created, browse to the
destination output folder, and type in a file name including the
extension. Select the Include header check box to
Select the Include header check box to
reuse the column labels from the schema as header row in the output
file.
Executing the Job
-
Press Ctrl + S to save
your Job. -
Press F6 to run the
Job.The output files are created, which contain the relevant data
as defined.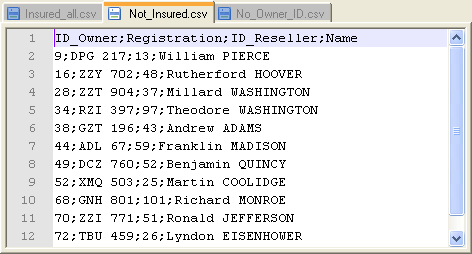
For examples of how to use
dynamic schemas with tMap,
see:
Mapping data using inner join rejections
This scenario, based on scenario 1, adds one input file containing details about
resellers and extra fields in the main output table. Two filters on inner joins are
added to gather specific rejections.
Linking the components
-
Drop a tFileInputDelimited component and
a tFileOutputDelimited component to the
design workspace, and label the components as Resellers
and No_Reseller_ID respectively. -
Connect it to the Mapper using a Row >
Main connection, and label the
connection as Resellers_data. -
Connect the tMap component to the new
tFileOutputDelimited component by using
the Row connection named
Reject_ResellerID.
Configuring the components
-
Double-click the Resellers component to display its
Basic settings view.
-
Select Repository from the Property type list and select the component’s
schema, resellers in this scenario, from the Repository Content dialog box. The rest fields
are automatically filled.Note:In this scenario, the input schemas are stored in the Metadata node of the Repository tree view for easy retrieval. For further
information regarding metadata creation in the Repository, see
Talend Studio User Guide. -
Double-click the tMap component to open
the Map Editor.Note that the schema of the new input component is already added in the
Input area. -
Create a join between the main input flow and the new input flow by
dropping the ID_Reseller column of the
Cars_data table to the
ID_Reseller column of the
Resellers_data table. -
Click the tMap settings button at the top
of the Resellers_data table and set Join Model to Inner
Join.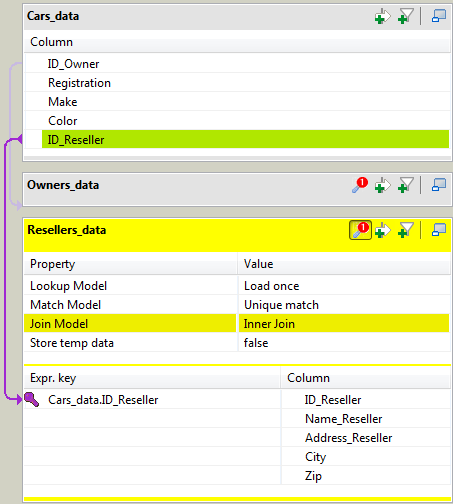
-
Drag all the columns except ID_Reseller of the
Resellers_data table to the main output table,
Insured.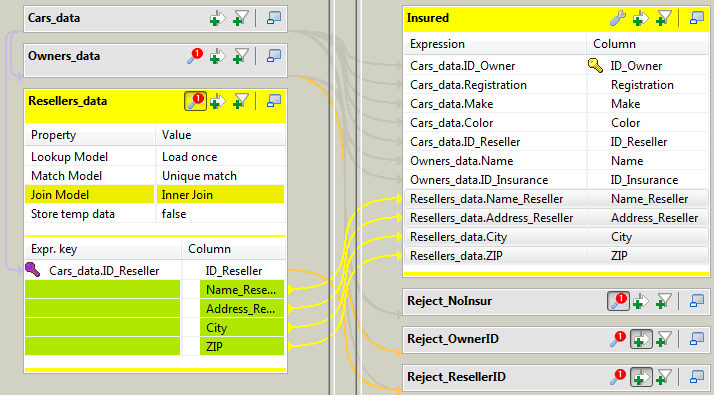 Note:
Note:When two inner joins are defined, you either need to define two
different inner join reject tables to differentiate the two rejections
or, if there is only one inner join reject output, both inner join
rejections will be stored in the same output. -
Click the [+] button at the top of the
output area to add a new output table, and name this new output table
Reject_ResellerID. -
Drag all the columns of the Cars_data table to the
