tS3Configuration
Reuses the connection configuration to S3N or S3A in the same Job. The Spark
cluster to be used reads this configuration to eventually connect to S3N (S3 Native
Filesystem) or S3A.
Only one tS3Configuration component is allowed per Job.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Spark Batch: see tS3Configuration properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tS3Configuration properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tS3Configuration properties for Apache Spark Batch
These properties are used to configure tS3Configuration running in the Spark
Batch Job framework.
The Spark Batch
tS3Configuration component belongs to the Storage family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Access Key |
Enter the access key ID that uniquely identifies an AWS |
||
|
Access Secret |
Enter the secret access key, constituting the security To enter the secret key, click the […] button next to |
||
|
Bucket name |
Enter the bucket name and its folder you need to use. You |
||
|
Temp folder |
Enter the location of the temp folder in S3. This folder |
||
|
Use s3a filesystem |
Select this check box to use the S3A filesystem instead This feature is available when you are using one of the
following distributions with Spark:
|
||
| Inherit credentials from AWS | If you are using the S3A filesystem with EMR, you can select this check box to obtain AWS security credentials from your EMR instance metadata. To use this option, the Amazon EMR cluster must be started and your Job must be running on this cluster. For more information, see Using an IAM Role to Grant Permissions to Applications Running on Amazon EC2 Instances. This option enables you to develop your Job without having to put any |
||
| Use SSE-KMS encryption with CMK | If you are using the S3A filesystem with EMR, you can select this check box to use the SSE-KMS encryption service enabled on AWS to read or write the encrypted data on S3. On the EMR side, the SSE-KMS service must have been enabled with the For further information about the AWS SSE-KMS encryption, see Protecting Data Using Server-Side For further information about how to enbale the Default Encryption feature for an |
||
| Use S3 bucket policy | If you have defined bucket policy for the bucket to be used, select this check box and add the following parameter about AWS signature versions to the JVM argument list of your Job in the Advanced settings of the Run tab:
|
||
|
Assume Role |
If you are using the S3A filesystem, you can select this check box to Ensure that access to this role has been After selecting this check box, specify the parameters the
administrator of the AWS system to be used defined for this role.
The External ID In addition, if the AWS administrator has enabled the STS endpoints for This check box is available only for the following distributions
Talend supports:
This check box is also available when you are using Spark V1.6 and |
||
|
Set region |
Select this check box and select the region to connect This feature is available when you are using one of the
following distributions with Spark:
|
||
|
Set endpoint |
Select this check box and in the Endpoint field that is displayed, enter the Amazon If you leave this check box clear, the endpoint will be This feature is available when you are using one of the
following distributions with Spark:
|
Advanced settings
|
Set STS region and Set STS endpoint |
If the AWS administrator has enabled the STS endpoints for the regions If the endpoint you want to use is not available in this regional This service allows you to request temporary, For a list of the STS endpoints you can use, see These check boxes are available only when you have selected the |
Usage
|
Usage rule |
This component is used with no need to be connected to other You need to drop tS3Configuration along with the file system related Subjob to be |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
|
Limitation |
Due to license incompatibility, one or more JARs required to use |
Creating an IAM role on AWS
- You have the appropriate rights and permissions to create a new role on AWS.
- Log in to your account on AWS and navigate to the AWS console.
- Select IAM.
- In the navigation pane of the IAM console, select Roles, and then select Create role.
- Select AWS service and in the Choose the service that will use this role section, select the AWS service to be run with your Job. For example, select Redshift.
-
Select the use case to be used for this service. An use case in terms of AWS is defined by the service to include the trust policy that this service requires. Depending on the service and the use case that you selected, the available options vary. For example, with Redshift, you can choose an use case from:
- Redshift (with a pre-defined Amazon Redshift
Service Linked Role Policy); - Redshift – Customizable. In this use case, you are prompted to select either read-only policies or full-access policies.
- Redshift (with a pre-defined Amazon Redshift
- In the Role name field, enter the name to be used for the role being created.
- Select Create role.
full documentation about creating a role on AWS, see Role creation from the AWS
documentation.
Setting up SSE KMS for your EMR cluster
SSE KMS related operations for getting started with the security configuration for EMR.
If you need the complete information about all the available EMR security configurations
provided by AWS, see Create a Security Configuration from the
Amazon documentation.
