tSurviveFields
Centralizes data from various and heterogeneous sources to create a master copy of
data for MDM.
tSurviveFields receives a flow
and merges it based on one or more columns. The aggregation key and the relevant result
of operations (such as min, max, sum etc) are provided for each output line.
tSurviveFields Standard properties
These properties are used to configure tSurviveFields running in the Standard Job framework.
The Standard
tSurviveFields component belongs to the Data Quality, the Talend MDM and the Processing families.
This component is available in Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
Basic settings
|
Schema and Edit schema |
A schema is a row description, it defines the number of fields to be processed |
|
|
Built-in: The schema will be created and stored |
|
|
Repository: The schema already exists and is |
|
Key |
Define the merge sets, the values of which will be used for calculations.
Output column: Select the column name from the list
Input column: Match each input column name with Warning:
The columns in the Key table must NOT appear in the Operations table. If you |
|
Operations |
Output column: From the list, select the output
Function: Select the type of merge operation to be
Input column: From the list, select the input
Rank column: Only available with the best rank function. From the list, select the column you
Ignore null values: Select the check boxes which |
Advanced settings
|
Delimiter (only for list operation) |
Between double quotation marks, enter the delimiter you want to use for the list |
|
Use financial precision, this is the max precision for “sum” and “avg” |
This check box, which enables financial precision, is selected by default. Clear |
|
Check type overflow (slower) |
Checks the data type to ensure that the job does not crash. If you select this check box, the system will be slower. |
|
Check ULP (Unit in the Last Place), ensure that a value will be |
Select this check box to launch ULP verification. If you select this check box, the system will be slower. |
|
tStatCatcher Statistics |
Select this check box to collect log data at the Job and the component |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component requires an input component and an output component. |
Merging the content of several rows using different columns as rank
values
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
This scenario describes a three-component Job that uses the tSurviveFields component to merge, based on different rank values, the content
of data rows in different columns and then writes the result in an output file.
In this scenario, we have already stored the input schemas of the input file in the
Repository. For further information about storing schema metadata in the Repository, see
Talend Studio User
Guide.
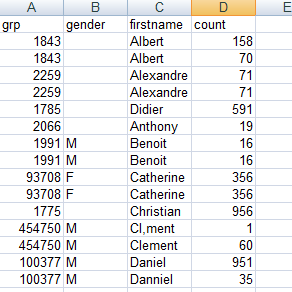
The input file contains four columns: grp,
gender, firstname and count.
The data in the input file has problems such as duplication, first names spelled differently
or wrongly and different information for the same customer.
Setting up the Job
-
In the Repository tree view, expand Metadata and the FileExcel
node where you have stored the input schemas and then drop it onto the design
workspace.The tFileInputExcel component which contains your
schema displays on the workspace. -
Drop a tSurviveFields and a tFileOutputExcel component from the Palette onto the design workspace.

- Link the components together using Row > Main connections.
Configuring the components
-
Double-click tFileInputExcel to display its
Basic settings view. All tFileInputExcel property fields are
All tFileInputExcel property fields are
automatically filled in. If you did not define your input schemas locally in the
Repository, fill in the details manually after selecting Built-in in the Schema and Property Type fields. -
Double-click tSurviveFields to display its
Basic settings view and define the component
properties.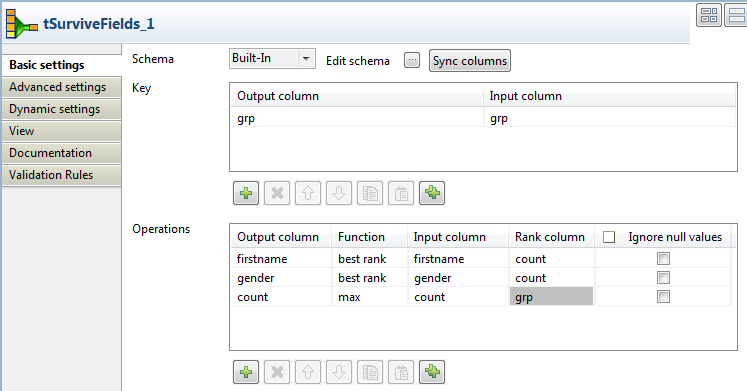
-
Click Sync columns to retrieve the schema from the
preceding component. You can click the […] next to
Edit schema to view the schema. -
In the Key area, click the [+] button to add a new line, and click the field and select the name of
the column you want to use to merge the data from the list.You can select multiple columns as an aggregation set if you want to merge data
based on multiple criteria. For this scenario, we want to use the
grp column to merge the data. -
In the Operations area, click the [+] button to add new rows. Here you can define the output
columns that will hold the results of the merge operation. In this scenario, we want to
merge the data in the firstname, gender and
count columns. -
Click in the first field of the Output column and
select the first output column that will hold the merge results.-
Click in the first field of the Function column
and select the merge operation you want to perform. -
Click in the first field of the Input Column
list and select the column from which the input values are to be taken. -
Click in the first field of the Rank column and
select the column that will be used as a basis for the merge operation. -
Repeat the same process to define the parameters for the merge operation for all
the columns you want to write in the output file.Here we want to read data from the firstname and
gender input columns and write only the values with the
maximum rank (row count) in firstname and
gender output columns. We also want to read data from the
count input column and write its maximum value in a
count output column.
-
-
Double-click the tFileOutputExcel component to open
its Basic settings view.
-
Specify the path to the target file, select the Include
header check box, and leave the other settings as they are.
Executing the Job
When the percentage progress bar reaches 100%, the specified data is regrouped and
written in the defined output columns.
operation.