Reject_ResellerID table. -
Click the tMap settings button and select
Catch lookup inner join reject to
true to define this new output table as
an inner join reject output.If the defined inner join cannot be established, the information about
the relevant cars will be gathered through this output flow.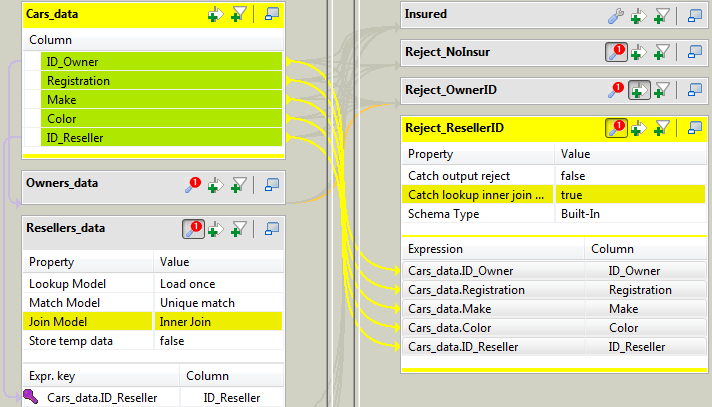
-
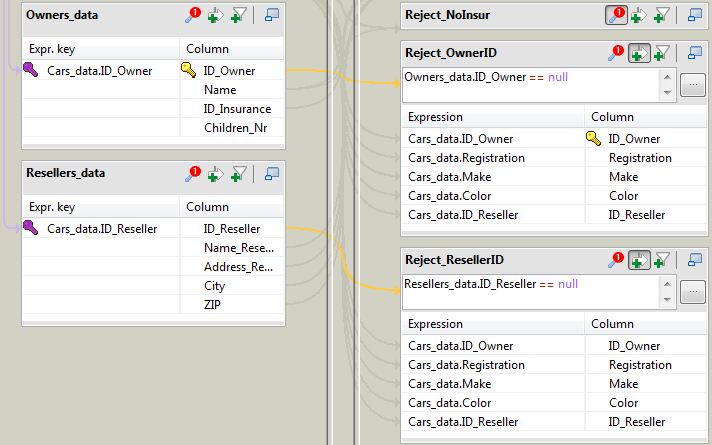
Now apply filters on the two Inner Join reject outputs, in order for to
distinguish the two types of rejection.In the first Inner Join output table, Reject_OwnerID,
click the plus arrow button to add a filter line and fill it with the
following formula to gather only owner ID related rejection:
Owners_data.ID_Owner==null -
In the second Inner Join output table,
Reject_ResellerID, repeat the same operation using
the following formula:Resellers_data.ID_Reseller==null
 Click OK to validate the map settings and
Click OK to validate the map settings and
close the Mapper Editor. -
Double-click the No_Reseller_ID component to display
its Basic settings view. Specify the output file path and select the Include
Specify the output file path and select the Include
Header check box, and leave the other parameters as they
are. -
To demonstrate the work of the Mapper, in this example, remove reseller
IDs 5 and 8 from the input file
Resellers.csv.
Executing the Job
- Press Ctrl + S to save your Job.
- Press F6 to run the Job.
The four output files are all created in the specified folder, containing
information as defined. The output file
No_Reseller_ID.csv contains the
cars information related to reseller IDs
5 and 8, which are missing in
the input file Resellers.csv.

As third advanced use scenario, based on the scenario 2, add a
new Input table containing Insurance details for example.
Set up an Inner Join between two lookup input tables (Owners
and Insurance) in the Mapper to create a cascade lookup and hence retrieve
Insurance details via the Owners table data.
Advanced mapping using filters, explicit joins and rejections
This scenario introduces a Job that allows you to find BMW owners who have two
to six children (inclusive), for sales promotion purpose for example.
Linking the components
-
Drop three tFileInputDelimited
components, a tMap component, and two
tFileOutputDelimited components from
the Palette onto the design workspace, and
label them to best describe their functions. -
Connect the input components to the tMap
using Row > Main connections.Pay attention to the file you connect first as it will automatically be
set as Main flow, and all the other
connections will be Lookup flows. In this
example, the connection for the input component Owners
is the Main flow.
