
|
Component family |
Databases/Amazon Redshift |
|
|
Function |
tRedshiftInput executes a DB |
|
|
Purpose |
tRedshiftInput reads data from a |
|
|
Basic settings |
Property type |
Either Built-in or Since version 5.6, both the Built-In mode and the Repository mode are |
|
|
|
Built-in: No property data stored |
|
|
|
Repository: Select the repository |
|
|
|
Click this icon to open a database connection wizard and store the For more information about setting up and storing database |
|
|
Use an existing connection |
Select this check box and in the Component List click the NoteWhen a Job contains the parent Job and the child Job, if you need to share an existing
For an example about how to share a database connection across Job levels, see |
|
|
Host |
Hostname or IP address of the database server. |
|
|
Port |
Listening port number of the database server. |
|
|
Database |
Name of the database. |
|
|
Schema |
Exact name of the schema. |
|
|
Username and |
Database user authentication data. To enter the password, click the […] button next to the |
|
|
Schema and Edit |
A schema is a row description. It defines the number of fields to be processed and passed on Since version 5.6, both the Built-In mode and the Repository mode are |
|
|
|
Built-In: You create and store the schema locally for this |
|
|
|
Repository: You have already created the schema and |
|
Click Edit schema to make changes to the schema. If the
|
||
|
|
Table name |
Name of the table from which the data will be read. |
|
|
Query type and |
Enter your database query paying particularly attention to Warning
If using the dynamic schema feature, |
|
|
Guess Query |
Click the Guess Query button to |
|
|
Guess schema |
Click the Guess schema button to |
|
Advanced settings |
Use cursor |
Select this check box to help to decide the row set to work with |
|
|
Trim all the String/Char columns |
Select this check box to remove leading and trailing whitespace |
|
|
Trim column |
Remove leading and trailing whitespace from defined |
|
|
tStat |
Select this check box to collect log data at the component |
|
Dynamic settings |
Click the [+] button to add a row in the table and fill The Dynamic settings table is available only when the For more information on Dynamic settings and context |
|
|
Global Variables |
NB_LINE: the number of rows processed. This is an After
QUERY: the SQL query statement being processed. This is a ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see Talend Studio |
|
|
Usage |
This component covers all possible SQL queries for Amazon Redshift |
|
|
Log4j |
The activity of this component can be logged using the log4j feature. For more information on this feature, see Talend Studio User For more information on the log4j logging levels, see the Apache documentation at http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html. |
|
|
Limitation |
Due to license incompatibility, one or more JARs required to use this component are not |
|
This scenario describes a Job that writes the personal information into Redshift, then
retrieves the information in Redshift and displays it on the console.
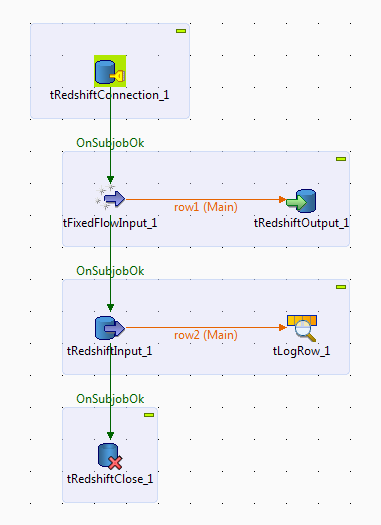
The scenario requires the following six components:
-
tRedshiftConnection: opens a connection to
Redshift. -
tFixedFlowInput: defines the personal
information data structure, and sends the data to the next component. -
tRedshiftOutput: writes the data it receives
from the preceding component into Redshift. -
tRedshiftInput: reads the data from
Redshift. -
tLogRow: displays the data it receives from
the preceding component on the console. -
tRedshiftClose: closes the connection to
Redshift.
-
Drop the six components listed previously from the Palette onto the design workspace.
-
Connect tFixedFlowInput to tRedshiftOutput using a Row > Main
connection. -
Connect tRedshiftInput to tLogRow also using a Row > Main
connection. -
Connect tRedshiftConnection to tFixedFlowInput using a Trigger > OnSubjobOk
connection. -
Connect tFixedFlowInput to tRedshiftInput and tRedshiftInput to tRedshiftClose also using a Trigger > OnSubjobOk
connection.
Opening a connection to Redshift
-
Double-click tRedshiftConnection to open
its Basic settings view.
-
Select Built-In from the Property Type drop-down list.
In the Host, Port, Database, Schema, Username, and Password fields,
enter the information required for the connection to Redshift. -
In Advanced settings view, select
Auto Commit check box to commit any
changes to Redshift upon each transaction.
Defining the input data
-
Double-click tFixedFlowInput to open its
Basic settings view.
-
Click the […] button next to Edit schema to open the schema editor.

-
In the schema editor, click the [+]
button to add three columns: id of the
interger type, name of the string type,
and age of the integer type. -
Click OK to validate the changes and
accept the propagation prompted by the pop-up [Propagate] dialog box. -
In the Mode area, select Use Inline Content (delimited file) and enter the
following personal information in the Content field.1231;Arthur;162;Ford;183;Jackson;17
Writing the data into Redshift
-
Double-click tRedshiftOutput to open its
Basic settings view.
-
Select the Use an existing connection
check box, and then select the connection you have already configured for
tRedshiftConnection from the Component List drop-down list. -
In the Table field, enter or browse to
the table into which you want to write the data, redshiftexample in this scenario. -
Select Drop table if exists and create
from the Action on table drop-down list,
and select Insert from the Action on data drop-down list. -
Click Sync columns to retrieve the schema
from the preceding component tFixedFlowInput.
Retrieving the data from Redshift
-
Double-click tRedshiftInput to open its
Basic settings view.
-
Select the Use an existing connection
check box, and then select the connection you have already configured for
tRedshiftConnection from the Component List drop-down list. -
Click the […] button next to Edit schema to open the schema editor.
-
In the schema editor, click the [+]
button to add three columns: id of the
interger type, name of the string type,
and age of the integer type. The data
structure is same as the structure you have defined for tFixedFlowInput. -
Click OK to validate the changes and
accept the propagation prompted by the pop-up [Propagate] dialog box. -
In the Table Name field, enter or browse
to the table into which you write the data, redshiftexample in this scenario. -
Click the Guess Query button to generate
the query. The Query field will be filled
with the automatically generated query.