-
If not yet done, go to https://console.aws.amazon.com/kms
to create a customer managed CMK to be used by the SSE KMS service. For detailed
instructions about how to do this, see this tutorial from the AWS
documentation.-
When adding roles, among other roles to be added depending on your
security policy, you must add the EMR_EC2_DefaultRole role.The EMR_EC2_DefaultRole role allows your
Jobs for Apache Spark to read or write files encrypted with SSE-KMS on
S3.This role is a default AWS role that is
automatically created along with the creation of your first EMR
cluster. If this role and its associated policies do not exist in
your account, see Use Default IAM Roles and
Managed Policies from the AWS documentation
-
-
On the Amazon EMR page of
AWS, select the Security configurations
tab and click Create to open the
Create security configuration
view. -
Select the At-rest encryption check box
to enable SSE KMS. -
Under S3 data encryption, select
SSE-KMS for Encryption mode
and select the CMK key mentioned at the beginning of this procedure for
AWS KMS Key. -
Under Local disk encryption, select AWS
KMS for Key provider type and select the
CMK key mentioned at the beginning of this procedure for AWS KMS
Key.
-
Click Create to validate your security configuration.
In the real-world practice, you can also configure the other security options such as Kerberos and IAM roles for EMRFS before clicking this Create button.
- Click Clusters and once the Create Cluster page is open, click Go to advanced options to start creating the EMR cluster step by step.
-
At the last step called Security, in the Authentication and
encryption section, select the Security Configuration created in the previous steps.
Setting up SSE KMS for your S3 bucket
instructions about how to do this, see this tutorial from the AWS
documentation.
SSE KMS related operations for getting started with the security configuration for EMR.
If you need the complete information about all the available EMR security configurations
provided by AWS, see Create a Security Configuration from the
Amazon documentation.
- Open your S3 service at https://s3.console.aws.amazon.com/.
-
From the S3 bucket list, select the bucket to be used. Ensure
that you have proper rights and permissions to access this bucket. -
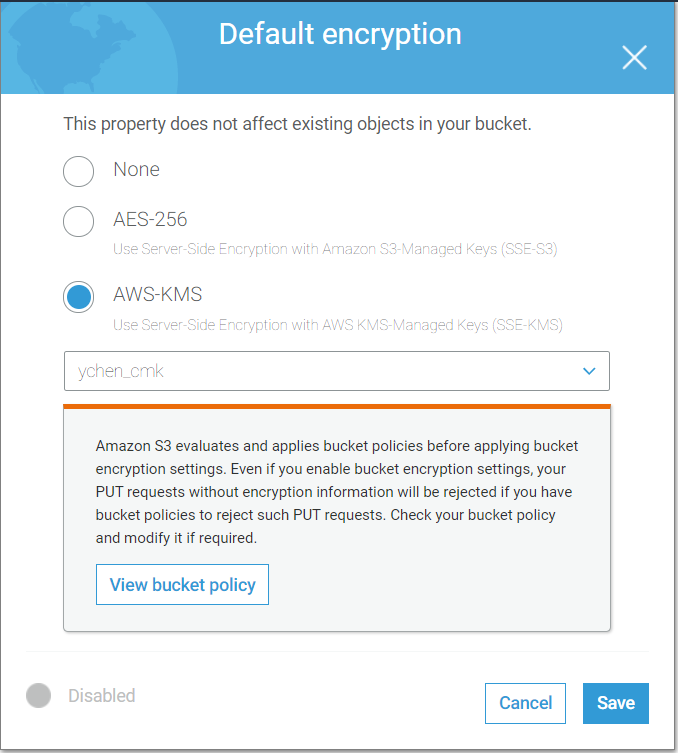
Select the Properties tab
and then Default encryption. - Select AWS-KMS.
-
Select the KMS CMK key to be used.
-
Select the Permissions tab, then select
Bucket Policy and enter your policy in the
console.This article from AWS provides detailed explanations and a simple policy
example: How to Prevent Uploads of Unencrypted Objects
to Amazon S3. - Click Save to save your policy.
the following parameter about AWS signature versions to the JVM argument list of this Job:
|
1 2 |
-Dcom.amazonaws.services.s3.enableV4 |

For further information about AWS Signature Versions, see Specifying the Signature Version in Request
Authentication.
