tMysqlInput
Executes a DB query with a strictly defined order which must correspond to the
schema definition.
tMysqlInput reads a database and extracts fields based on a query. Then
it passes on the field list to the next component via a Main row link.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tMysqlInput Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tMysqlInput MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tMysqlInput properties for Apache Spark Batch.
This component also allows you to connect and read data from a RDS Aurora or a RDS MySQL
database.The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
tMysqlInput Standard properties
These properties are used to configure tMysqlInput running in
the Standard Job framework.
The Standard
tMysqlInput component belongs to the Databases family.
The component in this framework is available in all Talend
products.
connector. The properties related to database settings vary depending on your database
type selection. For more information about dynamic database connectors, see Dynamic database components.
Basic settings
| Database |
Select a type of database from the list and click |
|
Property type |
Either Built-In or Repository. Built-In: No property data stored centrally.
Repository: Select the repository file where the |
|
|
Click this icon to open a database connection wizard and store the For more information about setting up and storing database connection |
|
DB version |
Select the version of the database to be used. |
|
Use an existing connection |
Select this check box and in the Component List click the relevant connection component to Note: When a Job contains the parent Job and the child Job, if you
need to share an existing connection between the two levels, for example, to share the connection created by the parent Job with the child Job, you have to:
For an example about how to share a database connection |
|
Host |
Database server IP address. |
|
Port |
Listening port number of DB server. |
|
Database |
Name of the database. |
|
Username and Password |
DB user authentication data. To enter the password, click the […] button next to the |
|
Schema and Edit |
A schema is a row description. It defines the number of fields This This |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Click Edit
|
|
|
Table |
Name of the table to be read. |
|
Query type and Query |
Enter your DB query paying particularly attention to
If using |
| Specify a data source alias |
Select this check box and specify the alias of a data source created on the Warning:
If you use the component’s own DB configuration, your data source connection will be This check box is not available when the Use an existing |

Advanced settings
|
Additional JDBC parameters |
Specify additional connection properties for the DB connection you are Note:
When you need to handle data of the time-stamp type 0000-00-00 00:00:00 using this component, set the parameter as: |
|
Enable stream |
Select this check box to enables streaming over buffering which allows This check box is available only when Mysql 4 or |
|
Trim all the String/Char columns |
Select this check box to remove leading and trailing whitespace from |
|
Trim column |
Remove leading and trailing whitespace from defined columns. Note:
Clear Trim all the String/Char columns to enable Trim columns in this field. |
|
tStatCatcher Statistics |
Select this check box to collect log data at the component |
Global Variables
|
Global Variables |
NB_LINE: the number of rows processed. This is an After
QUERY: the query statement being processed. This is a Flow
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component covers all possible SQL queries for Mysql |
|
Dynamic settings |
Click the [+] button to add a row in the table The Dynamic settings table is For examples on using dynamic parameters, see Reading data from databases through context-based dynamic connections and Reading data from different MySQL databases using dynamically loaded connection parameters. For more information on Dynamic |
Writing columns from a MySQL database to an output file using
tMysqlInput
In this scenario we will read certain columns from a MySQL database, and then
write them to a table in a local output file.
Dragging and dropping components and linking them together
- Drop tMysqlInput and tFileOutputDelimited from the Palette onto the workspace.
-
Link tMysqlInput to tFileOutputDelimited using a Row > Main connection.

Configuring the components
-
Double-click tMysqlInput to open its
Basic Settings view in the Component tab.
-
From the Property Type list, select
Repository if you have already stored
the connection to database in the Metadata
node of the Repository tree view. The
property fields that follow are automatically filled in.For more information about how to store a database connection, see
Talend Studio
User Guide.If you have not defined the database connection locally in the Repository, fill in the details manually after
selecting Built-in from the Property Type list. -
Set the Schema as Built-in and click Edit
schema to define the desired schema.The schema editor opens:
-
Click the [+] button to add the rows
that you will use to define the schema, four columns in this example
id, first_name,
city and salary.Under Column, click in the fields to
enter the corresponding column names.Click the field under Type to define the
type of data.Click OK to close the schema
editor. -
Next to the Table Name field, click
the […] button to select the database
table of interest.A dialog box displays a tree diagram of all the tables in the selected
database:
- Click the table of interest and then click OK to close the dialog box.
- Set the Query Type as Built-In.
-
In the Query box, enter the query
required to retrieve the desired columns from the table.
