tPigLoad
Loads original input data to an output stream in just one single transaction, once
the data has been validated.
The tPigLoad
sets up a connection to the data source for a current transaction.
tPigLoad Standard properties
These properties are used to configure tPigLoad running in the Standard Job framework.
The Standard
tPigLoad component belongs to the Big Data and the Processing families.
The component in this framework is available when you are using one of the Talend solutions with Big Data.
Basic settings
|
Property type |
Either Built-In or Repository. |
||
|
|
Built-In: No property data stored centrally. |
||
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
||
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
||
|
|
Built-In: You create and store the |
||
|
|
Repository: You have already created |
||
|
Local |
Click this radio button to run Pig scripts in Local mode. In this mode, all files are |
||
|
Tez |
Click this radio button to run the Pig Job on the Tez framework. This Tez mode is available only when you are using one of the following distributions:
Before using Tez, ensure that the Hadoop cluster you are using supports Tez. You will need to configure the access to the relevant Tez libraries via the Advanced settings view of this component. For further information about Pig on Tez, see Apache’s related documentation in https://cwiki.apache.org/confluence/display/PIG/Pig+on+Tez. |
||
|
Map/Reduce |
Click this radio button to run Pig scripts in Map/Reduce mode. Once selecting this mode, you need to complete the fields in the
Configuration area that appears:
|
||
|
WebHCat configuration |
Enter the address and the authentication information of the WebHCat service In the Job result folder field, enter |
||
|
HDInsight configuration |
Enter the authentication information of the HD Insight cluster to be |
||
|
Windows Azure Storage |
Enter the address and the authentication information of the Azure Storage In the Container field, enter the name In the Deployment Blob field, enter the |
||
|
Inspect the classpath for |
Select this check box to allow the component to check the configuration In this situation, the fields or options used to configure Hadoop If you want to use certain parameters such as the Kerberos parameters but
these parameters are not included in these Hadoop configuration files, you need to create a file called talend-site.xml and put this file into the same directory defined with $HADOOP_CONF_DIR. This talend-site.xml file should read as follows:
The parameters read from these configuration files override the default |
||
|
Load function |
Select a load function for data to be loaded:
Note that when the file format to be used is PARQUET, you
might be prompted to find the specific Parquet jar file and install it into the Studio.
This jar file can be downloaded from Apache’s site. You can find more details about how to install external modules in Talend Help Center (https://help.talend.com). |
||
|
Input file URI |
Fill in this field with the full local path to the input file.
Note:
This field is not available when you select HCatLoader from the Load function list or when you |
||
|
Use S3 endpoint |
Select this check box to read data from a given Amazon S3 bucket Once this Use S3 endpoint check box is
selected, you need to enter the following parameters in the fields that appear:
Note that the format of the S3 file is S3N (S3 Native Filesystem). |
||
|
HCataLog Configuration |
Fill the following fields to configure HCataLog managed tables on Distribution and Version: Select the cluster you are using from the drop-down list. The options in the
list vary depending on the component you are using. Among these options, the following ones requires specific configuration:
Along with the evolution of Hadoop, please note the following changes:
HCat metastore: Enter the
Database: The database in which
Table: The table in which data is
Partition filter: Fill this field Note:
HCataLog Configuration area |
||
| Field separator |
Enter character, string or regular expression to separate fields for the transferred Note:
This field is enabled only when you select PigStorage from the Load function list. |
||
|
Compression |
Select the Force to compress the output data check box to Hadoop provides different compression formats that help reduce the space needed for storing Note:
The output path is set in the Basic settings view of |
||
| HBase configuration |
This area is available to the HBaseStorage function. The Zookeeper quorum: Type in the name or the URL of the Zookeeper service you use to coordinate the transaction Zookeeper client port: Type in the number of the client listening port of the Zookeeper service you are Table name: Enter the name of the HBase table you need to load data Load key: Select this check box to load the row key as the first column of Mapping: Complete this table to map the columns of the table to be used with the schema columns you |
||
|
Sequence Loader configuration |
This area is available only to the SequenceFileLoader function. Since a SequenceFile Key column: Select the Key column of a key/value record. Value column Select the Value column of a key/value record. |
||
|
Die on subjob error |
This check box is cleared by default, meaning to skip the row on |
Advanced settings
|
Tez lib |
Select how the Tez libraries are accessed:
|
| Hadoop Properties |
Talend Studio uses a default configuration for its engine to perform operations in a Hadoop distribution. If you need to use a custom configuration in a specific situation, complete this table with the property or properties to be customized. Then at runtime, the customized property or properties will override those default ones.
