tFileOutputDelimited
schema.
Depending on the Talend solution you
are using, this component can be used in one, some or all of the following Job
frameworks:
-
Standard: see tFileOutputDelimited Standard properties.
The component in this framework is generally available.
-
MapReduce: see tFileOutputDelimited MapReduce properties.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data. -
Spark Batch: see tFileOutputDelimited properties for Apache Spark Batch.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data. -
Spark Stream: see tFileOutputDelimited properties for Apache Spark Streaming.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
tFileOutputDelimited Standard properties
These properties are used to configure tFileOutputDelimited running in the Standard Job framework.
The Standard
tFileOutputDelimited component belongs to the File family.
The component in this framework is generally available.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Use Output Stream |
Select this check box process the data flow of The data flow to be processed must be added to the flow in order for this component to fetch This variable could be already In order to avoid the inconvenience of For further information about how to use a stream, |
|
File name |
Name or path to the output file and/or the variable This field becomes unavailable once you have For further information about how to define and use a |
|
Row Separator |
The separator used to identify the end of a row. |
|
Field Separator |
Enter character, string or regular expression to separate fields for the transferred |
|
Append |
Select this check box to add the new rows at the end |
|
Include Header |
Select this check box to include the column header to |
|
Compress as zip file |
Select this check box to compress the output file in |
|
Schema and Edit schema |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
This component offers the This dynamic schema |
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Sync columns |
Click to synchronize the output file schema with the |
Advanced settings
|
Advanced separator (for numbers) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.).
Thousands separator: define separators
Decimal separator: define separators for |
|
CSV options |
Select this check box to specify the following CSV parameters:
|
|
Create directory if not exists |
This check box is selected by default. It creates the directory |
|
Split output in several files |
In case of very big output files, select this check box to
Rows in each output file: set the number |
|
Custom the flush buffer size |
Select this check box to define the number of lines to write
Row Number: set the number of lines to |
|
Output in row mode |
Select this check box to ensure atomicity of the flush so that This check box is mostly useful when using this component in |
|
Encoding |
Select the encoding from the list or select Custom and define it manually. This field is compulsory for database |
|
Don’t generate empty file |
Select this check box if you do not want to generate empty |
| Throw an error if the file already exist |
Select this check box to throw an exception if the output file specified in the Clear this check box to overwrite the existing file. |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
FILE_NAME: the name of the file being processed. This is
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to write |
|
Limitation |
Due to license incompatibility, one or more JARs required to use this component are not |
Scenario 1: Writing data in a delimited file
This scenario describes a three-component Job that extracts certain data from a file
holding information about clients, customers, and then writes the
extracted data in a delimited file.
In the following example, we have already stored the input schema under the Metadata node in the Repository tree view. For more information about storing schema metadata
in the Repository, see
Talend Studio User Guide.
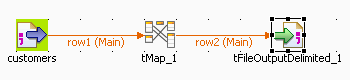
Dropping and linking components
-
In the Repository tree view, expand
Metadata and File
delimited in succession and then browse to your input schema,
customers, and drop it on the design workspace. A
dialog box displays where you can select the component type you want to
use.
-
Click tFileInputDelimited and then
OK to close the dialog box. A tFileInputDelimited component holding the name of
your input schema appears on the design workspace. - Drop a tMap component and a tFileOutputDelimited component from the Palette to the design workspace.
-
Link the components together using Row >
Main connections.
Configuring the components
Configuring the input component
-
Double-click tFileInputDelimited to open
its Basic settings view. All its property
fields are automatically filled in because you defined your input file
locally.
-
If you do not define your input file locally in the Repository tree view, fill in the details manually after
selecting Built-in in the Property type list. -
Click the […] button next to the
File Name field and browse to the input
file, customer.csv in this example.Warning:If the path of the file contains some accented characters, you
will get an error message when executing your Job. -
In the Row Separators and Field Separators fields, enter respectively
“
” and “;” as line and field
separators. -
If needed, set the number of lines used as header and the number of lines
used as footer in the corresponding fields and then set a limit for the
number of processed rows.In this example, Header is set to 6 while
Footer and Limit are not set. -
In the Schema field,
schema is automatically set to Repository
and your schema is already defined since you have stored your input file locally
for this example. Otherwise, select Built-in and click the […] button next to Edit
Schema to open the [Schema]
dialog box where you can define the input schema, and then click OK to close the dialog box.
Configuring the mapping component
-
In the design workspace, double-click tMap to open its editor.