Writing and reading data from S3 (Databricks on AWS)
In this scenario, you create a Spark Batch Job using
tS3Configuration and the Parquet components to write data on
S3 and then read the data from S3.
This scenario applies only to subscription-based Talend products with Big
Data.

follows:
|
1 |
01;ychen |
This data contains a user name and the ID number distributed to this user.
Note that the sample data is created for demonstration purposes only.
Design the data flow of the Job working with S3 and Databricks on AWS
-
In the
Integration
perspective of the Studio, create an empty
Spark Batch Job from the Job Designs node in
the Repository tree view. -
In the workspace, enter the name of the component to be used and select this
component from the list that appears. In this scenario, the components are
tS3Configuration,
tFixedFlowInput,
tFileOutputParquet,
tFileInputParquet and
tLogRow.The tFixedFlowInput component is used to load the
sample data into the data flow. In the real-world practice, you could use the
File input components, as well as the processing components, to design a
sophisticated process to prepare your data to be processed. - Connect tFixedFlowInput to tFileOutputParquet using the Row > Main link.
- Connect tFileInputParquet to tLogRow using the Row > Main link.
- Connect tFixedFlowInput to tFileInputParquet using the Trigger > OnSubjobOk link.
-
Leave tS3Configuration alone without any
connection.
Defining the Databricks-on-AWS connection parameters for Spark Jobs
configuration tab of the Run view of your Job.
This configuration is effective on a per-Job basis.
-
- When running a Spark Streaming Job, only one Job is allowed to run on the same Databricks cluster per time.
- When running a Spark Batch Job, only if you have selected the Do not restart the cluster
when submitting check box, you can send more than one Job to run in parallel on the same Databricks cluster; otherwise, since each run
automatically restarts the cluster, the Jobs that are launched in parallel interrupt
each other and thus cause execution failure.
- Ensure that the AWS account to be used has the proper read/write permissions to the S3 bucket to be used. For this purpose, contact the administrator of your AWS system.
|
Standalone |
|
If you need the Job to be resilient to failure, select the Activate checkpointing check box to enable the
Spark checkpointing operation. In the field that is displayed, enter the
directory in which Spark stores, in the file system of the cluster, the context
data of the computations such as the metadata and the generated RDDs of this
computation.
For further information about the Spark checkpointing operation, see http://spark.apache.org/docs/latest/streaming-programming-guide.html#checkpointing .
Configuring the connection to the S3 service to be used by Spark
-
Double-click tS3Configuration to open its Component view.
Spark uses this component to connect to the S3 system in which your Job writes
the actual business data. If you place neither
tS3Configuration nor any other configuration
component that supports Databricks on AWS, this business data is written in the
Databricks Filesystem (DBFS).
-
In the Access key and the Secret
key fields, enter the keys to be used to authenticate to
S3. -
In the Bucket name field, enter the name of the bucket
and the folder in this bucket to be used to store the business data, for
example, mybucket/myfolder. This folder is created on the
fly if it does not exist but the bucket must already exist at runtime.
Write the sample data to S3
-
Double-click the tFixedFlowIput component to
open its Component view.
- Click the […] button next to Edit schema to open the schema editor.
-
Click the [+] button to add the schema
columns as shown in this image.
-
Click OK to validate these changes and accept
the propagation prompted by the pop-up dialog box. -
In the Mode area, select the Use Inline
Content radio button and paste the previously mentioned sample data
into the Content field that is displayed. -
In the Field separator field, enter a
semicolon (;). -
Double-click the tFileOutputParquet component to
open its Component view.
-
Select the Define a storage configuration component
check box and then select the tS3Configuration component
you configured in the previous steps. -
Click Sync columns to ensure that
tFileOutputParquet has the same schema as
tFixedFlowInput. -
In the Folder/File field, enter the name of the S3
folder to be used to store the sample data. For example, enter
/sample_user, then as you have specified
my_bucket/my_folder to use in
tS3Configuration to store the business data on S3,
the eventual directory on S3 becomes
my_bucket/my_folder/sample_user. -
From the Action drop-down list, select
Create if the sample_user folder
does not exist yet; if this folder already exists, select
Overwrite.
Reading the sample data from S3
-
Double-click tFileInputParquet to open its
Component view.
-
Select the Define a storage configuration component
check box and then select the tS3Configuration
component you configured in the previous steps. -
Click the […] button next to Edit
schema to open the schema editor. -
Click the [+] button to add the schema columns for
output as shown in this image.