For further information about the properties required by Hadoop and its related systems such
as HDFS and Hive, see the documentation of the Hadoop distribution you are using or see Apache’s Hadoop documentation on http://hadoop.apache.org/docs and then select the version of the documentation you want. For demonstration purposes, the links to some properties are listed below:
|
|
Register jar |
Click the [+] button to add rows to the table and from these rows, browse to the jar |
| Define functions |
Use this table to define UDFs (User-Defined Functions), especially Click the button to add as many rows as you need and If your Job includes a tPigMap For information on how to define UDFs when mapping Pig flows, see For more information on Apache DataFu Pig, see http://datafu.incubator.apache.org/. |
|
Pig properties |
For example, the default_parallel key used in Pig could |
| HBaseStorage configuration |
Add and set more HBaseStorage loader options in this table. The gt: the minimum key value; lt: the maximum key value;
gte: the minimum key value
lte: the maximum key value
limit: maximum number of rows to
caching: number of rows to
caster: the converter to use for |
|
Define the jars to register for |
This check box appears when you are using tHCatLoader, while you can leave it clear as the |
|
Path separator in server |
Leave the default value of the Path separator in |
|
Mapred job map memory mb and |
If the Hadoop distribution to be used is Hortonworks Data Platform V1.2 or Hortonworks In that situation, you need to enter the values you need in the Mapred If the distribution is YARN, then the memory parameters to be set become Map (in Mb), Reduce (in Mb) and |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is always used to start a Pig process and needs In the Map/Reduce mode, you need |
|
Prerequisites |
The Hadoop distribution must be properly installed, so as to guarantee the interaction
For further information about how to install a Hadoop distribution, see the manuals |
|
Limitation |
Knowledge of Pig scripts is required. If you select HCatLoader as |
Scenario: Loading an HBase table
This scenario applies only to a Talend solution with Big Data.
This scenario uses tPigLoad and tPigStoreResult to read data from HBase and to write them to
HDFS.

The HBase table to be used has three columns: id,
name and age,
among which id and age belong to the column family, family1 and name to the column
family, family2.
The data stored in that HBase table are as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
1;Albert;23 2;Alexandre;24 3;Alfred-Hubert;22 4;Andre;40 5;Didier;28 6;Anthony;35 7;Artus;32 8;Catherine;34 9;Charles;21 10;Christophe;36 11;Christian;67 12;Danniel;54 13;Elisabeth;58 14;Emile;32 15;Gregory;30 |
To replicate this scenario, perform the following operations:
Linking the components
-
In the
Integration
perspective
of
Talend Studio
,
create an empty Job, named hbase_storage
for example, from the Job Designs node in
the Repository tree view.For further information about how to create a Job, see the
Talend Studio
User
Guide. - Drop tPigLoad and tPigStoreResult onto the workspace.
-
Connect them using the Row > Pig
combine link.
Configuring tPigLoad
-
Double-click tPigLoad to open its
Component view.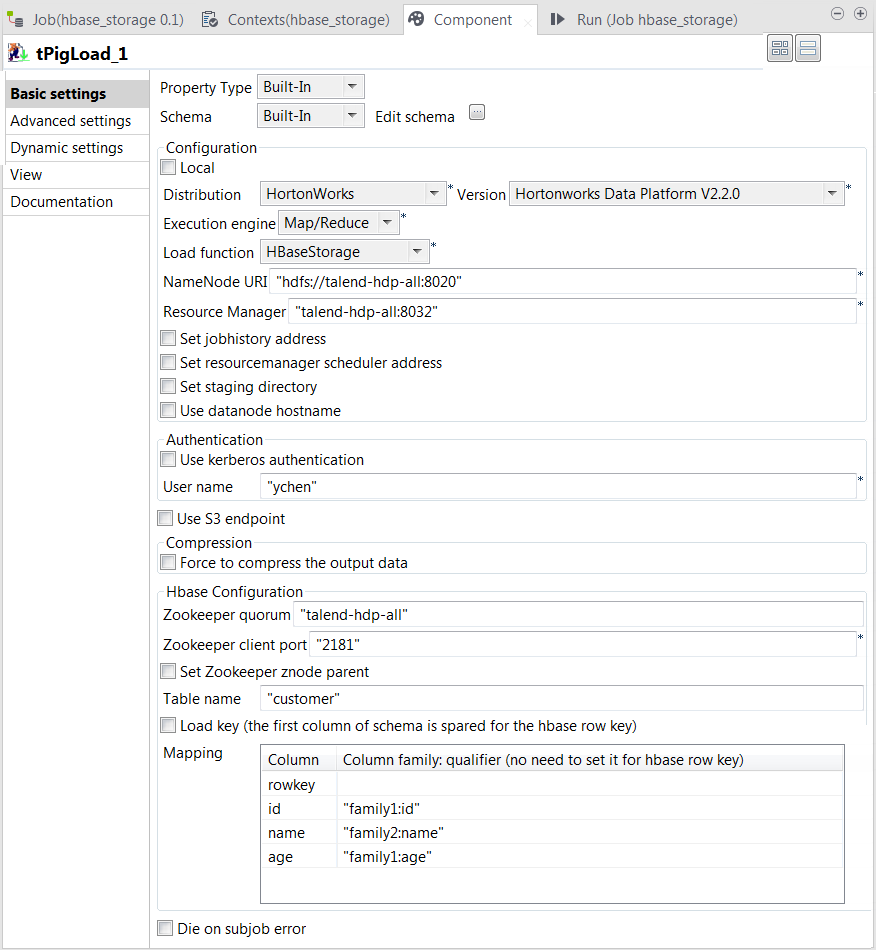