Configuring the components
-
Define the properties of each input components in the respective Basic settings view. Define the properties of
Owners.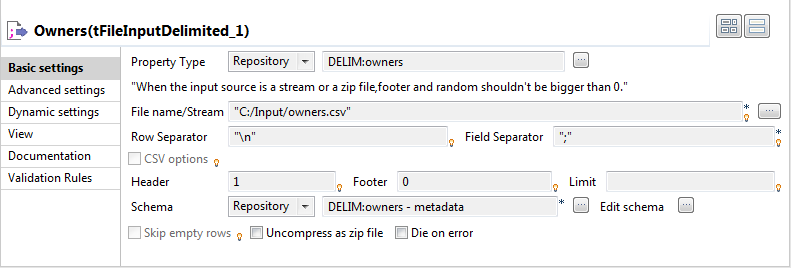
-
Select Repository from the Property type list and select the component’s
schema, owners in this scenario, from the Repository Content dialog box. The rest fields
are automatically filled.Note:In this scenario, the input schemas are stored in the Metadata node of the Repository tree view for easy retrieval. For further
information regarding metadata creation in the Repository, see
Talend Studio User Guide.In the same way, set the properties of the other input components:
Cars and Resellers. These two
Lookup flows will fill in secondary
(lookup) tables in the input area of the Map
Editor. -
Then double-click the tMap component to
launch the Map Editor and define the
mappings and filters.Set an explicit join between the Main
flow Owner and the Lookup flow Cars by dropping the
ID_Owner column of the Owners
table to the ID_Owner column of the
Cars table.The explicit join is displayed along with a hash key.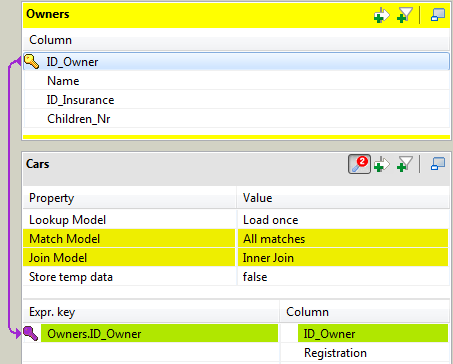
-
In the Expr. Key field of the
Make column, type in a filter. In this use case,
simply type in"BMW"as the search is focused on the owners of
this particular make.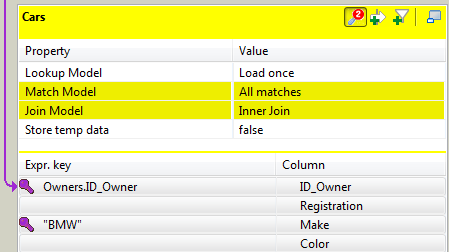
-
Implement a cascading join between the two lookup tables
Cars and Resellers on the
ID_Reseller column in order to retrieve resellers
information. -
As you want to reject the null values into a separate table and exclude
them from the standard output, click the tMap
settings button and set Join
Model to Inner Join in each
of the Lookup tables.
-
In the tMap settings, you can set Match
Model to Unique match,
First match, or All matches. In this use case, the All
matches option is selected. Thus if several matches are found
in the Inner Join, rows matching the explicit join as well as the filter,
all of them will be added to the output flow (either in rejection or the
regular output).Note:The Unique match option functions as
a Last match. The First match and All
matches options function as named. -
On the output area of the Map Editor,
click the plus button to add two tables, one for the full matches and the
other for the rejections. -
Drag all the columns of the Owners table, the
Registration, Make and
Color columns of the Cars
table, and the ID_Reseller and
Name_Reseller columns of the
Resellers table to the main output table. -
Drag all the columns of the Owners table to the
reject output table. -
Click the Filter button at the top of the
main output table to display the Filter
expression area.Type in a filter statement to narrow down the number of rows loaded in the
main output flow. In this use case, the statement reads:
Owners.Children_Nr >= 2 && Owners.Children_Nr <=.