-
Click OK to validate these changes and accept the
propagation prompted by the pop-up dialog box. -
In the Folder/File field, enter the name of the folder
from which you need to read data. In this scenario, it is
sample_user. -
Double click tLogRow to open its
Component view and select the Table radio button to present the result in a table. - Press F6 to run this Job.
of your Databricks cluster and then check the execution log of your Job.

Writing server-side KMS encrypted data on EMR
If the AWS SSE-KMS encryption (at-rest encryption) service is
enabled to set Default encryption to protect data
on the S3A system of your EMR cluster, select the SSE-KMS option in tS3Configuration when writing data to that S3A
system.
incidents that people reported occurring on Paris streets within one
day.
|
1 2 3 4 5 |
1;226 rue marcadet, 75018 Paris;abandoned object;garbage on the street 2;2 rue marcadet, 75018 Paris;shift and damage;direction sign damaged 3;45 boulevard de la villette, 75010 Paris; abandoned object; suspicious package 4;10 rue emile lepeu, 75011 Paris;graffiti and improper poster;graffiti 5;27 avenue emile zola, 75015 Paris;shift and damage;deformed road |
The sample data is used for demonstration purposes only.
The Job calculates the occurrence of each incident type.
- The S3 system to be used is S3A.
- The SSE-KMS encryption service on AWS is enabled with the
Default encryption feature and a
customer managed CMK has been specified for it. - The EMR cluster to be used is created with SSE-KMS and the
EMR_EC2_DefaultRole role has been added to the above-mentioned CMK. - The administrator of your EMR cluster has granted the appropriate
rights and permissions to the AWS account you are using in your Jobs. - Your EMR cluster has been properly set up and is running.
- A Talend
Jobserver has been deployed on an instance within the network of your EMR
cluster, such as the instance for the master of your cluster.
- In your Studio or in Talend Administration Center, define this Jobserver as the execution server of your
Jobs.
Ensure that the client machine on which the Talend Jobs are executed can
recognize the host names of the nodes of the Hadoop cluster to be used. For this purpose, add
the IP address/hostname mapping entries for the services of that Hadoop cluster in the
hosts file of the client machine.
If this is the first time your EMR cluster is set up to run with Talend Jobs, search for Amazon EMR –
Getting Started on Talend Help Center (https://help.talend.com) to verify your setup so as to help your
Jobs work more efficiently on top of EMR.
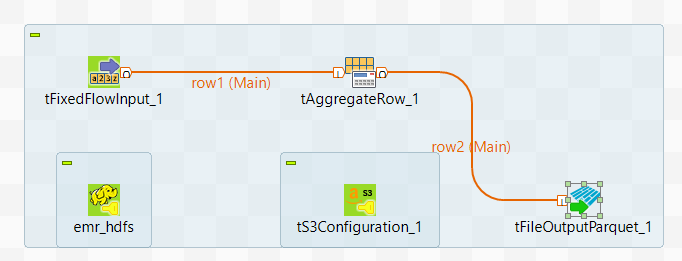
Designing the flow of the data to write and encrypt onto EMR
-
In the
Integration
perspective of the Studio, create an empty Spark Batch Job from the Job
Designs node in the Repository tree view. -
In the workspace, enter the name of the component to be used and select this
component from the list that appears. In this scenario, the components are
tHDFSConfiguration (labeled emr_hdfs), tS3Configuration, tFixedFlowInput, tAggregateRow and tFileOutputParquet.The tFixedFlowInput component is used to load
the sample data into the data flow. In the real-world practice, use the input component specific to the data format or the source system to be used instead of tFixedFlowInput. -
Connect tFixedFlowInput, tAggregateRow and
tFileOutputParquet using the Row > Main link. -
Leave the tHDFSConfiguration component and the tS3Configuration component alone
without any connection.
Configuring the connection to the HDFS file system of your EMR
cluster
-
Double-click tHDFSConfiguration to open its Component view.
