tTeradataTPTExec
Offers high performance in inserting data from an existing file to a table in a
Teradata database.
As the combination of tTeradataFastLoad, tTeradataMultiLoad, tTeradataTPump,
and tTeradataFastExport, tTeradataTPTExec loads the data from an existing file to a Teradata
database.
tTeradataTPTExec Standard properties
These properties are used to configure tTeradataTPTExec running
in the Standard Job framework.
The Standard
tTeradataTPTExec component belongs to the Databases family.
The component in this framework is available in all Talend
products.
Basic settings
|
Property Type |
Either Built-In or |
|
|
Built-In: No property data stored |
|
|
Repository: Select the repository file |
|
Execution platform |
Select the Operating System that will be used to run the Job, |
|
TDPID |
Specify the Teradata director program identifier. It can be |
|
Database name |
Specify the name of the Teradata database. |
|
Username and Password |
Specify the username and the password for the Teradata database To enter the password, click the […] button next to the |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields Note:
Avoid using a Teradata database keyword as a Db Column name in the schema. If you have to, |
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Click Edit
|
|
|
Consumer Operator |
Select a consumer operator from the drop-down list.
For more information about Teradata consumer operators, see |
|
Action On Data |
Select an action to be performed on the data from the drop-down
list.
Note:
You must specify at least one column as the primary key on This list field appears only when the Update or Stream operator is selected from the Consumer Operator drop-down list. |
|
Producer Operator |
Select a producer operator from the drop-down list. Currently,
DataConnector: accesses files either For more information about Teradata producer operators, see |
|
Table |
Specify the name of the table to be written into the Teradata |
|
Script generated folder |
Specify the directory under which the Teradata Parallel |
|
Load file |
Specify the file holding the data to be loaded into the |
|
Error file |
Specify the file in which log messages will be recorded. Make sure that the path to the file exists and is accessible to TPT tools. |
Advanced settings
|
Custom script |
Select this check box to use the customized Teradata TPT script in the directory specified in Path to custom script.
|
|
Field separator |
Character, string or regular expression to separate fields. |
|
Define Log table |
Select this check box to specify a log table so that log |
|
Set Script Parameters |
Select this check box to define script parameters, which will This field is not available when Custom script is |
|
Load Operator |
Specify the load operator. This field appears only when the Set |
|
Data Connector |
Specify the data connector. This field appears only when the Set |
|
Job Name |
Specify the name of a Teradata Parallel Transporter Job which For further information about the tbuild This field appears only when the Set |
|
Layout Name (schema) |
Specify a schema for the data to be loaded. This field appears only when the Set |
|
Return mload error |
Select this check box to specify the exit code number to |
|
Character set encoding of the script |
This check box is selected by default, allowing you to specify |
|
Character set encoding of the data |
Select this check box to specify the encoding to be used for the Teradata TPT data. This field is not available when Custom script |
|
Apply TPT consumer operator optional |
Select this check box to define optional attribute(s) for the For more information about optional attributes of each consumer |
|
Optional attributes |
Click the [+] button
For more information about the attribute value definition, see This table appears only when the Apply TPT consumer operator optional attributes check box is |
|
tStatCatcher Statistics |
Select this check box to collect the log data at the component |
Global Variables
|
Global Variables |
EXIT_VALUE: the process exit code. This is an After
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Used as a single-component Job or subJob, this component |
|
Limitation |
The Teradata client tool with the Teradata Parallel |
Supported optional attributes for each consumer operator
operator.
The Load operator
BufferSize, ErrorLimit, MaxSessions, MinSessions, TenacityHours, TenacitySleep,
AccountId, DataEncryption, DateForm, ErrorTable1, ErrorTable2, LogonMech,
LogonMechData, NotifyExit, NotifyExitlsDLL, NotifyLevel, NotifyMethod,
LogSQL, NotifyString, PauseAcq, PrivateLogName, QueryBandSessInfo,
WildcardInsert, WorkingDatabase, TraceLevel.
