Scenario 1: Normalizing data using rules of basic types
This scenario applies only to a subscription-based Talend Platform solution or Talend Data Fabric.
In this scenario, two steps are performed to:
-
normalize the incoming data (separate the compliant data from the
non-compliant data) and, -
extract the data of interests and display it.
Before replicating these two steps, we need to analyze the source data in order to
figure out what rules need to be composed. For this scenario, the source data is stored
in a .csv file called partsmaster.
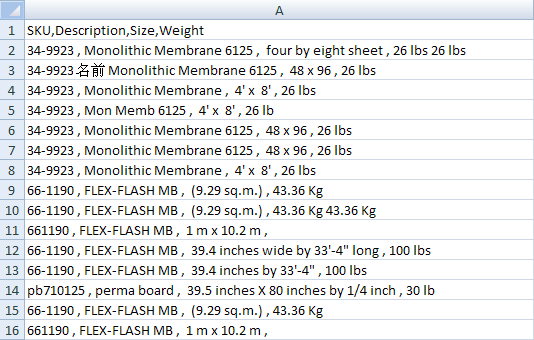
There are totally 59 rows of raw data, but some of them are not shown in our
capture.
Through observation, you can expect that the third row will not be recognized as it
contains Oriental characters. Furthermore, you can figure out that:
-
the SKU data contains 34-9923, XC-3211 and pb710125 and
so on. So the rule used to parse the SKU data could
be:Name
Type
Value
"SKU""Format""(DIGIT DIGIT|LETTER LETTER) '-'? DIGIT DIGIT DIGIT
DIGIT (DIGIT DIGIT?)? "
-
for the Size data, the correct format is the
multiplication of two or three lengths plus the length units. Therefore, the
rules used to parse the Size data could be:Name
Type
Value
"LengthUnit""Enumeration"" 'm' | '''' | 'inch' | 'inches' | '"'""BY""Enumeration""'X' | 'x' | 'by' ""Length""Format""(INT | FRACTION | DECIMAL) WHITESPACE* LengthUnit
""Size""Combination""Length BY Length BY Length""Size""Combination""Length BY Length"
Two Combination rules use the same name, in which
case, they will be executed in top-down order as is presented in this table.
-
for the Weight data, the correct format is the weight
plus the weight unit. Therefore, the rules used to parse the
Weight data are:Name
Type
Value
"WeightUnit""Enumeration"" 'lb' | 'lbs' | 'pounds' | 'Kg' | 'pinds'""Weight""Format""(INT | FRACTION | DECIMAL) WHITESPACE* WeightUnit
"
Now, you can begin to replicate the two steps of this scenario.