Spark uses this component to connect to the HDFS system to
which the jar files dependent on the Job are transferred. -
If you have defined the HDFS connection metadata under the
Hadoop cluster node in Repository, select Repository from the Property
type drop-down list and then click the […] button to select the HDFS connection you
have defined from the Repository content
wizard.For further information about setting up a reusable HDFS
connection, search for centralizing HDFS metadata on Talend Help Center (https://help.talend.com).If you complete this step, you can skip the following steps
about configuring tHDFSConfiguration
because all the required fields should have been filled automatically. -
In the Version area,
select the Hadoop distribution you need to connect to and its version. -
In the NameNode URI
field, enter the location of the machine hosting the NameNode service of the
cluster. If you are using WebHDFS, the location should be
webhdfs://masternode:portnumber; WebHDFS with SSL is not
supported yet. -
In the Username field,
enter the authentication information used to connect to the HDFS system to be
used. Note that the user name must be the same as you have put in the Spark configuration tab.
Configuring the connection to S3 to be used to store the business data
-
Double-click tS3Configuration to open its Component view.
Spark uses this component to connect to the S3 system to which the business data is stored. In this scenario, the sample data about the street incidents is written and ecrypted on S3.
- Select the Use s3a Filesystem check box. The Inherit credentials from AWS role check box and the use SSE-KMS encryption
-
Enter the access credentials of the AWS account to be used.
- If allowed by the security policy of your organization, in the Access Key and the Secret Key fields, enter the credentials.
If you do not know the credentials to be used, contact the administrator of your AWS system or check Getting Your AWS Access
Keys from the AWS documentation. - If the security policy of your organization does not allow you to expose the credentials in a client application, select Inherit credentials from AWS role to obtain the role-based temporary AWS security credentials from your EMR instance metadata. An IAM role must have been specified to associate with this EMR instance.
For further information about using an IAM role to grant permissions, see Using IAM roles from the AWS documentation.
- If allowed by the security policy of your organization, in the Access Key and the Secret Key fields, enter the credentials.
- Select Use SSE-KMS encryption check box to enable the Job to verify and use the SSE-KMS encryption service of your cluster.
- In the Bucket name field, enter the name of the bucket to be used to store the sample data. This bucket must have existed when you launch your Job. For example, enter my_bucket/my_folder.
Loading the sample data about street incidents to the Job.
-
Double-click tFixedFlowInput to display its
Basic settings view.
-
Click the […] button next to Edit
Schema to open the schema editor.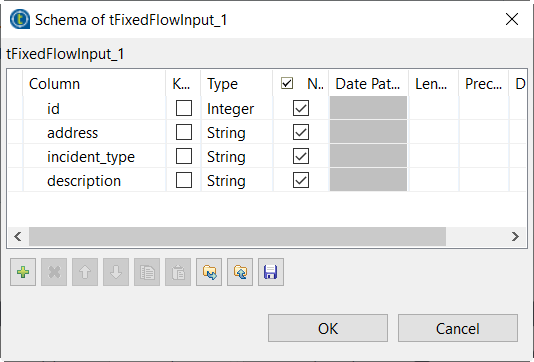
-
Click the [+] button to add four columns, namely
id, address,
incident_type and description. -
Click Ok to close the schema editor and accept
propagating the changes when prompted by the system. - In the Mode area, select the Use Inline Content(delimited file) radio button to display the Content area and enter the sample data.
Calculating the incident occurrence
-
Double-click tAggregateRow to open its
Component view.
- Click the […] button next to Edit schema to open the schema editor.
-
On the output side (right), click the [+]
button twice to add two rows and in the Column column, rename them to incident_type and incident_number, respectively.
- In the Type column of the incident_number row of the output side, select Integer.
-
Click OK to validate these changes and accept
the propagation prompted by the pop-up dialog box. -
In the Group by table, add one row by
clicking the [+] button and configure
this row as follows to group the outputted data:-
Output column:
select the columns from the output schema to be used as the
conditions to group the outputted data. In this example, it is the
incident_type from the output schema. -
Input column
position: select the columns from the input schema
to send data to the output columns you have selected in the
Output
column column. In this scenario, it is the
incident_type column from the input schema.
-
-
In the Operations table, add one row by clicking the [+] button once and configure this
row as follows to calculate the occurrence of each incident type:-
Output column:
select the column from the output schema to store the calculation
results. In this scenario, it is incident_number. -
Function: select
the function to be used to process the incoming data. In this
scenario, select count. It counts the frequency of each
incident. -
Input column
position: select the column from the input schema to
provide the data to be processed. In this scenario, it is incident_type.