6 -
In the reject output table, click the tMap
settings button and set the reject types.Set Catch output reject to true to collect data about BMW car owners who
have less than two or more than six children.Set Catch lookup inner join reject to
true to collect data about owners of
other car makes and owners for whom the reseller information is not
found.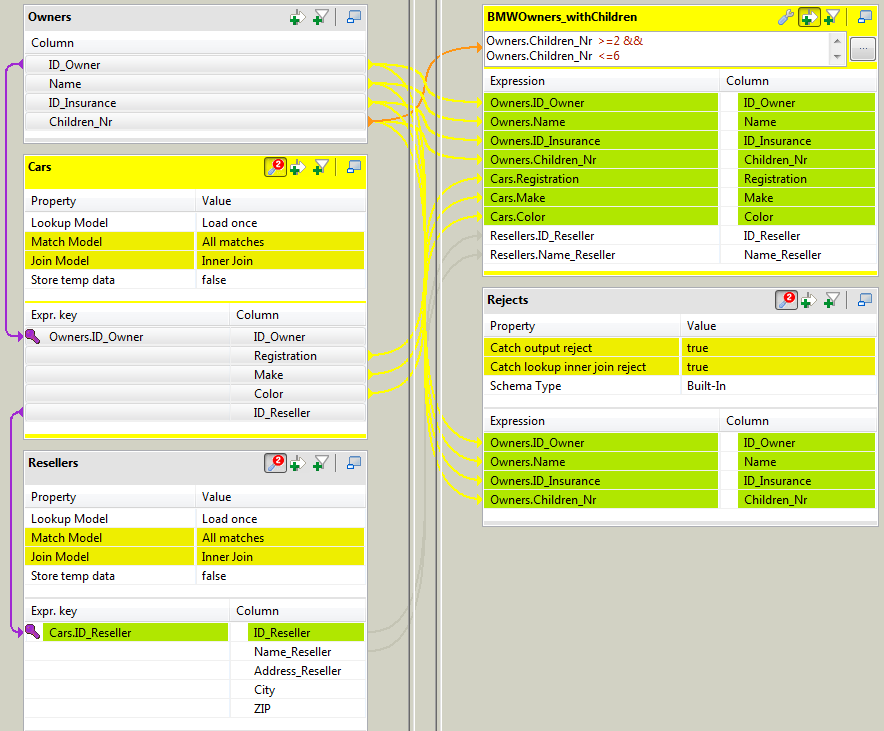 Click OK to validate the mappings and
Click OK to validate the mappings and
close the Map Editor.On the design workspace, right-click the tMap and pull the respective output link to the relevant
output components. -
Define the properties of the output components in their respective
Basic settings view.In this use case, simple specify the output file paths and select the
Include Header check box, and leave the
other parameters as they are.
Executing the Job
- Press Ctrl + S to save your Job.
-
Press F6 to run it.
The main output file contains the information related to BMW owners who
have two to six children, and the reject output file contains the
information about the rest of the car owners.
For examples of how to use dynamic schemas with tMap, see:
Advanced mapping with filters and different rejections
This scenario is a modified version of the preceding scenario. It describes a Job that
applies filters to limit the search to BMW and Mercedes owners who have two to six
children and divides unmatched data into different reject output flows.
Linking the components
- Take the same Job as in Advanced mapping using filters, explicit joins and rejections.
-
Drop a new tFileOutputDelimited component
from the Palette on the design workspace,
and name it Rejects_BMW_Mercedes to present its
functionality. -
Connect the tMap component to the new
output component using a Row connection and
label the connection according to the functionality of the output component.This connection label will appear as the name of the new output table in
the Map Editor. -
Relabel the existing output connections and output components to reflect
their functionality.The existing output tables in the Map
Editor will be automatically renamed according to the
connection labels. In this example, relabel the existing output connections
BMW_Mercedes_withChildren and
Owners_Other_Makes respectively.
Configuring the components
-
Double-click the tMap component to launch
the Map Editor to change the mappings and
the filters.Note that the output area contains a new, empty output table named
Rejects_BMW_Mercedes. You can adjust the position
of the table by selecting it and clicking the Up or Down arrow button at
the top of the output area. -
Remove the Expr. key filter
(“BMW”) from the Cars table in
the input area. -
Click the Filters button to display the
Filter field, and type in a new filter
to limit the search to BMW or
Mercedes car makes. The statement reads as follows:
Cars.Make.equals("BMW") ||
Cars.Make.equals("Mercedes")

-
Select all the columns of the main output table and drop them down to the
new output table.Alternatively, you can also drag the corresponding columns from the
relevant input tables to the new output table. -
Click the tMap settings button at the top
of the new output table and set Catch output
reject to true to collect
data about BMW and Mercedes owners who have less than two or more than six
children. -
In the Owners_Other_Makes table, set Catch lookup inner join reject to true to collect data about owners of other car
makes and owners for whom the reseller information is not found.
-
Click OK to validate the mappings and
close the Map Editor. -
Define the properties of the output components in their respective
Basic settings view.In this use case, simple specify the output file paths and select the
Include Header check box, and leave the
other parameters as they are.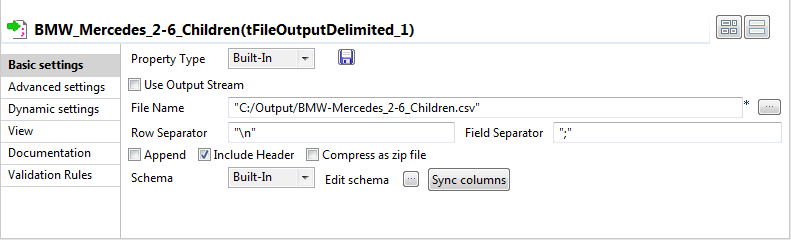
Executing the Job
- Press Ctrl + S to save the Job.
