tPaloCubeList
Retrieves a list of cube details from the given Palo database.
This component lists cube names, cube types, number of assigned
dimensions, the number of filled cells from the given database.
Discovering the read-only output schema of tPaloCubeList
The below table presents information related to the read-only schema of the tPaloCubeList component.
|
Column |
Type |
Description |
|---|---|---|
|
Cube_id |
int |
Internal id of the cube. |
|
Cube_name |
string |
Name of the cube. |
|
Cube_dimensions |
int |
Number of dimensions inside the cube. |
|
Cube_cells |
long |
Number of calculated cells inside the cube. |
|
Cube_filled_cells |
long |
Number of filled cells inside the cube. |
|
Cube_status |
int |
Status of the cube. It may be: – 0: unloaded – 1: loaded – 2: changed |
|
Cube_type |
int |
Type of the cube. It may be: – 0: normal – 1: system – 2: attribute – 3: user info – 4. gpu type |
tPaloCubeList Standard properties
These properties are used to configure tPaloCubeList running in the Standard Job framework.
The Standard
tPaloCubeList component belongs to the Business Intelligence family.
The component in this framework is available in all Talend
products.
Basic settings
|
Use an existing connection |
Select this check box and in the Component List click the relevant connection component to Note that when a Job contains the parent Job and the child Job, |
|
Host Name |
Enter the host name or the IP address of the host server. |
|
Server Port |
Type in the listening port number of the Palo server. |
|
Username and |
Enter the Palo user authentication data. To enter the password, click the […] button next to the |
|
Database |
Type in the name of the database whose cube details you want to |
Advanced settings
|
tStat |
Select this check box to collect log data at the component |
Global Variables
|
Global Variables |
NB_CUBES: the number of cubes. This is an After variable
CUBEID: the ID of the cube. This is a Flow variable and
CUBENAME: the name of the cube. This is a Flow variable
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component can be used as a start component. It requires an |
|
Connections |
Outgoing links (from this component to another): Row: Main, Iterate;
Trigger: Run if; On Subjob Ok; On Incoming links (from one component to this one): Row: Iterate
Trigger: Run if; On Subjob Ok; On For further information regarding connections, see |
|
Limitation |
The output schema is fixed and read-only. Due to license incompatibility, one or more JARs required to use |
Retrieving detailed cube information from a given database
The Job in this scenario retrieves detailed information of the cubes pertaining to the
demo Palo database, Biker.

To replicate this scenario, proceed as follows:
Setting up the Job
- Drop tPaloCubeList and tLogRow from the component Palette onto the design workspace.
-
Right-click tPaloCubeList to open the
contextual menu. - From this menu, select Row > Main to link the two components.
Configuring the tPaloCube component
-
Double-click the tPaloCube component to
open its Component view.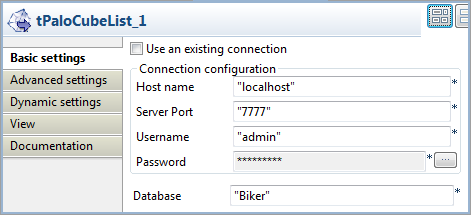
-
In the Host name field, type in the host
name or the IP address of the host server, localhost
for this example. -
In the Server Port field, type in the
listening port number of the Palo server. In this scenario, it is
7777. -
In the Username field and the Password field, type in the authentication
information. In this example, both of them are
admin. -
In the Database field, type in the
database name in which you want to create the cube,
Biker in this example.
Job execution
Press F6 to run the Job.
The cube details are retrieved from the Biker database and
are listed in the console of the Run view.

For further information about how to inteprete the cube details listed in the
console, see Discovering the read-only output schema of tPaloCubeList.