-
In the tMap editor, click

on top of the panel to the right to open the [Add a new output table] dialog box.

-
Enter a name for the table you want to create, row2
in this example. -
Click OK to validate your changes and
close the dialog box. -
In the table to the left, row1, select the first
three lines (Id, CustomerName and
CustomerAddress) and drop them to the table to the
right -
In the Schema editor view situated in the
lower left corner of the tMap editor,
change the type of RegisterTime to String in the table to the right.
-
Click OK to save your changes and close
the editor.
Configuring the output component
-
In the design workspace, double-click tFileOutputDelimited to open its Basic
settings view and define the component properties.
-
In the Property Type field, set the type
to Built-in and fill in the fields that
follow manually. -
Click the […] button next to the
File Name field and browse to the
output file you want to write data in,
customerselection.txt in this example. -
In the Row Separator and Field Separator fields, set
“
” and “;” respectively as
row and field separators. -
Select the Include Header check box if
you want to output columns headers as well. -
Click Edit schema to open the schema
dialog box and verify if the recuperated schema corresponds to the input
schema. If not, click Sync Columns to
recuperate the schema from the preceding component.
Saving and executing the Job
- Press Ctrl+S to save your Job.
-
Press F6 or click Run on the Run tab to
execute the Job. The three specified columns Id,
The three specified columns Id,
CustomerName and
CustomerAddress are output in the defined output
file.For an example of how to use dynamic schemas with tFileOutputDelimited, see Scenario 5: Writing dynamic columns from a database to an output file.
Scenario 2: Utilizing Output Stream to save filtered data to a local file
Based on the preceding scenario, this scenario saves the filtered data to a local file
using output stream.

Dropping and linking components
- Drop tJava from the Palette to the design workspace.
-
Connect tJava to tFileInputDelimited using a Trigger > On Subjob OK
connection.
Configuring the components
-
Double-click tJava to open its Basic settings view.