-
Double-click tFileOutputDelimited to set
its Basic settings in the Component tab.
-
Next to the File Name field, click the
[…] button to browse your directory
to where you want to save the output file, then enter a name for the
file.Select the Include Header check box to
retrieve the column names as well as the data. - Save the Job.
Executing the Job
The results below can be found after F6 is
pressed to run the Job.

As shown above, the output file is written with the desired column names and
corresponding data, retrieved from the database:
The Job can also be run in the Traces Debug
mode, which allows you to view the rows as they are being written to the output
file, in the workspace.
Using context parameters when reading a table from a database
In this scenario, MySQL is used for demonstration purposes. We will read a
table from a MySQL database, using a context parameter to refer to the table name.
Dragging and dropping components and linking them together
- Drop tMysqlInput and tLogRow from the Palette onto the workspace.
-
Link tMysqlInput to tLogRow using a Row >
Main connection.
Configuring the components
-
Double-click tMysqlInput to open its
Basic Settings view in the Component tab.
-
From the Property Type list, select
Repository if you have already stored
the connection to database in the Metadata
node of the Repository tree view. The
property fields that follow are automatically filled in.For more information about how to store a database connection, see
Talend Studio
User Guide.If you have not defined the database connection in the Repository, fill in the details manually after
selecting Built-in from the Property Type list. -
Set the Schema as Built-In and click Edit
schema to define the desired schema.The schema editor opens:
-
Click the [+] button to add the rows
that you will use to define the schema, seven columns in this example:
id, first_name, last_name, city, state, date_of_birth and salary.Under Column, click the fields to enter
the corresponding column names.Click the fields under Type to define
the type of data.Click OK to close the schema
editor. -
Put the cursor in the Table Name field
and press F5 for context parameter setting. For more information about context settings, see
For more information about context settings, see
Talend Studio
User Guide. -
Keep the default setting in the Name
field and type in the name of the database table in the Default value field, employees in this case. -
Click Finish to validate the setting.
The context parameter context.TABLE
automatically appears in the Table Name
field. -
In the Query type list, select Built-In. Then, click Guess
Query to get the query statement.In this use case, we want to read the records with the salary above 8000.
Therefore, we add aWhereclause and the final query statement
is as follows:1234567891011"SELECT"+context.TABLE+".`id`,"+context.TABLE+".`first_name`,"+context.TABLE+".`last_name`,"+context.TABLE+".`city`,"+context.TABLE+".`state`,"+context.TABLE+".`date_of_birth`,"+context.TABLE+".`salary`FROM "+context.TABLE+"WHERE"+context.TABLE+".`salary` > 8000" -
Double-click tLogRow to set its Basic Settings in the Component tab.

-
In the Mode area, select Table (print values in cells of a table) for a
better display of the results. - Save the Job.
Executing the Job
The results below can be found after F6 is
pressed to run the Job.
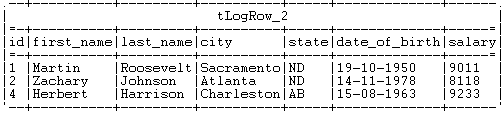
As shown above, the records with the salary greater than 8000 are
retrieved.
Reading data from databases through context-based dynamic
connections
In this scenario, MySQL is used for demonstration purposes. We will read data
from database tables with the same data structure but in two different MySQL databases named
project_q1 and project_q2 respectively. We will
specify the connections to these databases dynamically at runtime, without making any
modification to the Job.
Dropping and linking the components
-
Drop two tMysqlConnection, a tMysqlInput, a tLogRow, and a tMysqlClose
components onto the design workspace. -
Link the first tMysqlConnection to the
second tMysqlConnection and the second
tMysqlConnection to tMysqlInput using Trigger > On Subjob Ok
connections. -
Link tMysqlInput to tLogRow using a Row >
Main connection. -
Link tMysqlInput to tMysqlClose using a Trigger
> On Subjob Ok connection.
Creating a context variable
To be able to choose a database connection dynamically at runtime, we need to
define a context variable, which will then be configure it in the Dynamic settings of the database input component.
-
In the Contexts view, click the [+] button to add a row in the table, click in
the Name field and enter a name for the
variable, myConnection in this
example.
-
From the Type list field, select
List Of Value. -
Click in the Value field and then click
the button that appears in the field to open the Configure value of list dialog box.
