tNeo4jBatchOutputRelationship
tNeo4jBatchOutputRelationship Standard properties
These properties are used to configure tNeo4jBatchOutputRelationship running in the Standard Job framework.
The Standard
tNeo4jBatchOutputRelationship component belongs to the Big Data and the Databases NoSQL families.
The component in this framework is available in all Talend products with Big Data
and in Talend Data Fabric.
Basic settings
|
Use existing connection |
Select this check box and in the Component List click the relevant connection component to This component supports Neo4j version V3.2.X only and does not support the remote mode. Therefore, do not reuse the connection to versions other than V3.2.X defined in a tNeo4jConnection component and do not select the Remote server check box in tNeo4jConnection. Do |
|
Database path |
Specify the directory to hold your data files. This field appears only if you do not select the |
|
Shutdown after |
Select this check box to shutdown the Neo4j database connection when no more Alternatively, you can use tNeo4jClose to shutdown the This avoids errors such as “Id file not properly shutdown” at next execution This check box is available only if the Use an existing |
|
Field for relationship types |
Select the column from the input schema you have defined in the preceding components to provide types for the relationships to be created. |
|
Direction of the relationship |
Select the direction of the relationships to be created:
|
|
Start node of the relationship |
Defining the start node of each relationship using the node identifier:
|
|
End node of the relationship |
Defining the end node of each relationship using the node identifier:
|
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the |
Advanced settings
|
Neo4j configuration |
Add parameters to the table to configure the database to be created. For further information, see Neo4j documentation: Configuration settings. When entering values, use the syntax demonstrated by the examples given alongside the column names of this Nodes files table. |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the Job level |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is used as an output component and it always needs an incoming link. |
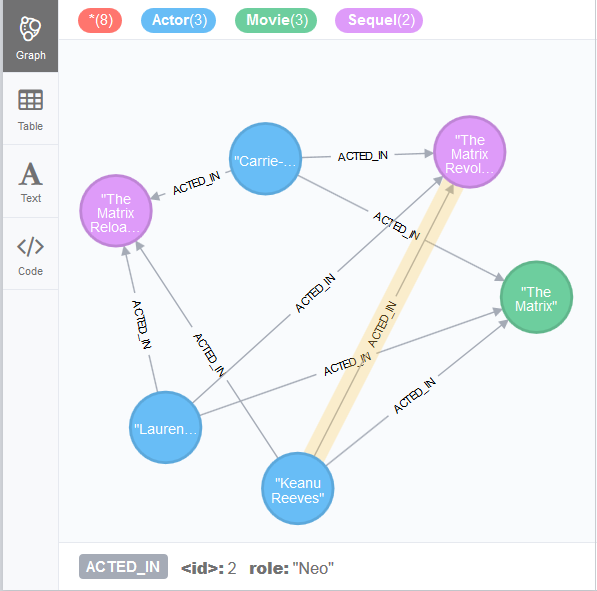
Writing information of actors and movies to Neo4j with hierarchical
relationship using Neo4j Batch components
actors and movies from two CSV files in a local Neo4j database and create
relationship for the data based on another CSV file that describes
the actors’ roles in the movies.
This scenario applies only to Talend products with Big Data.
The Neo4j Batch components provided by Talend supports bulk writing to a local Neo4j database only. They can be used neither with Neo4j versions prior to V3.2.X nor alongside Neo4j components that are using one of those Neo4j versions.
-
One tNeo4jConnection component: it opens the connection to Neo4j to be reused.
-
Three tFileInputDelimited
components: they read the input information of actors and
movies. -
Two tNeo4jBatchOutput components: they
write information of movies and actors to the connected Neo4j
database. -
One tNeo4jBatchOutputRelationship component: it creates
relationship between actors and movies. -
One tNeo4jBatchSchema component: it creates an uniqueness constraint on the nodes in the database.