The Inserter operator
AccountId, DataEncryption, DateForm, LogonMech, LogonMechData, LogSQL, PrivateLogName,
QueryBandSessInfo, ReplicationOverride, TraceLevel, WorkingDatabase.
The Update operator
PrivateLogName, BufferSize, ErrorLimit, MaxSessions, MinSessions, TenacityHours,
TenacitySleep, AccountId, AmpCheck, DataEncryption, DateForm, DeleteTask,
DropErrorTable, DropLogTable, DropWorkTable, ErrorTable1, ErrorTable2,
LogonMech, LogonMechData, LogSQL, NotifyExit, NotifyExitIsDLL, NotifyLevel,
NotifyMethod, NotifyString, PauseAcq, QueryBandSessInfo, QueueErrorTable,
WorkingDatabase, WorkTable, TraceLevel.
The Stream operator
Buffers, ErrorLimit, MaxSessions, MinSessions, Pack, Rate, Periodicity, TenacityHours,
TenacitySleep, AccountId, AppendErrorTable, ArraySupport, DataEncryption,
DateForm, DropErrorTable, DropMacro, ErrorTable, LogonMech, LogonMechData,
MacroDatabase, OperatorCommandID, NotifyExit, NotifyExitlsDLL, NotifyLevel,
NotifyMethod, LogSQL, NotifyString, PackMaximum, PrivateLogName,
QueryBandSessInfo, QueueErrorTable, ReplicationOverrride, Robust,
WorkingDatabase, TraceLevel.
Loading data into a Teradata database
This scenario describes a Job that creates a new Teradata database table, writes data
into a delimited file, then loads the data from the file into this table, and finally
retrieves the data from the table and displays it on the console.

Dropping and linking the components
-
Create a new Job and add the following components by typing their names in the design
workspace or dropping them from the Palette: a
tTeradataRow component, a tFixedFlowInput component, a tFileOutputDelimited component, a tTeradataTPTExec component, a tTeradataInput component, and a tLogRow component. -
Connect tFixedFlowInput to tFileOutputDelimited using a Row > Main
connection. -
Do the same to connect tTeradataInput to
tLogRow. -
Connect tTeradataRow to tFixedFlowInput using a Trigger > On Subjob Ok
connection. - Do the same to connect tFixedFlowInput to tTeradataTPTExec and tTeradataTPTExec to tTeradataInput.
Configuring the components
Creating a new Teradata database table
-
Double-click tTeradataRow to open its
Basic settings view.
-
Fill in the Host, Database, Username, and
Password fields with your Teradata
database connection details. -
In the Query field, enter the following
SQL statement to create a new table named person with three columns id, name, sex.12345678910CREATE SET TABLE samples.person,FALLBACK,NO BEFORE JOURNAL,NO AFTER JOURNAL(id INTEGER NOT NULL,name VARCHAR(50),sex VARCHAR(20))UNIQUE PRIMARY INDEX (id)
Preparing the source data
-
Double-click tFixedFlowInput to open its
Basic settings view.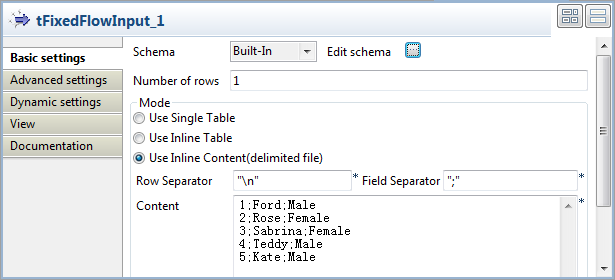
-
Click the […] button next to Edit schema to open the schema editor.

-
Click the [+] button to add three
columns: id of the integer type,
name and sex of the string type. -
Click OK to close the schema editor and
accept the propagation prompted by the pop-up dialog box. -
In the Mode area, select Use Inline Content (delimited file) and enter the
input data in the Content field.123451;Ford;Male2;Rose;Female3;Sabrina;Female4;Teddy;Male5;Kate;Male -
Double-click tFileOutputDelimited to open
its Basic settings view.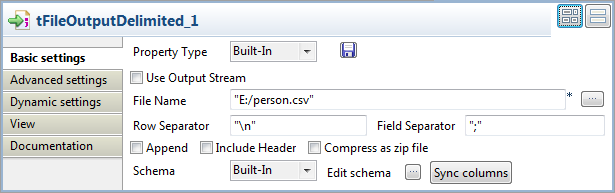
-
In the File Name field, specify the file
into which the input data will be written. In this example, it is E:/person.csv.