-
In the Code area, type in the following
command:123new java.io.File("C:/myFolder").mkdirs();globalMap.put("out_file",newjava.io.FileOutputStream("C:/myFolder/customerselection.txt",false));Note:In this scenario, the command we use in the Code area of tJava will
create a new folder C:/myFolder where the output
file customerselection.txt will be saved. You can
customize the command in accordance with actual practice. -
Double-click tFileOutputDelimited to open
its Basic settings view.
-
Select Use Output Stream check box to
enable the Output Stream field in which you
can define the output stream using command.Fill in the Output Stream field with
following command:1(java.io.OutputStream)globalMap.get("out_file")Note:You can customize the command in the Output
Stream field by pressing CTRL+SPACE to
select built-in command from the list or type in the command into
the field manually in accordance with actual practice. In this
scenario, the command we use in the Output
Stream field will call the
java.io.OutputStreamclass to output the filtered
data stream to a local file which is defined in the Code area of tJava in this scenario. -
Click Sync columns to retrieve the schema
defined in the preceding component. - Leave rest of the components as they were in the previous scenario.
Saving and executing the Job
-
Press Ctrl+S to save
your Job. -
Press F6 or click
Run on the Run tab to execute the Job.The three specified columns Id, CustomerName and CustomerAddress
are output in the defined output file.
For an example of how to use dynamic schemas with
tFileOutputDelimited, see Scenario 5: Writing dynamic columns from a database to an output file.
tFileOutputDelimited MapReduce properties
These properties are used to configure tFileOutputDelimited running in the MapReduce Job framework.
The MapReduce
tFileOutputDelimited component belongs to the MapReduce family.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Click this icon to open a database connection wizard and store the database connection For more information about setting up and storing database connection parameters, see |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Folder |
Browse to, or enter the path pointing to the data to be used in the file system. This path must point to a folder rather than a file, because a Note that you need |
|
Action |
Select an operation for writing data:
Create: Creates a file and write
Overwrite: Overwrites the file |
|
Row separator |
The separator used to identify the end of a row. |
|
Field separator |
Enter character, string or regular expression to separate fields for the transferred |
|
Include Header |
Select this check box to include the column header to the |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. This field is compulsory for database |
|
Compress the data |
Select the Compress the data check box to compress the Hadoop provides different compression formats that help reduce the space needed for |
|
Merge result to single file |
Select this check box to merge the final part files into a single file and put that file in a Once selecting it, you need to enter the path to, or browse to the The following check boxes are used to manage the source and the target files:
This option is not available for a Sequence file. |
Advanced settings
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). This option is not available for a Sequence file. |
|
CSV options |
Select this check box to include CSV specific parameters such as Escape char and Text |
|
Enable parallel execution |
Select this check box to perform high-speed data processing, by treating multiple data flows
simultaneously. Note that this feature depends on the database or the application ability to handle multiple inserts in parallel as well as the number of CPU affected. In the Number of parallel executions field, either:
|
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
In a Once a Map/Reduce Job is opened in the workspace, tFileOutputDelimited as well as the Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tFileOutputDelimited properties for Apache Spark Batch
These properties are used to configure tFileOutputDelimited running in the Spark Batch Job framework.
The Spark Batch
tFileOutputDelimited component belongs to the File family.
The component in this framework is available only if you have subscribed to one
of the
Talend
solutions with Big Data.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. For |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Click this icon to open a database connection wizard and store the database connection For more information about setting up and storing database connection parameters, see |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Folder |
Browse to, or enter the path pointing to the data to be used in the file system. Note that this path must point to a folder rather than a file. The button for browsing does not work with the Spark Local mode; if you are using the Spark Yarn or the Spark Standalone mode, |
|
Action |
Select an operation for writing data:
Create: Creates a file and write data
Overwrite: Overwrites the file |
|
Row separator |
The separator used to identify the end of a row. |
|
Field separator |
Enter character, string or regular expression to separate fields for the transferred |
|
Include Header |
Select this check box to include the column header to the file. |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. This field is compulsory for database |
|
Compress the data |
Select the Compress the data check box to compress the Hadoop provides different compression formats that help reduce the space needed for |
|
Merge result to single file |
Select this check box to merge the final part files into a single file and put that file in a Once selecting it, you need to enter the path to, or browse to the The following check boxes are used to manage the source and the target files:
This option is not available for a Sequence file. |
Advanced settings
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). This option is not available for a Sequence file. |
|
CSV options |
Select this check box to include CSV specific parameters such as Escape char and Text |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. This component, along with the Spark Batch component Palette it belongs to, appears only Note that in this documentation, unless otherwise |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tFileOutputDelimited properties for Apache Spark Streaming
These properties are used to configure tFileOutputDelimited running in the Spark Streaming Job framework.
The Spark Streaming
tFileOutputDelimited component belongs to the File family.
The component in this framework is available only if you have subscribed to Talend Real-time Big Data Platform or Talend Data
Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. For |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
|
Click this icon to open a database connection wizard and store the database connection For more information about setting up and storing database connection parameters, see |
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
Folder |
Browse to, or enter the path pointing to the data to be used in the file system. Note that this path must point to a folder rather than a file. The button for browsing does not work with the Spark Local mode; if you are using the Spark Yarn or the Spark Standalone mode, |
|
Action |
Select an operation for writing data:
Create: Creates a file and write data
Overwrite: Overwrites the file |
|
Row separator |
The separator used to identify the end of a row. |
|
Field separator |
Enter character, string or regular expression to separate fields for the transferred |
|
Include Header |
Select this check box to include the column header to the file. |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. This field is compulsory for database |
|
Compress the data |
Select the Compress the data check box to compress the Hadoop provides different compression formats that help reduce the space needed for |
Advanced settings
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.). This option is not available for a Sequence file. |
|
CSV options |
Select this check box to include CSV specific parameters such as Escape char and Text |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.