-
In the Configure value of list dialog
box, click the New… button to open the
New Value dialog box, and enter the
name of one of the connection components in the text field, tMysqlConnection_1 in this example. Then click
OK to close the dialog box. Repeat this step to specify the other connection component name as another
Repeat this step to specify the other connection component name as another
list item, tMysqlConnection_2 in this
example.When done, click OK to close the
Configure Values dialog box. -
Select the check box next to the variable value field, and fill the
Prompt field with the message you want
to display at runtime, Select a connection
component: in this example.
Configuring the components
-
Double-click the first tMysqlConnection
component to show its Basic settings view,
and set the connection details. For more information on the configuration of
tMysqlConnection, see tMysqlConnection.Note that we use this component to open a connection to a MySQL databased
named project_q1.
-
Configure the second tMysqlConnection
component in the same way, but fill the Database field with project_q2 because we want to use this component to open a
connection to another MySQL database, project_q2.
-
Double-click the tMysqlInput component to
show its Basic settings view.
-
Select the Use an existing connection
check box, and leave the Component List box
as it is. -
Click the […] button next to Edit schema to open the Schema dialog box and define the data structure of the
database table to read data from. In this example, the database table structure is made of four columns,
In this example, the database table structure is made of four columns,
id (type Integer, 2 characters long),
firstName (type String, 15 characters
long), lastName (type String, 15
characters long), and city (type String,
15 characters long). When done, click OK to
close the dialog box and propagate the schema settings to the next
component. -
Fill the Table field with the database
table name, customers in this example,
and click Guess Query to generate the query
statement corresponding to your table schema in the Query field. -
In the Dynamic settings view, click the
[+] button to add a row in the table,
and fill the Code field with the code
script of the context variable you just created," +in this example.
context.myConnection + "
-
In the Basic settings view of the
tLogRow component, select the Table option for better display effect of the Job
execution result.
-
In the Dynamic settings view of the
tMysqlClose component, do exactly the
same as in the Dynamic settings view of the
tMysqlInput component.
Saving and executing the Job
-
Press Ctrl+S to save your Job and press
F6 or click Run to launch it.A dialog box appears prompting you to specify the connection component you
want to use. -
Select the connection component, tMysqlConnection_1, and click OK.
 The data read from database project_q1
The data read from database project_q1
is displayed in the Run console.
-
Press F6 or click Run
to launch your Job again. When prompted, select the other connection
component, tMysqlConnection_2, to read data
from the other database, project_q2.The data read from database project_q2
is displayed in the Run console.
Writing dynamic columns from a database to an output file
This scenario applies only to subscription-based Talend products.
In this scenario, MySQL is used for demonstration purposes. You will read
dynamic columns from a MySQL database, map them and then write them to a table in a local
output file. By defining a dynamic column alongside known column names, we can retrieve all of
the columns from the database table, including the unknown columns.
Dragging and dropping components and linking them together
- Drop a tMysqlInput, a tMap and a tFileOutputDelimited component onto the workspace.
-
Link tMysqlInput to tMap using a Row >
Main connection. -
Link tMap to tFileOutputDelimited using a Row >
*New Output* (Main) connection.
Configuring the components
Configuring the tMysqlInput component
-
Double-click tMysqlInput
to open its Basic Settings view in the
Component tab. Warning:
Warning:The dynamic schema feature is only supported in
Built-In mode. -
Select Built-in as the
Property Type. - Select the DB Version from the corresponding list.
-
Next to Host, enter the database server IP
address. -
Next to Port, enter the listening port number of the
database server. -
Enter your authentication data in the Username and
Password fields. -
Set the Schema type
as Built-in and click Edit schema to define the dynamic schema.The schema editor opens:

-
Click the [+] button to
add a row to the schema.-
Under Column and Db
Column, click in the fields to enter the corresponding
column names. -
Click the field under Type to define the type of
data. -
Click the arrow and select Dynamic from the
list.Warning:Under Type, the dynamic column type
must be set as Dynamic.
-
Under Column and Db
-
Click OK to close the
schema editor. -
Next to the Table Name
field, click the […] button to select
the database table of interest.A dialog box displays a tree diagram of all the tables in the selected
database:
-
Click the table of interest and then click OK to close
the dialog box. -
Set the Query Type as
Built-In. -
In the Query box, enter the query required to retrieve
all of the columns from the table.Warning:In the SELECT statement it is necessary to use the
* wildcard character, to retrieve all of the
columns from the selected table.