-
Writing the aggregated data about street incidents to EMR
-
Double-click the tFileOutputParquet component to
open its Component view.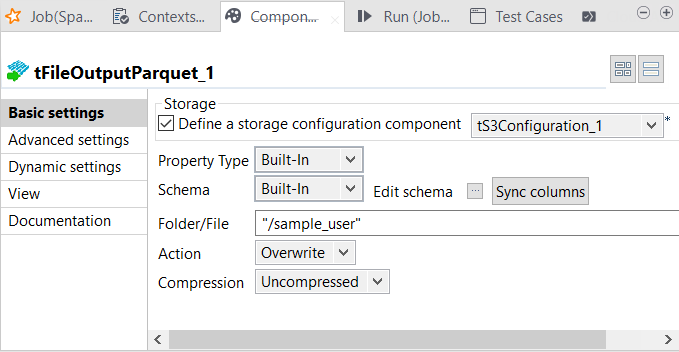
-
Select the Define a storage
configuration component check box and then select the tS3Configuration component you configured in the
previous steps. -
Click Sync columns to
ensure that tFileOutputParquet retrieve the
schema from the output side of tAggregateRow. -
In the Folder/File
field, enter the name of the folder to be used to store the aggregated data in
the S3 bucket specified in tS3Configuration. For example,
enter /sample_user, then at runtime, the folder called
sample_user at the root of the bucket is used to
store the output of your Job. -
From the Action
drop-down list, select Create if the
folder to be used does not exist yet in the bucket to be used; if this folder
already exists, select Overwrite. -
Click Run to open its view and then click the
Spark Configuration tab to display its view
for configuring the Spark connection. -
Select the Use local mode check box to test your Job locally before eventually submitting it to the remote Spark cluster.
In the local mode, the Studio builds the Spark environment in itself on the fly in order to
run the Job in. Each processor of the local machine is used as a Spark
worker to perform the computations. -
In this mode, your local file system is used; therefore, deactivate the
configuration components such as tS3Configuration or
tHDFSConfiguration that provides connection
information to a remote file system, if you have placed these components
in your Job. - In the Component view of tFileOutputParquet, change the file path in the Folder/File field to a local directory and adapt the action to be taken on the Action drop-down list, that is to say, creating a new folder or overwriting the existing one.
-
On the Run tab, click Basic
Run and in this view, click Run to execute your Job locally to test its design
logic. -
When your Job runs successfully, clear the Use local
mode check box in the Spark Configuration
view of the Run tab, then in the design workspace of your
Job, activate the configuration components and revert the changes you just made
in tFileOutputParquet for the local test.
Defining the EMR connection parameters
configuration tab of the Run view of your Job.
This configuration is effective on a per-Job basis.
-
Enter the basic connection information to EMR:
Yarn client
The Studio runs the Spark driver to orchestrate how the Job should be
performed and then send the orchestration to the Yarn service of a given
Hadoop cluster so that the Resource Manager of this Yarn service
requests execution resources accordingly.If you are using the Yarn client
mode, you need to set the following parameters in their corresponding
fields (if you leave the check box of a service clear, then at runtime,
the configuration about this parameter in the Hadoop cluster to be used
will be ignored):-
In the Resource managerUse datanode
field, enter the address of the ResourceManager service of the Hadoop cluster to
be used. -
Select the Set resourcemanager
scheduler address check box and enter the Scheduler address in
the field that appears. -
Select the Set jobhistory
address check box and enter the location of the JobHistory
server of the Hadoop cluster to be used. This allows the metrics information of
the current Job to be stored in that JobHistory server. -
Select the Set staging
directory check box and enter this directory defined in your
Hadoop cluster for temporary files created by running programs. Typically, this
directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files
such as yarn-site.xml or mapred-site.xml of your distribution. -
If you are accessing the Hadoop cluster running with Kerberos security,
select this check box, then, enter the Kerberos principal names for the
ResourceManager service and the JobHistory service in the displayed fields. This
enables you to use your user name to authenticate against the credentials stored in
Kerberos. These principals can be found in the configuration files of your
distribution, such as in yarn-site.xml and in mapred-site.xml.If you need to use a Kerberos keytab file to log in, select Use a keytab to authenticate. A keytab file contains
pairs of Kerberos principals and encrypted keys. You need to enter the principal to
be used in the Principal field and the access
path to the keytab file itself in the Keytab
field. This keytab file must be stored in the machine in which your Job actually
runs, for example, on a Talend
Jobserver.Note that the user that executes a keytab-enabled Job is not necessarily
the one a principal designates but must have the right to read the keytab file being
used. For example, the user name you are using to execute a Job is user1 and the principal to be used is guest; in this
situation, ensure that user1 has the right to read the keytab
file to be used. -
The User name field is available when you are not using
Kerberos to authenticate. In the User name field, enter the
login user name for your distribution. If you leave it empty, the user name of the machine
hosting the Studio will be used. -
If the Spark cluster cannot recognize the machine in which the Job is
launched, select this Define the driver hostname or IP
address check box and enter the host name or the IP address of
this machine. This allows the Spark master and its workers to recognize this
machine to find the Job and thus its driver.Note that in this situation, you also need to add the name and the IP
address of this machine to its host file.