-
Press F6 to run it.
The output files contain content of the main output flow shows that the
filtered rows have correctly been passed on.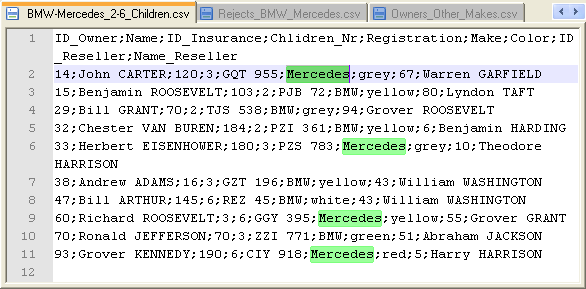
For examples of how to use dynamic schemas with tMap, see:
Advanced mapping with lookup reload at each row
The following scenario describes a Job that retrieves people details from a
lookup database, based on a join on the age. The main flow source data is read from a
MySQL database table called people_age that contains people details
such as numeric id, alphanumeric first name and last name and numeric age. The people
age is either 40 or 60. The number of records in this table is intentionally
restricted.
The reference or lookup information is also stored in a MySQL database
table called large_data_volume. This lookup table contains a
number of records including the city where people from the main flow have been to. For
the sake of clarity, the number of records is restricted but, in a normal use, the
usefulness of the feature described in the example below is more obvious for very large
reference data volume.
To optimize performance, a database connection component is used in the
beginning of the Job to open the connection to the lookup database table in order not to
do that every time we want to load a row from the lookup table.
An Expression Filter is applied to this lookup source flow, in order to
select only data from people whose age is equal to 60 or 40. This way only the relevant
rows from the lookup database table are loaded for each row from the main flow.
Therefore this Job shows how, from a limited number of main flow rows, the
lookup join can be optimized to load only results matching the expression key.
Generally speaking, as the lookup loading is performed for each main
flow row, this option is mainly interesting when a limited number of rows is
processed in the main flow while a large number of reference rows are to be looked
up to.
The join is solved on the age field. Then, using the
relevant loading option in the tMap component
editor, the lookup database information is loaded for each main flow incoming row.
For this Job, the metadata has been prepared for the source and connection
components. For more information on how to set up the DB connection schema metadata, see
the relevant section in the
Talend Studio User Guide.
This Job is formed with five components, four database components and a
mapping component.
Linking the components
-
Drop the DB Connection under the Metadata
node of the Repository to the design
workspace. In this example, the source table is called
people_age. -
Select tMysqlInput from the list that
pops up when dropping the component.
-
Drop the lookup DB connection table from the Metadata node to the design workspace selecting tMysqlInput from the list that pops up. In this
Job, the lookup is called large_data_volume. -
The same way, drop the DB connection from the Metadata node to the design workspace selecting tMysqlConnection from the list that pops up. This
component creates a permanent connection to the lookup database table in
order not to do that every time we want to load a row from the lookup
table. -
Then pick the tMap component from the
Processing family, and the tMysqlOutput and tMysqlCommit components from the Database family in the Palette
to the right hand side of the editor. -
Now connect all the components together. To do so, right-click the
tMysqlInput component corresponding to
the people table and drag the link towards tMap. -
Release the link over the tMap component,
the main row flow is automatically set up. -
Rename the Main row link to
people, to identify more easily the main flow
data. -
Perform the same operation to connect the lookup table
(large_data_volume) to the tMap component and the tMap
to the tMysqlOutput component. -
A dialog box prompts for a name to the output link. In this example, the
output flow is named: people_mixandmatch.
-
Rename also the lookup row connection link to
large_volume, to help identify the reference data
flow. - Connect tMysqlConnection to tMysqlInput using the trigger link OnSubjobOk.
-
Connect the tMysqlInput component to the
tMysqlCommit component using the
trigger link OnSubjobOk.
