tStandardizePhoneNumber
Standardizes phone numbers according to given formats.
tStandardizePhoneNumber receives phone
number data from its preceding component and formats and standardizes these numbers
using a built-in Google libphonumber library, org.talend.libraries.google.libphonumber.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tStandardizePhoneNumber Standard properties.
The component in this framework is available in Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform and in Talend Data Fabric.
-
Spark Batch: see tStandardizePhoneNumber properties for Apache Spark Batch.
The component in this framework is available in all Talend Platform products with Big Data and in Talend Data Fabric.
-
Spark Streaming: see tStandardizePhoneNumber properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tStandardizePhoneNumber Standard properties
These properties are used to configure tStandardizePhoneNumber running in the Standard Job framework.
The Standard
tStandardizePhoneNumber component belongs to the Data Quality family.
The component in this framework is available in Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform and in Talend Data Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields This component provides default columns. For further information, see |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Phone number |
Select the column holding the phone numbers of interest from the input data. |
|
Country code |
Select the column holding the country codes (ISO 2) from the input data. Note:
The input data processed by this component must be able to provide the two-letter ISO |
|
Customize |
Select this check box to set a custom country code (ISO 2). Once selected, it disables the For example, if the input data provides a set of phone numbers with a wrong country code |
|
Phone number format for output |
Select the format to be used to standardize the phone numbers of interest. The available – E164 – International – National |
Advanced settings
|
Avoid comparison |
Select this check box to deactivate the comparison performed between the input and the |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the Job level |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is usually used as an intermediate component, and it requires an |
Default columns
The following table presents details about the default columns provided by tStandardizePhoneNumber.
Tip: In addition to these default columns, you need to define more columns alongside in order for this component to receive the corresponding input data.
|
Columns |
Description |
|---|---|
|
StandardizedPhoneNumber |
This column presents the standardized phone numbers. |
|
IsValidPhoneNumber |
This column indicates whether a phone number processed is |
|
IsPossiblePhoneNumber |
This column indicates whether a phone number processed is |
|
IsAlreadyStandard |
This column indicates whether a phone number processed is |
|
PhoneNumberType |
This column indicates the type of a processed phone number, |
|
ErrorMessage |
This column presents the relative error message if a phone |
Standardizing French phone numbers
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
In this scenario, you use three components to standardize some French phone numbers
according to the French phone number format.

The components to be used are:
-
tFixedFlowInput: this component is used to
provide the input data composed of phone numbers to be processed and the French
country code (FR). -
tStandardizePhoneNumber: this component
standardizes the phone numbers of interest. -
tLogRow: this component displays the result
of this standardization.
To replicate this scenario, proceed as the following sections illustrate:
Dropping and linking the components
To do this, proceed as follows:
-
Drop tFixedFlowInput, tStandardizePhoneNumber and tLogRow from the Palette to
the Design workspace. -
Right-click the tFixedFlowInput component
to open the contextual menu and select Row >
Main. -
Do the same to connect tStandardizePhoneNumber to tLogRow using a Row >
Main link.
Then you can continue to configure these components.
Configuring the input data
To do this, proceed as follows:
-
Double click tFixedFlowInput to open its
Component view.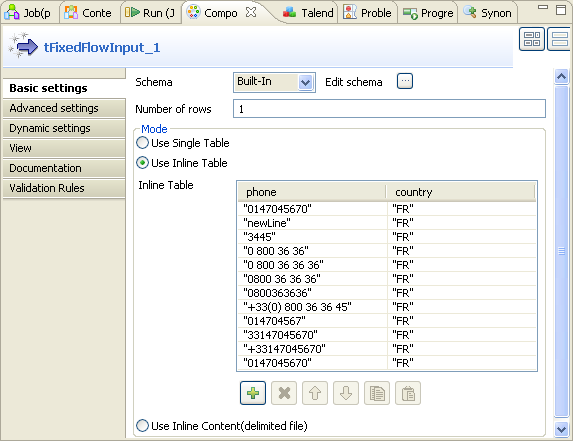
-
Next to Edit schema, click the three-dot
button to open the schema editor.