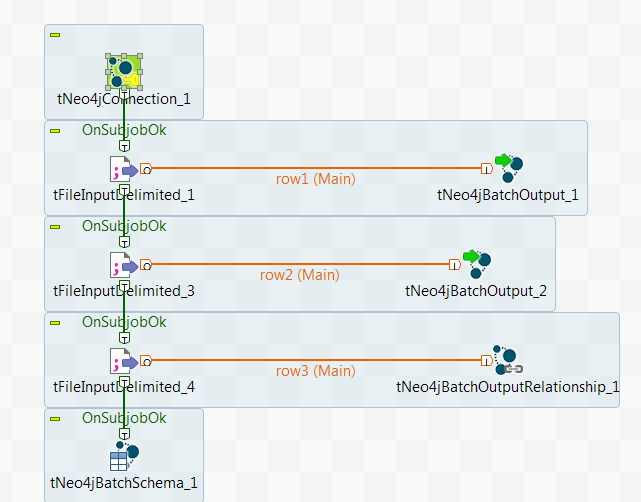
Creating the Neo4j Batch Job
-
Ensure that the status of your Neo4j service and Neo4j console is
stop.If you are using command-line to manage Neo4j, you can use
neo4j statusto check
the status; if you have installed the Neo4j desktop application, you can
check it directly in this application. - From the Repository on the Integration perspective, create a Job and add the components to be used by typing their names in the design workspace or dropping them from the Palette.
-
Connect the first tFileInputDelimited component to the
first tNeo4jBatchOutput component using a
Row > Main link. This subJob imports the actors data in the Neo4j database. -
Connect the second tFileInputDelimited
component to the second tNeo4jBatchOutput
component using a Row > Main link. This subJob imports the movies data in the Neo4j database. -
Connect the third tFileInputDelimited
component to the tNeo4jBatchOutputRelationship
component using a Row > Main link. This subJob creates relationship between actors and movies. - Connect the subJobs using Trigger > On Subjob Ok links.
Configuring the Neo4j connection to be reused
-
Double-click the tNeo4jConnection
component to open its Basic settings view.
-
From the DB Version list, select Neo4J 3.2.X.
- Ensure that the Use a remote server check box is clear because that the Neo4j Batch components work only on the local mode.
- In the Database path field, enter the path or browse to the database file.
Bulk-writing the actors data in Neo4j
-
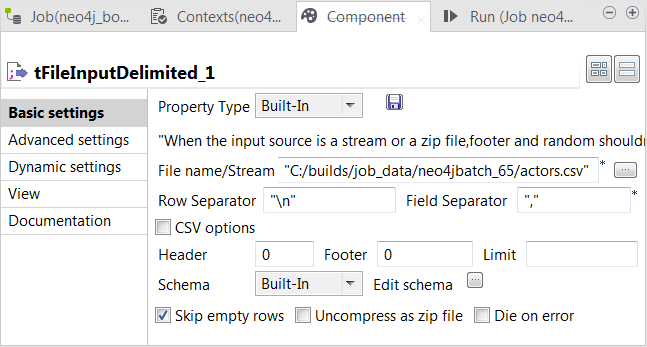
Double-click the first tFileInputDelimited component to open its Component view.
-
In the File name/Stream field, enter the path or browse to the CSV file that describes the actors’ IDs, names and their labels to be used in Neo4j.
The input CSV file used in this example reads as follows:
123keanu,"Keanu Reeves",Actorlaurence,"Laurence Fishburne",Actorcarrieanne,"Carrie-Anne Moss",ActorThe double quotation marks on the actor names are not mandatory.
-
Click the […] button next to Edit schema to open the schema editor, and define the input schema based on
the structure of the input file.In this example, the columns are id,
name and label, all of type
String.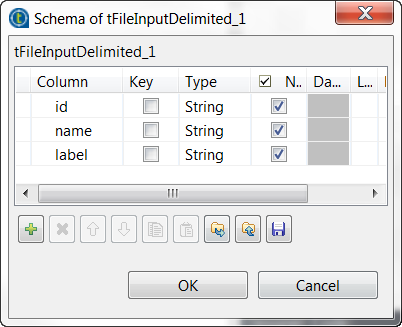
-
Click OK to close this editor and accept the propagation
of the schema to the next component. -
In the Field separator field, enter a comma (,) to
replace the default semicolon (;). -
Double-click the first tNeo4jBatchOutput component to open its
Component view.