Configuring the tMap component
-
Click tMap to open its
Basic Settings view in the Component tab. -
Click […] next to
Map Editor to map the column from the
source file.
-
Drop the column defined as dynamic from the input schema on
the left onto the output schema on the right.The column dropped on the output schema retains its original
values.Warning:The dynamic column must be mapped on
a one to one basis and cannot undergo any transformations. It cannot be
used in a filter expression or in a variables section. It cannot be
renamed in the output table and cannot be used as a join condition.
-
Click OK to close the
Map Editor.
Configuring the tFileOutputDelimited component
-
Double-click tFileOutputDelimited to set
its Basic Settings in the Component tab.
-
Next to the File Name field, click the
[…] button to browse your directory
to where you want to save the output file, then enter a name for the
file. -
Select the Include Header check box to
retrieve the column names as well as the data.
Executing the Job
-
Press Ctrl+S to save the
Job. -
Press F6 to run
it.
The output file is written with all the column names and corresponding data,
retrieved from the database via the dynamic schema:

The Job can also be run in the Traces
Debug mode, which allows you to view the rows as they are written to
the output file, in the workspace.
For further information about defining and mapping dynamic schemas,
see
Talend Studio
User Guide.
Related scenarios
tMysqlInput MapReduce properties (deprecated)
These properties are used to configure tMysqlInput running in
the MapReduce Job framework.
The MapReduce
tMysqlInput component belongs to the Databases family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. Built-In: No property data stored centrally.
Repository: Select the repository file where the |
|
|
Click this icon to open a database connection wizard and store the For more information about setting up and storing database connection |
|
Use an existing connection |
Select this check box and in the Component List click the relevant connection component to |
|
DB version |
Select the version of the database to be used. |
|
Host |
Database server IP address. |
|
Port |
Listening port number of DB server. |
|
Database |
Name of the database. |
|
Username and Password |
DB user authentication data. To enter the password, click the […] button next to the |
|
Schema and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Click Edit
|
|
|
Table |
Name of the table to be read. |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
|
Query type and Query |
Enter your DB query paying particularly attention to properly sequence |
Usage
|
Usage rule |
In a You need to use the Hadoop Configuration tab in the Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tMysqlInput properties for Apache Spark Batch
These properties are used to configure tMysqlInput running in
the Spark Batch Job framework.
The Spark Batch
tMysqlInput component belongs to the Databases family.
This component also allows you to connect and read data from a RDS Aurora or a RDS MySQL
database.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Property type |
Either Built-In or Repository. Built-In: No property data stored centrally.
Repository: Select the repository file where the |
|
|
Click this icon to open a database connection wizard and store the For more information about setting up and storing database connection |
|
Use an existing connection |
Select this check box and in the Component List click the relevant connection component to |
|
DB version |
Select the version of the database to be used. When the database to be used is RDS Aurora, you need to select Mysql 5. |
|
Host |
Database server IP address. |
|
Port |
Listening port number of DB server. |
|
Database |
Name of the database. |
|
Username and Password |
DB user authentication data. To enter the password, click the […] button next to the |
|
Schema and Edit |
A schema is a row description. It defines the number of fields |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Click Edit
|
|
|
Table Name |
Type in the name of the table from which you need to read |
|
Query type and Query |
Specify the database query statement paying particularly attention to the If you are using Spark V2.0 onwards, the Spark SQL does not For example, if you need to perform a query in a table system.mytable, in which the system prefix indicates the schema that the mytable table belongs to, in the query, you must enter mytable only. |
Advanced settings
|
Additional JDBC parameters |
Specify additional connection properties for the database connection you are This field is not available if the Use an existing |
|
Spark SQL JDBC parameters |
Add the JDBC properties supported by Spark SQL to this table. This component automatically set the url, dbtable and driver properties by using the configuration from |
|
Trim all the String/Char columns |
Select this check box to remove leading and trailing whitespace from |
|
Trim column |
Remove leading and trailing whitespace from defined columns. Note:
Clear Trim all the String/Char |
|
Enable partitioning |
Select this check box to read data in partitions. Define, within double quotation marks, the following parameters to
configure the partitioning:
The average size of the partitions is the result of the difference between the For example, to partition 1000 rows into 4 partitions, if you enter 0 for |
Usage
|
Usage rule |
This component is used as a start component and requires an output This component should use a tMysqlConfiguration component This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
For a scenario about how to use the same type of component in a Spark Batch Job, see Writing and reading data from MongoDB using a Spark Batch Job.