-
Click the

button next to Edit
schema to open the schema editor. -
Click the

button four times to add four rows and rename them:
rowkey, id, name and age. The rowkey column put at the top of the schema to store the
HBase row key column, but in practice, if you do not need to load the row
key column, you can create only the other three columns in your
schema.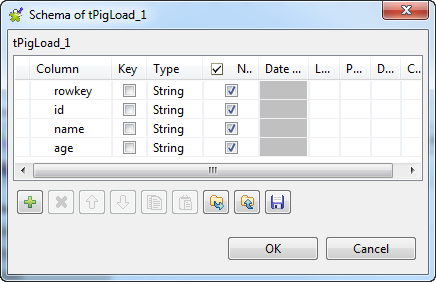
-
Click OK to validate these changes and
accept the propagation prompted by the pop-up dialog box. -
In the Mode area, select Map/Reduce, as we are using a remote Hadoop
distribution. -
In the Distribution and the Version fields, select the Hadoop distribution
you are using. In this example, we are using HortonWorks Data Platform V1. -
In the Load function field, select
HBaseStorage. Then, the corresponding
parameters to set appear. -
In the NameNode URI and
the Resource Manager fields, enter the
locations of those services, respectively. If you are using WebHDFS, the location should be
webhdfs://masternode:portnumber; if this WebHDFS is secured
with SSL, the scheme should be swebhdfs and you need to use
a tLibraryLoad in the Job to load the library required by
the secured WebHDFS. -
In the Zookeeper quorum and the Zookeeper client port fields, enter the location
information of the Zookeeper service to be used. -
If the Zookeeper znode parent location has been defined in the Hadoop
cluster you are connecting to, you need to select the Set zookeeper znode parent check box and enter the value of
this property in the field that is displayed. -
In the Table name field, enter the name
of the table from which tPigLoad reads the
data. -
Select the Load key check box if you need
to load the HBase row key column. In this example, we select it. -
In the Mapping table, four rows have been
added automatically. In the Column
family:qualifier column, enter the HBase columns you need to
map with the schema columns you defined. In this scenario, we put family1:id for the id column, family2:name
for the name column and family1:age for the age column.
Configuring tPigStoreResult
-
Double-click tPigStoreResult to open its
Component view.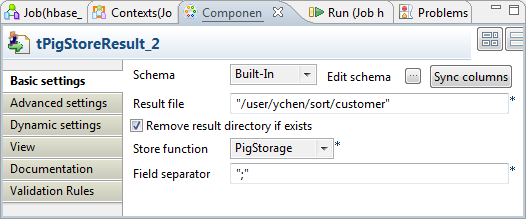
-
In the Result file field, enter the
directory where you need to store the result. As tPigStoreResult reuses automatically the connection created
by tPigLoad, the path in this scenario is
the directory in the machine hosting the Hadoop distribution to be
used. -
Select Remove result directory if
exists. -
In the Store function field, select
PigStorage to store the result in the
UTF-8 format.
Executing the Job
Then you can press F6 run this Job.
Once done, you can verify the result in the HDFS system used.
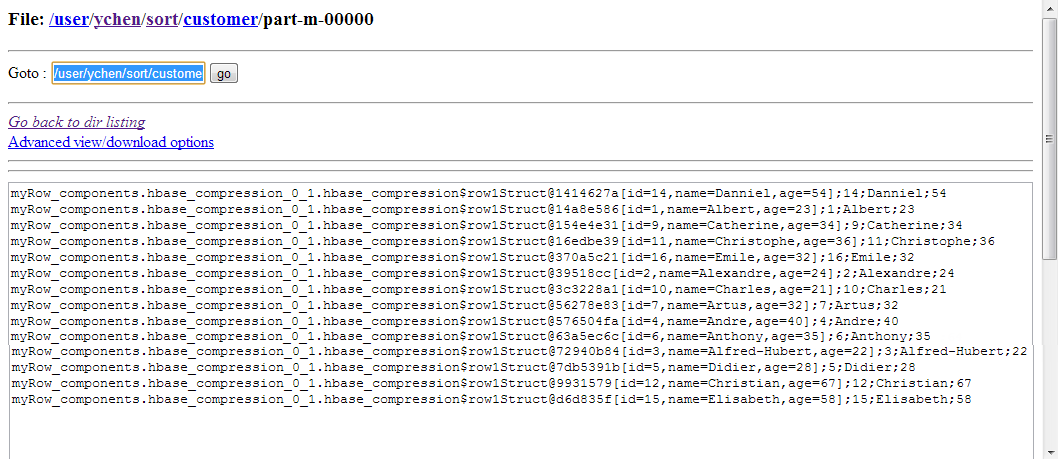
If you need to obtain more details about the Job, it is recommended to use the web
console of the Jobtracker provided by the Hadoop distribution you are using.
In JobHistory, you can easily find the execution status of your Pig Job because the name of
the Job is automatically created by concatenating the name of the project that contains the
Job, the name and version of the Job itself and the label of the first tPigLoad component used in it. The naming convention of a Pig Job in JobHistory
is ProjectName_JobNameVersion_FirstComponentName.