tSalesforceOutputBulk
Prepares the file to be processed by tSalesforceBulkExec for executions in
Salesforce.com.
The tSalesforceOutputBulk and tSalesforceBulkExec components are used together
in a two step process. In the first step, an output file is generated. In the second
step, this file is used to feed the Salesforce database. These two steps are fused
together in the tSalesforceOutputBulkExec component. The advantage of using two separate
steps is that the data can be transformed before it is loaded in the database.
tSalesforceOutputBulk generates files
in suitable format for bulk processing.
tSalesforceOutputBulk Standard properties
These properties are used to configure tSalesforceOutputBulk running in the Standard Job framework.
The Standard
tSalesforceOutputBulk component belongs to the Business and the Cloud families.
The component in this framework is generally available.
Basic settings
|
Schema and Edit |
A schema is a row description. It defines the number of fields (columns) to Click Edit schema to make changes to the schema.
Click Sync columns to retrieve the schema from This component offers the This dynamic schema |
|
Bulk File Path |
Specify the path to the file to be generated. |
|
Append |
Select this check box to append new data at the |
|
Ignore Null |
Select this check box to ignore NULL |
Advanced settings
| Relationship mapping for upsert |
Click the [+]
|
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at the Job level |
Global Variables
|
Global Variables |
NB_LINE: the number of rows read by an input component or
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
This component is more commonly used with the tSalesforceBulkExec component. Used together, they gain |
|
Limitation |
Due to license incompatibility, one or more JARs required to use this component are not |
Scenario: Inserting transformed bulk data into Salesforce
This scenario describes a six-component Job that transforms the data in the file SalesforceAccount.txt used in Scenario 2: Gathering erroneous data while inserting data into a Salesforce object, stores the transformed
data in a CSV file suitable for bulk processing, and then loads the transformed data into
Salesforce from the CSV file and displays the Job execution results on the console.

Setting up the Job
-
Create a new Job and add a tFileInputDelimited component, a tMap component, a tSalesforceOutputBulk component, a tSalesforceBulkExec component and two tLogRow components by typing their names on the design workspace
or dropping them from the Palette. -
Link the tFileInputDelimited component to the
tMap component using a Row > Main
connection. -
Link the tMap component to the tSalesforceOutputBulk component using a Row > *New Output*
(Main) connection. In the pop-up dialog box, enter the name of
the output connection. In this example, it is out. -
Link the tSalesforceBulkExec component to the
first tLogRow component using a Row > Main
connection. -
Link the tSalesforceBulkExec component to the
second tLogRow component using a Row > Reject
connection. -
Link the tFileInputDelimited component to the
tSalesforceBulkExec component using a
Trigger > OnSubjobOk connection.
Configuring the components
Preparing the bulk loading file
-
Double-click the tFileInputDelimited
component to open its Basic settings
view.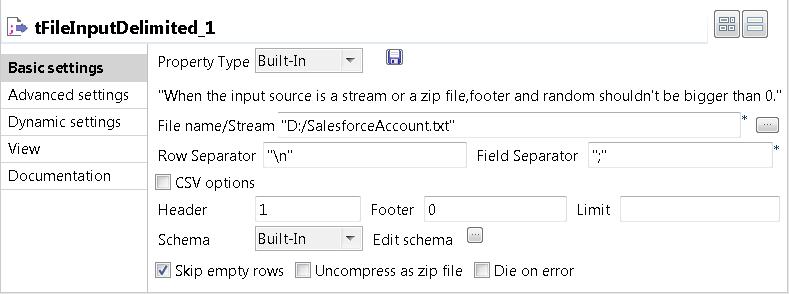
-
In the File name/Stream field, browse to or
enter the path to the input data file. In this example, it is
D:/SalesforceAccount.txt.In the Header field, type in 1 to skip the header row in the beginning of the
file. -
Click the […] button next to Edit schema and in the pop-up schema dialog box,
define the schema by adding four columns Name,
ParentId, Phone and
Fax of String type.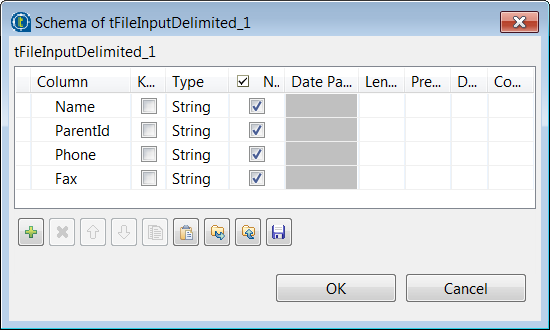 Click OK to save the changes and close the
Click OK to save the changes and close the
dialog box. -
Double-click the tMap component to open its
map editor and set the transformation.
-
Select all columns from the row1 input
table and drop them to the out output
table.Append.toUpperCase()in the Expression cell for the Name column in the
out output table.Click OK to validate the transformation and
close the map editor. -
Double-click the tSalesforceOutputBulk
component to open its Basic settings
view.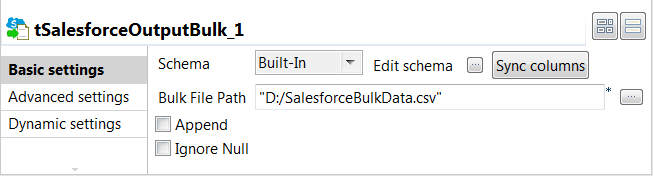
-
In the Bulk File Path field, browse to or
enter the path to the CSV file that will store the transformed data for bulk
processing.
Loading data into Salesforce from the file
-
Double-click the tSalesforceBulkExec
component to open its Basic settings
view.
-
In the User Id, Password and Security Key
fields, enter the user authentication information required to access
Salesforce. -
Click the […] button next to the Module Name field and in the pop-up dialog box,
select the object you want to access. In this example, it is Account. -
Click the […] button next to Edit schema and in the pop-up dialog box, remove all
columns except Name, ParentId,
Phone and Fax.Click OK to save the changes and accept the
propagation prompted by the pop-up dialog box. -
In the Bulk File Path field, browse to or
enter the path to the CSV file that stores the transformed data for bulk
processing. -
Double-click the first tLogRow component to
open its Basic settings view.
-
In the Mode area, select Table (print values in cells of a table) for better
readability of the results. -
Do the same to configure the second tLogRow
component.
Executing the Job
- Press Ctrl + S to save the Job.
-
Press F6 to execute the Job.
You can check the execution result on the Run
console. In the tLogRow_1 table, you can read the
In the tLogRow_1 table, you can read the
data inserted into Salesforce.In the tLogRow_2 table, you can read the
rejected data due to the incompatibility with the Account objects you have accessed.All the customer names are written in upper case.