Yarn cluster
The Spark driver runs in your Yarn cluster to orchestrate how the Job
should be performed.If you are using the Yarn cluster mode, you need
to define the following parameters in their corresponding fields (if you
leave the check box of a service clear, then at runtime, the
configuration about this parameter in the Hadoop cluster to be used will
be ignored):-
In the Resource managerUse datanode
field, enter the address of the ResourceManager service of the Hadoop cluster to
be used. -
Select the Set resourcemanager
scheduler address check box and enter the Scheduler address in
the field that appears. -
Select the Set jobhistory
address check box and enter the location of the JobHistory
server of the Hadoop cluster to be used. This allows the metrics information of
the current Job to be stored in that JobHistory server. -
Select the Set staging
directory check box and enter this directory defined in your
Hadoop cluster for temporary files created by running programs. Typically, this
directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files
such as yarn-site.xml or mapred-site.xml of your distribution. -
Set path to custom Hadoop
configuration JAR: if you are using
connections defined in Repository to
connect to your Cloudera or Hortonworks cluster, you can
select this check box in the
Repository wizard and in the
field that is displayed, specify the path to the JAR file
that provides the connection parameters of your Hadoop
environment. Note that this file must be accessible from the
machine where you Job is launched.This kind of Hadoop configuration JAR file is
automatically generated when you build a Big Data Job from the
Studio. This JAR file is by default named with this
pattern:You1hadoop-conf-[name_of_the_metadata_in_the_repository]_[name_of_the_context].jar
can also download this JAR file from the web console of your
cluster or simply create a JAR file yourself by putting the
configuration files in the root of your JAR file. For
example:12hdfs-sidt.xmlcore-site.xmlThe parameters from your custom JAR file override the parameters
you put in the Spark configuration field.
They also override the configuration you set in the
configuration components such as
tHDFSConfiguration or
tHBaseConfiguration when the related
storage system such as HDFS, HBase or Hive are native to Hadoop.
But they do not override the configuration set in the
configuration components for the third-party storage system such
as tAzureFSConfiguration. -
If you are accessing the Hadoop cluster running with Kerberos security,
select this check box, then, enter the Kerberos principal names for the
ResourceManager service and the JobHistory service in the displayed fields. This
enables you to use your user name to authenticate against the credentials stored in
Kerberos. These principals can be found in the configuration files of your
distribution, such as in yarn-site.xml and in mapred-site.xml.If you need to use a Kerberos keytab file to log in, select Use a keytab to authenticate. A keytab file contains
pairs of Kerberos principals and encrypted keys. You need to enter the principal to
be used in the Principal field and the access
path to the keytab file itself in the Keytab
field. This keytab file must be stored in the machine in which your Job actually
runs, for example, on a Talend
Jobserver.Note that the user that executes a keytab-enabled Job is not necessarily
the one a principal designates but must have the right to read the keytab file being
used. For example, the user name you are using to execute a Job is user1 and the principal to be used is guest; in this
situation, ensure that user1 has the right to read the keytab
file to be used. -
The User name field is available when you are not using
Kerberos to authenticate. In the User name field, enter the
login user name for your distribution. If you leave it empty, the user name of the machine
hosting the Studio will be used. -
Select the Wait for the Job to complete check box to make your Studio or,
if you use Talend
Jobserver, your Job JVM keep monitoring the Job until the execution of the Job
is over. By selecting this check box, you actually set the spark.yarn.submit.waitAppCompletion property to be true. While
it is generally useful to select this check box when running a Spark Batch Job,
it makes more sense to keep this check box clear when running a Spark Streaming
Job.
