tSnowflakeRow
tSnowflakeRow Standard properties
These properties are used to configure tSnowflakeRow running in
the Standard Job framework.
The Standard
tSnowflakeRow component belongs to the Cloud
family.
connector. The properties related to database settings vary depending on your database
type selection. For more information about dynamic database connectors, see Dynamic database components.
Basic settings
| Database |
Select a type of database from the list and click |
|
Property Type |
Select the way the connection details
This property is not available when other connection component is selected |
|
Connection Component |
Select the component that opens the database connection to be reused by this |
|
Account |
In the Account field, enter, in double quotation marks, the account name |
|
User Id and Password |
Enter, in double quotation marks, your authentication
|
|
Warehouse |
Enter, in double quotation marks, the name of the |
| Schema |
Enter, within double quotation marks, the name of the |
|
Database |
Enter, in double quotation marks, the name of the |
|
Table |
Click the […] button and in the displayed wizard, select the Snowflake |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields Built-In: You create and store the schema locally for this component Repository: You have already created the schema and stored it in the If the Snowflake data type to Click Edit
This This |
|
Guess Query |
Click the button to generate the query which corresponds to the table and the |
|
Query |
Specify the SQL command to be executed. For more information about Snowflake SQL commands, see SQL Command Reference. |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the When errors are skipped, you can collect the rows on error |
Advanced settings
| Additional JDBC Parameters |
Specify additional connection properties for the database connection you are This field is available only when you |
| Use Custom Snowflake Region |
Select this check box to specify a custom
Snowflake region. This option is available only when you select Use This Component from the Connection Component drop-down list in the Basic settings view.
For more information on Snowflake Region |
| Login Timeout |
Specify the timeout period (in minutes) |
|
Tracing |
Select the log level for the Snowflake JDBC driver. If |
|
Role |
Enter, in double quotation marks, the default access This role must already exist and has been granted to the |
|
Propagate QUERYs recordset |
Select this check box to propagate the result of the SELECT query to the output |
|
Use PreparedStatement |
Select this check box if you want to query the database using a prepared statement. In
For a related use case of this property, see Using PreparedStatement objects to query data. |
|
Commit every |
Specify the number of rows to be processed before committing |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the Job level |
Dynamic settings
|
Dynamic settings |
Click the [+] button to add a row in the table For examples on using dynamic parameters, see Reading data from databases through context-based dynamic connections and Reading data from different MySQL databases using dynamically loaded connection parameters. For more information on Dynamic |
Global Variables
|
NB_LINE |
The number of rows processed. This is an After variable and it returns an integer. |
|
ERROR_MESSAGE |
The error message generated by the component when an error occurs. This is an After |
Usage
|
Usage rule |
This component offers the flexibility of the database query and |
Querying data in a cloud file through a Snowflake external table and a materialized
view
-
External tables, which reference data files located in a cloud storage. These
tables stores file-level metadata (such as the filename, a version
identifiers, and other properties) about a data file stored in an external
stage, thus providing users a database table interface for querying the data
in the file. For information about the Snowflake external table feature, see
https://docs.snowflake.net/manuals/user-guide/tables-external-intro.html - Materialized views, which store pre-computed data derived by a query. Since the
data is pre-computed, querying a materialized view is faster than executing the
original query. For information about the Snowflake materialized view feature,
see https://docs.snowflake.net/manuals/user-guide/views-materialized.html.
This scenario describes the way to query data in a file stored in AWS S3 bucket
through a Snowflake external table and a materialized view. It assumes that:
-
You have a valid Amazon S3 user account.
- The data file (log1.json in
this example) is in the logs folder under
your S3 bucket named S3://my-bucket. - You have a valid Snowflake user account.
Querying data in a cloud file through a Snowflake external table
This example describes how to query data stored in a cloud file through a Snowflake
external table.
In this example, the file contains the following records.
|
1 2 3 |
{"id": "1", "name": "Josephine", "address": "Brighton"} {"id": "2", "name": "Leota", "address": "San Jose"} {"id": "3", "name": "Cammy", "address": "Laredo"} |
Creating the Job for querying data through a Snowflake external table
- Create a standard Job.