-
Select the Use an existing connection
check box to reuse the Neo4j database connection opened by the tNeo4jConnection component. - Verify that the Shutdown after Job check box is clear.
- From the Field that contains the label list drop-down list, select the column that provides labels.
- In the Index name field, enter the name of the index to be created for the nodes.
- From Import identifier drop-down list, select the column that provides IDs.
Bulk-writing the movies data into Neo4j
-
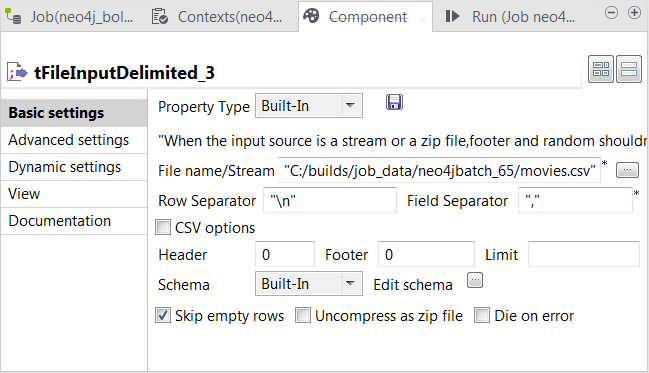
Double-click the second tFileInputDelimited component to open its Component view.
-
In the File name/Stream field, enter the path or browse to the CSV file that describes the movies’ IDs, names, release years and their labels to be used in Neo4j.
The input CSV file used in this example reads as follows:
123tt0133093,"The Matrix",1999,Moviett0234215,"The Matrix Reloaded",2003,Movie;Sequeltt0242653,"The Matrix Revolutions",2003,Movie;SequelThe double quotation marks on the movie names are not mandate.
-
Click the […] button next to Edit schema to open the schema editor, and define the input schema based on
the structure of the input file.In this example, the columns are id,
title, released and
label.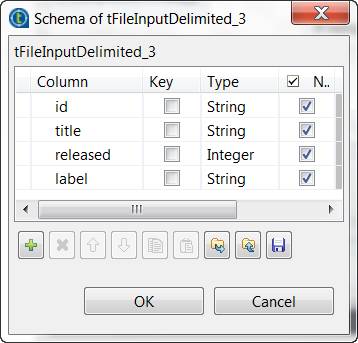
-
Click OK to close this editor and accept the propagation
of the schema to the next component. -
In the Field separator field, enter a comma (,) to
replace the default semicolon (;). -
Double-click the second tNeo4jBatchOutput component to open its
Component view.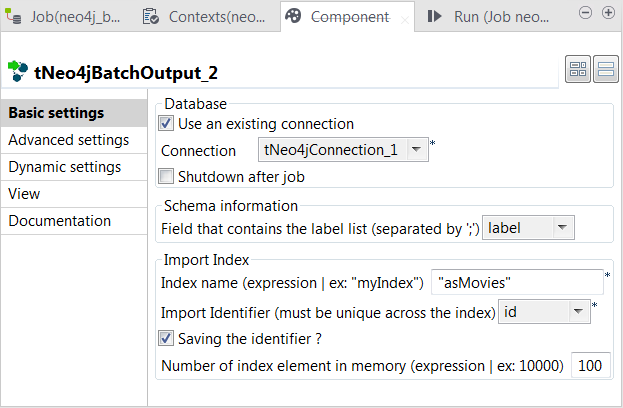
-
Select the Use an existing connection
check box to reuse the Neo4j database connection opened by the tNeo4jConnection component. - Verify that the Shutdown after Job check box is clear.
- From the Field that contains the label list drop-down list, select the column that provides labels.
- In the Index name field, enter the name of the index to be created for the nodes.
- From Import identifier drop-down list, select the column that provides IDs.