Loading the source data into an empty table
-
Double-click tTeradataTPTExec to open its Basic settings view.

-
Fill in the TDPID, Database name, Username,
and Password fields with your Teradata
database connection details. -
In the Table field, enter the name of the
table into which the source data will be loaded. In this example, it is
person. -
In the Script generated folder field,
browse to the directory under which the Teradata Parallel Transporter script
file will be created during the Job execution. In this example, it is
E:/. -
In the Load file field, browse to the
file that contains the source data. In this example, it is E:/person.csv. -
In the Error file field, specify the file
in which log messages will be recorded. In this example, it is E:/error.log. -
Click the […] button next to Edit schema to open the schema editor.
 Click the [+] button to add three
Click the [+] button to add three
columns: id of the integer type,
name and sex of the string type. Note that id and name in Db Column are enclosed in a pair of “ since they are Teradata database
keywords.Click OK to validate these changes and
close the schema editor. -
Click Advanced settings to open its view,
and then select the Apply TPT consumer operator
optional attributes check box and click the [+] button below the Optional attributes table to add the following attributes
needed: ErrorLimit, ErrorTable1, QueryBandSessInfo, and TraceLevel.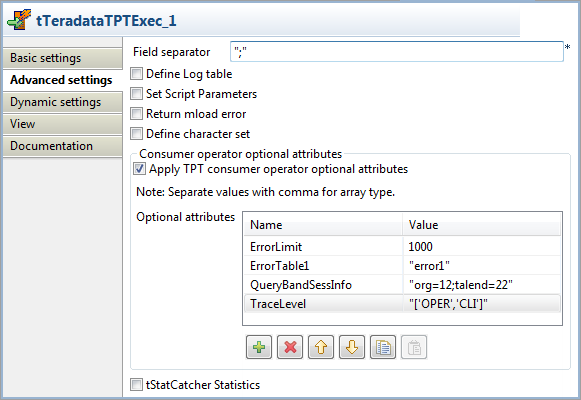 Note:
Note:For VARCHAR attributes, enter their values between double quotation
marks.
Retrieving data from the Teradata database table
-
Double-click tTeradataInput to open its
Basic settings view.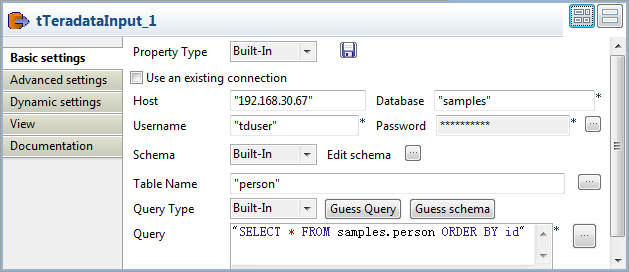
-
In the Table Name field, enter the name
of the table to read data from. In this example, it is person. -
In the Query field, enter the following
SQL statement to retrieve data from the table person.1SELECT * FROM samples.person ORDER BY id -
Click the […] button next to Edit schema to open the schema editor.

-
Click the [+] button to add three
columns: id of the integer type,
name and sex of the string type. Note that id and name in Db Column are enclosed in a pair of “ since they are Teradata database
keywords. -
Click OK to close the schema editor and
accept the propagation prompted by the pop-up dialog box. -
Double-click tLogRow to open its
Basic settings view.
-
In the Mode area, select the Table (print values in cells of a table) option
for a better display of the result.
Saving and executing the Job
- Press Ctrl + S to save the Job.
-
Press F6 to execute the Job.
 The data written into the specified Teradata database table is displayed
The data written into the specified Teradata database table is displayed
on the console.