tMatchIndex
Indexes a clean and deduplicated data set in ElasticSearch for continuous
matching purposes.
component, you must have performed all the matching and deduplicating tasks on this data set:
-
You generated a pairing model and computed pairs of suspect duplicates using
tMatchPairing. -
You labeled a sample of the suspect pairs manually or using Talend Data Stewardship to generate a
matching model with tMatchModel. -
You predicted labels on suspect pairs based on the pairing and matching
models using tMatchPredict. -
You cleaned and deduplicated the data set using
tRuleSurvivorship.
Then, you do not need to restart the matching process from scratch when you get new data
records having the same schema. You can index the clean data set in ElasticSearch using
tMatchIndex for continuous matching purposes.
For more information about
tMatchIndexPredict, see the tMatchIndex
documentation on Talend Help Center (https://help.talend.com).
This component can run only with Spark 2.0+ and ElasticSearch 5+.
tMatchIndex properties for Apache Spark Batch
These properties are used to configure tMatchIndex running in
the Spark Batch Job framework.
The Spark Batch
tMatchIndex component belongs to the Data Quality
family.
The component in this framework is available when you have subscribed to any Talend Platform product with Big Data or Talend Data
Fabric.
Basic settings
|
Define a storage configuration component |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. For |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields (columns) to Click Sync columns to retrieve the schema from Click Edit schema to make changes to the schema.
Read-only columns are added to the output schema:
|
|
|
Built-In: You create and store the |
|
|
Repository: You have already created |
|
ElasticSearch configuration |
Nodes: Enter the location
Index: Enter the name of the index to be created Select the Reset index check box to clean the |
|
Pairing |
Pairing model folder: Set the path to the folder If you want to store the model in a specific file system, for example S3 The button for browsing does not work with the Spark Local mode; if you are using the Spark Yarn or the Spark Standalone mode, |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. This component, along with the Spark Batch component Palette it belongs to, appears only |
|
Spark Batch Connection |
You need to use the Spark Configuration tab in
the Run view to define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Scenario: Indexing a reference data set in Elasticsearch
This scenario applies only to a subscription-based Talend Platform solution with Big data or Talend Data Fabric.
In this Job, the tMatchIndex component creates an index in
Elasticsearch and populates it with a clean and deduplicated data set which contains a
list of education centers in Chicago.
After performing all the matching actions on the data set which contains a list of
education centers in Chicago, you do not need to restart the matching process from
scratch when you get new data records having the same schema. You can index the clean
data set in Elasticsearch using tMatchIndex for continuous
matching purposes.
-
You generated a pairing model using tMatchPairing.
You can find examples of how to generate a pairing
model on Talend Help Center (https://help.talend.com). -
Make sure the input data you want to index is clean and deduplicated.
You can find an example of how to clean and
deduplicate a data set on Talend Help Center (https://help.talend.com). -
The Elasticsearch cluster must be running Elasticsearch 5+.
Setting up the Job
-
Drop the following components from the Palette onto the
design workspace: tFileInputDelimited and
tMatchIndex. - Connect the components using a Row > Main connection.
Configuring the input component
-
Double-click the tFileInputDelimited component to open
its Basic settings view and define its properties.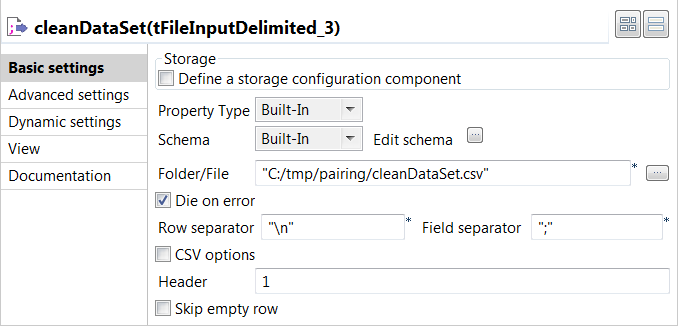
-
Click the […] button next to Edit
schema and use the [+] button in the
dialog box to add String type columns: Original_Id,
Source, Site_name and
Address. -
In the Folder/File field, set the path to the input
file. -
Set the row and field separators in the corresponding fields and the header and
footer, if any.
Indexing clean and deduplicated data in Elasticsearch
-
The Elasticsearch cluster and Elasticsearch-head are started before executing
the Job.For more information about Elasticsearch-head, which is a plugin for browsing
an Elasticsearch cluster, see https://mobz.github.io/elasticsearch-head/.
-
Double click the tMatchIndex component to open its
Basic settings view and define its properties.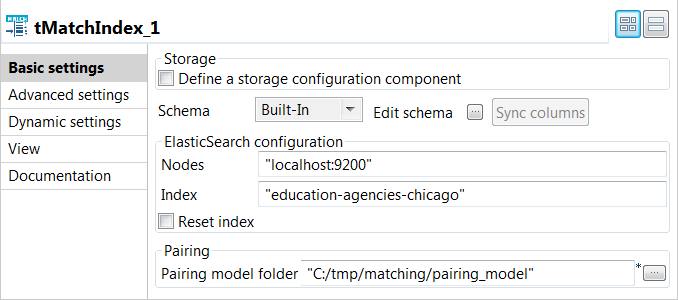
-
In the Elasticsearch configuration area, enter the
location of the cluster hosting the Elasticsearch system to be used in the
Nodes field, for example:"localhost:9200"
-
Enter the index to be created in Elasticsearch in the
Index field, for example:education-agencies-chicago
-
If you need to clean the Elasticsearch index specified in the
Index field, select the Reset
index check box. -
Enter the path to the local folder from where you want to retrieve the pairing
model files in the Pairing model folder. -
Press F6 to save and execute the
Job.
tMatchIndex created the
education-agencies-chicago index in Elasticsearch,
populated it with the clean data and computed the best suffixes based on the
blocking key values.
You can browse the index created by tMatchIndex using the
plugin Elasticsearch-head.


You can now use the indexed data as a reference data set for the
tMatchIndexPredict component.
You can find an example of how to do continuous matching
using tMatchIndexPredict on Talend Help Center (https://help.talend.com).