-
Drop the components listed in the following table onto the
design workspace.A component is assigned a default name automatically in the
format of <component name>_<sequence number> when it is dropped onto
the design workspace. This scenario refers the components in the Jobs using
their default names. The following table also lists the default component names.Component Default component name tDBConnection tDBConnection_1 tDBRow tDRRow_1 tDBRow tDBRow_2 tDBRow tDBRow_3 tDBInput tDBInput_1 tLogRow tLogRow_1 tDBClose tDBClose_1 -
Connect the components:
-
tDBConnection_1
to tDBRow_1 using a Trigger > On Subjob OK connection -
tDBRow_1 to
tDBRow_2 using a Trigger > On Subjob OK connection -
tDBRow_2 to
tDBRow_3 using a Trigger > On Subjob OK connection -
tDBRow_3 to
tDBInput_1 using a
Trigger > On Subjob OK connection -
tDBInput to tLogRow using
a Row > Main connection -
tDBInput_1 to
tDBClose using a Trigger > On Subjob OK connection

-
tDBConnection_1
Configuring the Snowflake external table Job
-
Configure tDBConnection_1 to establish a connection to
Snowflake. In the Basic settings view of the
component:-
Select Snowflake from the
Database list and click
Apply. -
Enter the following Snowflake credential items in the
rest fields:- Snowflake account name in the Account field
- Snowflake region
- Snowflake user ID in the User Id field
- Snowflake account password in the Password field
- Snowflake warehouse
- Snowflake schema
- Snowflake database
-
Select Snowflake from the
-
Configure tDBRow_1 to create a stage referencing the
file S3://my-bucket/logs/log1.json. In the Basic
settings view of the component:-
Select Snowflake from the
Database list and click
Apply; -
Select tDBConnection_1 from the Connection
Component list; -
Enter the following code in double quotation marks in the
Query field.1234CREATE OR REPLACE STAGE <kbd>mystage</kbd>url='s3://my-bucket/logs/'credentials=(aws_key_id='<kbd>your_AWS_key_ID</kbd>' aws_secret_key='<kbd>your_AWS_secret_key</kbd>')file_format = (type = json); - Leave other options as they are.
-
Select Snowflake from the
-
Configure tDBRow_2 to create an external table for the
stage. In the Basic settings view of the component:-
Select Snowflake from the
Database list and click
Apply; -
Select tDBConnection_1 from the Connection
Component list; -
Enter the following code in double quotation marks in the
Query field.1234567CREATE OR REPLACE EXTERNAL TABLE <kbd>logs</kbd> (id varchar as (value:id::varchar),name varchar as (value:name::varchar),city varchar as (value:address::varchar))location=@mystageauto_refresh = truefile_format=(type=json); - Leave other options as they are.
-
Select Snowflake from the
-
Configure tDBRow_3 to refresh the external table using
the S3://logs/log1.json file. In the Basic
settings view of the component:-
Select Snowflake from the
Database list and click
Apply; -
Select tDBConnection_1 from the Connection
Component list; -
Enter the following code in double quotation marks in the
Query field.1ALTER EXTERNAL <kbd>logs</kbd> REFRESH; - Leave other options as they are.
-
Select Snowflake from the
-
Configure tDBInput_1 to query the external table. In
the Basic settings view of the component:-
Select Snowflake from the
Database list and click
Apply; -
Select tDBConnection_1 from the Connection
Component list; -
Enter the following code in double quotation marks in the
Query field.1SELECT id,name,city FROM <kbd>logs</kbd>; -
Click the three-dot button to the right of Edit
schema. Add the following three columns and click
OK to propagate the schema.- ID, type String and Db
Column
ID - Name, type String and Db
Column
NAME - City, type String and Db
Column
CITY
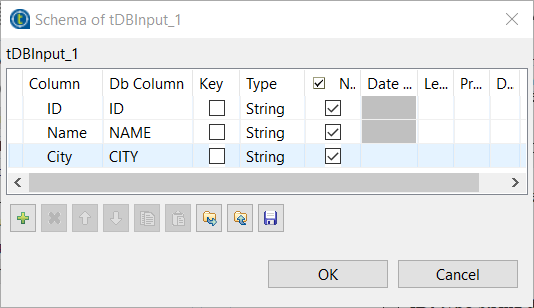
- ID, type String and Db
- Leave other options as they are.