Configuring the components
-
Double-click the tMap component to open
the graphical mapping editor.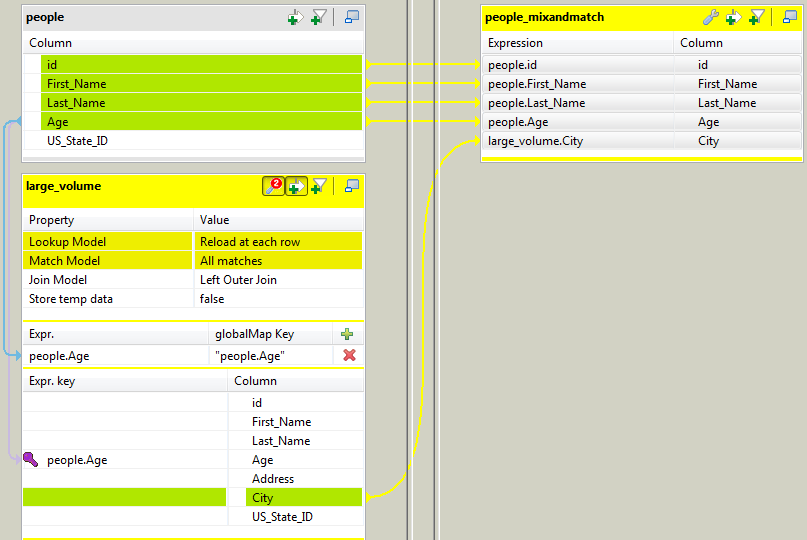
-
The Output table (that was created
automatically when you linked the tMap to
the tMySQLOutput will be formed by the
matching rows from the lookup flow (large_data_volume)
and the main flow (people_age).Select the main flow rows that are to be passed on to the output and drag
them over to paste them in the Output table (to the right hand side of the
mapping editor).In this example, the selection from the main flow include the following
fields: id, first_name,
last_Name and age.From the lookup table, the following column is selected:
city.Drop the selected columns from the input tables
(people and large_volume) to
the output table. -
Now set up the join between the main and lookup flows.
Select the age column of the main flow table (on top)
and drag it towards the age column of the lookup flow
table (large_volume in this example).A key icon appears next to the linked expression on the lookup table. The
join is now established. -
Click the tMap settings button, click the
three-dot button corresponding to Lookup
Model, and select the Reload at each
row option from the Options dialog box in order to reload the lookup for each
row being processed.
-
In the same way, set Match Model to
All matches in the Lookup table, in
order to gather all instances of age matches in the
output flow. -
Now implement the filtering, based on the age column,
in the Lookup table. The GlobalMapKey field
is automatically created when you selected the Reload
at each row option. Indeed you can use this expression to
dynamically filter the reference data in order to load only the relevant
information when joining with the main flow.As mentioned in the introduction of the scenario, the main flow data
contains only people whose age is either 40 or 60. To avoid the pain of
loading all lookup rows, including ages that are different from 40 and 60,
you can use the main flow age as global variable to feed the lookup
filtering.
-
Drop the Age column from the main flow table to the
Expr. field of the lookup table. -
Then in the globalMap Key field, put in
the variable name, using the expression. In this example, it reads:
"people.Age"
Click OK to save the mapping setting and
go back to the design workspace. -
To finalize the implementation of the dynamic filtering of the lookup
flow, you need now to add a WHERE clause in the query of the database
input.
-
At the end of the Query field, following
theSelectstatement, type in the following WHERE clause:
WHERE AGE
='"+((Integer)globalMap.get("people.Age"))+"'"
-
Make sure that the type corresponds to the column used as variable. In
this use case, Age is of Integer
type. And use the variable the way you set in the globalMap key field of the map editor. -
Double-click the tMysqloutput component
to define its properties.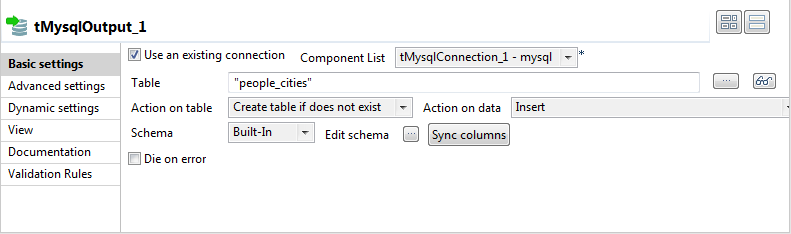
-
Select the Use an existing connection
check box to leverage the created DB connection.Define the target table name and relevant DB actions.
Executing the Job
- Press Ctrl + S to save the Job.