Ensure that the user name in the Yarn
client mode is the same one you put in
tS3Configuration, the component used to provides S3
connection information to Spark. -
-
With the Yarn client mode, the
Property type list is displayed to allow you
to select an established Hadoop connection from the Repository, on the condition that you have created this connection
in the Repository. Then the Studio will reuse
that set of connection information for this Job.
-
If you need to launch from Windows, it is recommended to specify where
the winutils.exe program to be used is stored.
-
If you know where to find your winutils.exe file and you want to use it, select the Define the Hadoop home directory check box
and enter the directory where your winutils.exe is
stored. -
Otherwise, leave this check box clear, the Studio generates one
by itself and automatically uses it for this Job.
-
-
In the Spark “scratch” directory
field, enter the directory in which the Studio stores in the local system the
temporary files such as the jar files to be transferred. If you launch the Job
on Windows, the default disk is C:. So if you leave /tmp in this field, this directory is C:/tmp.
-
After the connection is configured, you can tune
the Spark performance, although not required, by following the process explained in:-
for Spark Batch Jobs.
-
for Spark Streaming Jobs.
-
-
It is recommended to activate the Spark logging and
checkpointing system in the Spark configuration tab of the Run view of your Spark
Job, in order to help debug and resume your Spark Job when issues arise:-
.
-
Running the Job to write KMS encrypted data to EMR
- Press Ctrl+S to save your Job.
- In the Run tab, click Run to execute the Job.
tS3Configuration properties for Apache Spark Streaming
These properties are used to configure tS3Configuration running in the Spark Streaming Job framework.
The Spark Streaming
tS3Configuration component belongs to the Storage family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Access Key |
Enter the access key ID that uniquely identifies an AWS |
||
|
Access Secret |
Enter the secret access key, constituting the security To enter the secret key, click the […] button next to |
||
|
Bucket name |
Enter the bucket name and its folder you need to use. You |
||
|
Use s3a filesystem |
Select this check box to use the S3A filesystem instead This feature is available when you are using one of the
following distributions with Spark:
|
||
| Inherit credentials from AWS | If you are using the S3A filesystem with EMR, you can select this check box to obtain AWS security credentials from your EMR instance metadata. To use this option, the Amazon EMR cluster must be started and your Job must be running on this cluster. For more information, see Using an IAM Role to Grant Permissions to Applications Running on Amazon EC2 Instances. This option enables you to develop your Job without having to put any |
||
| Use SSE-KMS encryption with CMK | If you are using the S3A filesystem with EMR, you can select this check box to use the SSE-KMS encryption service enabled on AWS to read or write the encrypted data on S3. On the EMR side, the SSE-KMS service must have been enabled with the For further information about the AWS SSE-KMS encryption, see Protecting Data Using Server-Side For further information about how to enbale the Default Encryption feature for an |
||
| Use S3 bucket policy | If you have defined bucket policy for the bucket to be used, select this check box and add the following parameter about AWS signature versions to the JVM argument list of your Job in the Advanced settings of the Run tab:
|
||
|
Assume Role |
If you are using the S3A filesystem, you can select this check box to Ensure that access to this role has been After selecting this check box, specify the parameters the
administrator of the AWS system to be used defined for this role.
The External ID In addition, if the AWS administrator has enabled the STS endpoints for This check box is available only for the following distributions
Talend supports:
This check box is also available when you are using Spark V1.6 and |
||
|
Set region |
Select this check box and select the region to connect This feature is available when you are using one of the
following distributions with Spark:
|
||
|
Set endpoint |
Select this check box and in the Endpoint field that is displayed, enter the Amazon If you leave this check box clear, the endpoint will be This feature is available when you are using one of the
following distributions with Spark:
|
Advanced settings
|
Set STS region and Set STS endpoint |
If the AWS administrator has enabled the STS endpoints for the regions If the endpoint you want to use is not available in this regional This service allows you to request temporary, For a list of the STS endpoints you can use, see These check boxes are available only when you have selected the |
Usage
|
Usage rule |
This component is used with no need to be connected to other components. You need to drop tS3Configuration along with the file system related Subjob to be |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
|
Limitation |
Due to license incompatibility, one or more JARs required to use |