- Click the plus button to add two rows.
-
In the Column column, rename these two
newly added rows. In this scenario, name them phone and
country respectively. -
Click OK to validate these changes and
accept the propagation prompted by the dialog box that pops up. - In the Mode area, select the Use Inline Table option to display the Inline Table.
-
Under this table, click the plus button to add as much number of rows as
you need. In this scenario, add 12 rows. -
In this table, type in, between quotation marks, phone numbers of various
formats and the corresponding ISO 2-letter country code in the
phone and the country columns
respectively. In this scenario, they read as follows: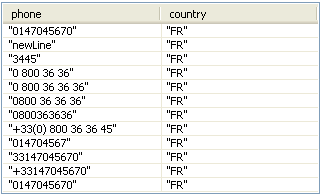
Configuring the standardization process
To do this, proceed as follows:
-
Double click tStandardizePhoneNumber to
open its Component view.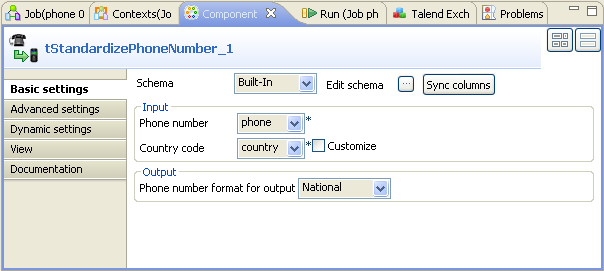
-
If required, click Sync columns to
retrieve the schema from the previous component. -
In the Phone number field, select
phone from the drop-down list as this column holds
the phone numbers to be processed. -
In the Country
code field, select
country from the drop-down list as this column provides the
country code to be used. In this scenario, this code is the French country
code FR. -
In the Phone number format for output
field, select National as you need to
standardize these phone numbers according to the national standard format of
France.
Executing the Job
Press F6 to run this Job.
You can read the execution result in the console of the Run view.

From this result table, you can find that the first input record
0147045670, for example, is standardized as 01 47
04 56 70 according to the French phone number format and this number
is of FIXED LINE.
tStandardizePhoneNumber properties for Apache Spark Batch
These properties are used to configure tStandardizePhoneNumber running in the Spark Batch Job framework.
The Spark Batch
tStandardizePhoneNumber component belongs to the Data Quality family.
The component in this framework is available in all Talend Platform products with Big Data and in Talend Data Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields This component provides default columns. For further information, see |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Phone number |
Select the column holding the phone numbers of interest from the input data. |
|
Country code |
Select the column holding the country codes (ISO 2) from the input data. Note:
The input data processed by this component must be able to provide the two-letter ISO |
|
Customize |
Select this check box to set a custom country code (ISO 2). Once selected, it disables the For example, if the input data provides a set of phone numbers with a wrong country code |
|
Phone number format for output |
Select the format to be used to standardize the phone numbers of interest. The available – E164 – International – National |
Advanced settings
|
Avoid comparison |
Select this check box to deactivate the comparison performed between the input and the |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is used as an intermediate step. This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tStandardizePhoneNumber properties for Apache Spark Streaming
These properties are used to configure tStandardizePhoneNumber running in the Spark Streaming Job framework.
The Spark Streaming
tStandardizePhoneNumber component belongs to the Data Quality family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields This component provides default columns. For further information, see |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Phone number |
Select the column holding the phone numbers of interest from the input data. |
|
Country code |
Select the column holding the country codes (ISO 2) from the input data. Note:
The input data processed by this component must be able to provide the two-letter ISO |
|
Customize |
Select this check box to set a custom country code (ISO 2). Once selected, it disables the For example, if the input data provides a set of phone numbers with a wrong country code |
|
Phone number format for output |
Select the format to be used to standardize the phone numbers of interest. The available – E164 – International – National |
Advanced settings
|
Avoid comparison |
Select this check box to deactivate the comparison performed between the input and the |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component, along with the Spark Streaming component Palette it belongs to, appears This component is used as an intermediate step. You need to use the Spark Configuration tab in the This connection is effective on a per-Job basis. For further information about a Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.