-
Click the Run tab at the bottom of the
design workspace, to display the Job execution tab. -
From the Debug Run view, click the
Traces Debug button to view the data
processing progress.For more comfort, you can maximize the Job design view while executing by
simply double-clicking on the Job name tab.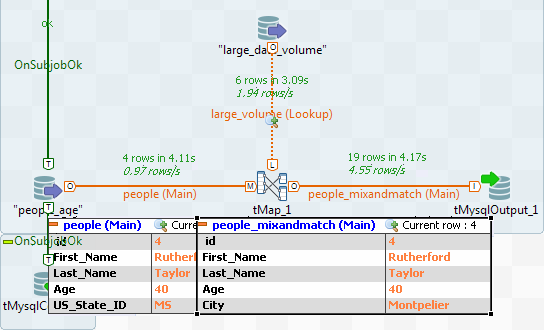 The lookup data is reloaded for each of the main flow’s rows,
The lookup data is reloaded for each of the main flow’s rows,
corresponding to the age constraint. All age matches
are retrieved in the lookup rows and grouped together in the output
flow.Therefore if you check out the data contained in the newly created
people_mixandmatch table, you will find all the
age duplicates corresponding to different
individuals whose age equals to 60 or 40 and the city where they have been
to.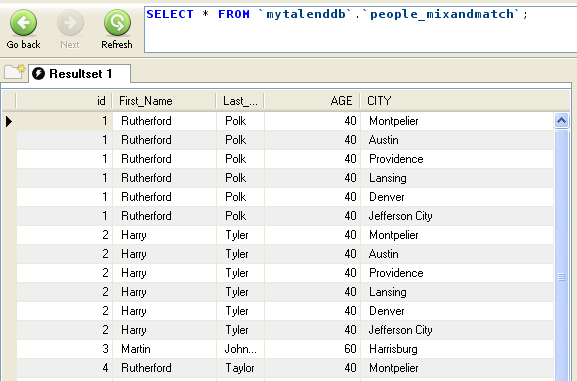
For examples of how to use dynamic schemas with tMap, see:
Mapping with join output tables
The following scenario describes a Job that processes reject flows without
separating them from the main flow.
Linking the components
-
In the Repository tree view, click
Metadata > File delimited. Drag and drop the
customers metadata onto the workspace.The customers metadata contains information about
customers, such as their ID, their name or their address, etc.For more information about centralizing metadata, see
Talend Studio
User Guide. -
In the dialog box that asks you to choose which component type you want to
use, select tFileInputDelimited and click
OK. -
Drop the states metadata onto the design workspace.
Select the same component in the dialog box and click OK.The states metadata contains the ID of the state,
and its name. - Drop a tMap and two tLogRow components from the Palette onto the design workspace.
-
Connect the customers component to the tMap, using a Row >
Main connection. -
Connect the states component to the tMap, using a Row >
Main connection. This flow will automatically be defined as
Lookup.
Configuring the components
-
Double-click the tMap component to open
the Map Editor.Drop the idState column from the main input table to
the idState column of the lookup table to create a
join.Click the tMap settings button and set
Join Model to Inner Join. -
Click the Property Settings button at the
top of the input area to open the Property
Settings dialog box, and clear the Die
on error check box in order to handle the execution errors.The ErrorReject table is automatically
created.
-
Select the id, idState,
RegTime and RegisterTime in
the input table and drag them to the ErrorReject table.
-
Click the [+] button at the top right of
the editor to add an output table. In the dialog box that opens, select
New output. In the field next to it,
type in the name of the table, out1. Click OK. -
Drag the following columns from the input tables to the
out1 table: id,
CustomerName, idState, and
LabelState.Add two columns, RegTime and
RegisterTime, to the end of the
out1 table and set their date formats:
"dd/MM/yyyy HH:mm"and"yyyy-MM-ddrespectively.
HH:mm:ss.SSS" -
Click in the Expression field for the
RegTime column, and press Ctrl+Space to display the auto-completion list. Find and
double-click
TalendDate.parseDate
("dd/MM/yyyy HH:mm",row1.RegTime). -
Do the same thing for the RegisterTime column, but
change the pattern to("yyyy-MM-dd.
HH:mm:ss.SSS",row1.RegisterTime)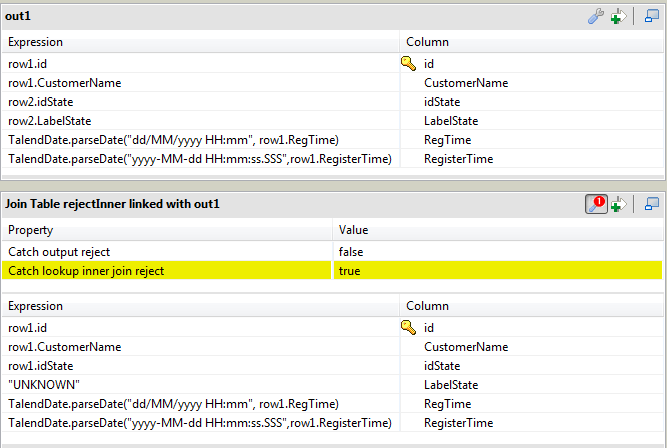
-
Click the [+] button at the top of the
output area to add an output table. In the dialog box that opens, select
Create join table from, choose
Out1, and name it rejectInner.