Creating relationships in bulk
-
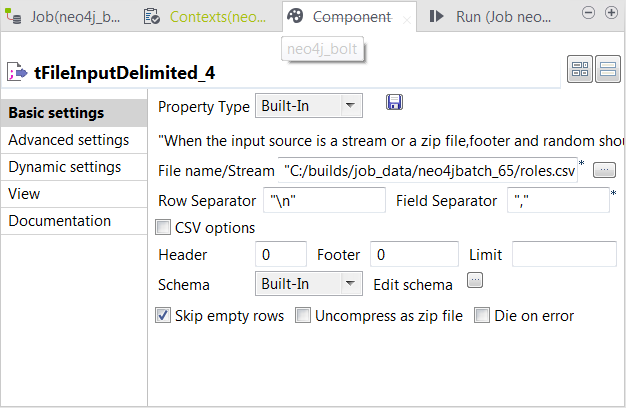
Double-click the third tFileInputDelimited component to open its Component view.
-
In the File name/Stream field, enter the path or browse to the CSV file that describes the actor-movie relationships.
The input CSV file used in this example reads as follows:
123456789keanu,"Neo",tt0133093,ACTED_INkeanu,"Neo",tt0234215,ACTED_INkeanu,"Neo",tt0242653,ACTED_INlaurence,"Morpheus",tt0133093,ACTED_INlaurence,"Morpheus",tt0234215,ACTED_INlaurence,"Morpheus",tt0242653,ACTED_INcarrieanne,"Trinity",tt0133093,ACTED_INcarrieanne,"Trinity",tt0234215,ACTED_INcarrieanne,"Trinity",tt0242653,ACTED_INThe double quotation marks on the role names are not mandatory. The value
ACTED_IN is an user-defined relationship type
that explains the relationship between the actors and the movies. -
Click the […] button next to Edit schema to open the schema editor, and define the input schema based on
the structure of the input file.In this example, the columns are from,
role, to and
type.
-
Click OK to close this editor and accept the propagation
of the schema to the next component. -
In the Field separator field, enter a comma (,) to
replace the default semicolon (;). -
Double-click the tNeo4jBatchOutputRelationship component
to open its Component view.
-
Select the Use an existing connection
check box to reuse the Neo4j database connection opened by the tNeo4jConnection component. - Verify that the Shutdown after Job check box is clear.
-
From the Field for relationship type drop-down list,
select the column that provides the relationship types. -
From the Direction of the relationship drop-down list,
select Outgoing. -
In the Start node of the relationship area, select the
tNeo4jBatchOutput component that provides the index of
the start nodes, which is the asActors index in this
example from the first tNeo4jBatchOutput. Then from the
Field name for the batch index drop-down list, select the
column that provides the actor names as the start nodes. -
Repeat this action in the End node of the relationship
area to select the asMovie index from the second
tNeo4jBatchOutput and then select the column that provides
the movie names as the end nodes.
Adding uniqueness constraints on the nodes
-
Double-click the tNeo4jBatchSchema component
to open its Component view.
-
Select the Use an existing connection
check box to reuse the Neo4j database connection opened by the tNeo4jConnection component. - Select the Shutdown after Job check box to properly close the connection after the execution.
-
In the Schema definition table, add two rows by clicking the [+] button twice:
-
In the Schema type column, select
Node property is unique for both of the rows to
add uniqueness constraints to nodes in Neo4j. - In the For node with Label column, enter, within double quotation marks, Actor and Movie respectively, which are the labels used by the actor nodes and the movie nodes. Therefore, what you enter here must be identical with the labels previously used when creating those nodes.
-
In the On property column, enter, within double
quotation marks, the node properties to which you need to add uniqueness
constraints. For the actor nodes, enter name and
for the movie nodes, enter title. The values you
enter here must be identical with the column names previously defined to
provide actor names and movie names for the nodes to be created by the
tNeo4jBatchOutput components.
-
In the Schema type column, select
-
Press Ctrl+S to save the Job, and press
F6 or click Run on the Run tab to execute
the Job.