-
Select Snowflake from the
-
Configure tLogRow_1 to specify the output layout. In the
Basic settings view of the component, select a
preferred mode for the output. -
Configure tDBClose_1
to close the connection to Snowflake. In the Basic
settings view of the component:-
Select Snowflake
from the Database list and click
Apply; - Select tDBConnection_1 from the Connection Component list;
-
Select Snowflake
- Press Ctrl + S to save the Job.
Executing the Snowflake external table Job and checking the result

Querying data in a cloud file through a Snowflake materialized view
This example describes how to query data from a
cloud file through a Snowflake materialized view. It is based on the Job described in
the previous example.
Updating the Job for querying data through a Snowflake materialized view
- In the Job described in the previous example, add a tDBRow component (default name: tDBRow_4) .
-
Remove the connection between tDBRow_3 and
tDBInput_1. -
Connect tDBRow_3 to
tDBRow_4 using a Trigger > On Subjob OK connection. -
Connect tDBRow_4 to
tDBInput_1 using a Trigger > On Subjob OK connection.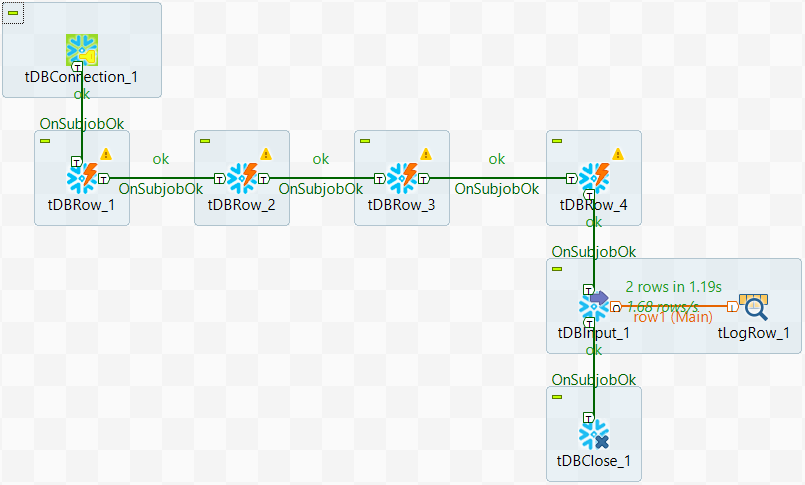
Configuring the Snowflake materialized view Job
-
Configure tDBRow_4 to
create a materialized view. In the Basic
settings view of the component:-
Select Snowflake from
the Database list and click
Apply. -
Enter the following code in double quotation marks in
the Query field.12CREATE OR REPLACE MATERIALIZED VIEW <kbd>mv1</kbd> ASSELECT Name, City FROM logs; - Leave other options as they are.
-
Select Snowflake from
-
Configure tDBInput_1 to query the external table through
the materialized view. In the Basic settings view of the
component:-
Select Snowflake from the
Database list and click
Apply; -
Select tDBConnection_1 from the Connection
Component list; -
Enter the following code in double quotation marks in the
Query field.1SELECT name,city FROM <kbd>mv1</kbd>; -
Click the three-dot button to the right of Edit schema. Add the following columns
and click OK to propagate the
schema.- Name,
type String and Db Column
NAME - City,
type String and Db Column
CITY
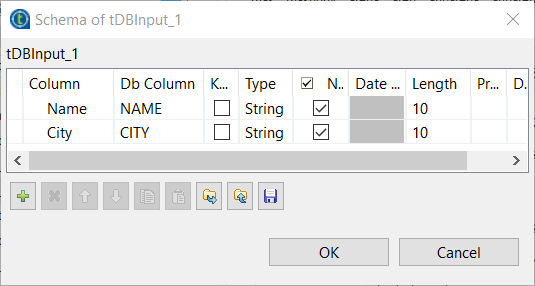
- Name,
- Leave other options as they are.
-
Select Snowflake from the
- Press Ctrl + S to save the Job.
Executing the Snowflake materialized view Job and checking the result

Related scenario
For a related scenario, see Writing data into and reading data from a Snowflake table.