Click OK. -
Click the tMap settings button and set
Catch lookup inner join reject to
true in order to handle rejects. -
Drag the id, CustomerName, and
idState columns from the input tables to the
corresponding columns of the rejectInner table.Click in the Expression field for the
LabelState column, and type in
"UNKNOWN". -
Click in the Expression field for the
RegTime column, press Ctrl+Space, and selectTalendDate.parseDate. Change the
pattern to("dd/MM/yyyy HH:mm",row1.RegTime). -
Click in the Expression field for the
RegisterTime column, press Ctrl+Space, and selectTalendDate.parseDate, but change
the pattern to("yyyy-MM-dd.
HH:mm:ss.SSS",row1.RegisterTime)If the data from row1 has a wrong pattern, it will
be returned by the ErrorReject flow.
Click OK to validate the changes and
close the editor. -
Double-click the first tLogRow component
to display its Component view.Click Sync columns to retrieve the
schema structure from the mapper if needed.In the Mode area, select Table.Do the same thing with the second tLogRow.
Executing the Job
- Press Ctrl + S to save your Job.
- Press F6 to execute it.
The Run console displays the main out
flow and the ErrorReject flow. The main output flow unites both valid data
and inner join rejects, while the ErrorReject flow contains the error
information about rows with unparseable date formats.

For examples of how to use dynamic
schemas with tMap, see:
tMap MapReduce properties (deprecated)
These properties are used to configure tMap running in the MapReduce Job framework.
The MapReduce
tMap component belongs to the Processing family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Map editor |
It allows you to define the tMap Note: If you do not want to handle execution errors, you can click
the Property Settings button at the top of the input area and select the Die on error check box (selected by default) in the Property Settings dialog box. It will kill the Job if there is an error. Note: To maximize the data transformation performance in a Job
that handles multiple lookup input flows with large amounts of data, you can select the Lookup in parallel check box in the Property Settings dialog box. However, in a Map/Reduce Job, only one expression key is |
|
Mapping links display as |
Auto: the default setting is
Curves: the mapping display as
Lines: the mapping displays as |
| Temp data directory path | Enter the path where you want to store the temporary data generated for lookup loading. For more information on this folder, see Talend Studio User Guide. |
|
Preview |
The preview is an instant shot of the Mapper data. It becomes available when Mapper properties have been filled in with data. The preview synchronization takes effect only after saving changes. |
|
Use replicated join |
Select this check box to perform a replicated join between the input flows. By replicating each lookup table into memory, this type of join doesn’t require an additional shuffle-and-sort step, thus speeding up the whole process. You need to ensure that the entire lookup tables fit in |
Advanced settings
| Max buffer size (nb of rows) | Type in the size of physical memory, in number of rows, you want to allocate to processed data. |
| Ignore trailing zeros for BigDecimal | Select this check box to ignore trailing zeros for BigDecimal data. |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a As explained earlier, If you need to use multiple expression keys For further information about a Note that in this documentation, unless otherwise |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tMap properties for Apache Spark Batch
These properties are used to configure tMap running in the Spark Batch Job framework.
The Spark Batch
tMap component belongs to the Processing family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Map editor |
It allows you to define the tMap routing and transformation properties but note For further information about this Load once lookup model, see the related When you click the Property Settings
|
|
Mapping links display as |
Auto: the default setting is curves Curves: the mapping display as curves
Lines: the mapping displays as straight |
|
Preview |
The preview is an instant shot of the Mapper data. It becomes |
|
Use replicated join |
Select this check box to perform a replicated join between the input You need to ensure that the entire lookup tables fit in memory. |
| Max buffer size (nb of rows) | Type in the size of physical memory, in number of rows, you want to allocate to processed data. |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
For a related scenario, see Performing download analysis using a Spark Batch Job.
tMap properties for Apache Spark Streaming
These properties are used to configure tMap running in the Spark Streaming Job framework.
The Spark Streaming
tMap component belongs to the Processing family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Map editor |
It allows you to define the tMap When you click the Property Settings
|
|
Mapping links display as |
Auto: the default setting is curves Curves: the mapping display as curves
Lines: the mapping displays as straight |
|
Preview |
The preview is an instant shot of the Mapper data. It becomes |
|
Use replicated join |
Select this check box to perform a replicated join between the input You need to ensure that the entire lookup tables fit in memory. |
Usage
|
Usage rule |
It usually works with a Lookup Input component such as tMongoDBLookupInput to construct and consume a lookup flow. In this situation, |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
For a related scenario, see Analyzing a Twitter flow in near real-time.