tFileInputRegex
Reads a file row by row to split them up into fields using regular expressions and
sends the fields as defined in the schema to the next component.
Powerful feature which can replace number of other
components of the File family. Requires some advanced knowledge on regular expression
syntax.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tFileInputRegex Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tFileInputRegex MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tFileInputRegex properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tFileInputRegex properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tFileInputRegex Standard properties
These properties are used to configure tFileInputRegex running
in the Standard Job framework.
The Standard
tFileInputRegex component belongs to the File
family.
The component in this framework is available in all Talend
products.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
File name/Stream |
File name: Name Warning: Use absolute path (instead of relative path) for
this field to avoid possible errors.
Stream: Data flow For further information about how to define and use a |
|
Row separator |
The separator used to identify the end of a row. |
|
Regex |
Type in your Java regular expression including the
Note: Antislashes need to be Warning:
|
|
Header |
Enter the number of rows to be skipped in the beginning of file. |
|
Footer |
Number of rows to be skipped at the end of the file. |
|
Limit |
Maximum number of rows to be processed. If Limit = 0, no |
|
Ignore error message for the unmatched |
Select this check box to avoid outputing error messages |
|
Schema and Edit Schema |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Skip empty rows |
Select this check box to skip the empty rows. |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Encoding |
Select the encoding from the list or select Custom In the Map/Reduce version of tFileInputRegex, you need to select the Custom encoding check box to display |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing |
Global Variables
|
Global Variables |
NB_LINE: the number of rows processed. This is an After
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to read a file and separate fields |
Reading data using a Regex and outputting the result to Positional file
The following scenario creates a two-component Job, reading data from an Input
file using regular expression and outputting delimited data into a positional file.
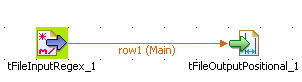
Dropping and linking the components
-
Drop a tFileInputRegex component from the
Palette to the design workspace. -
Drop a tFileOutputPositional component the
same way. -
Right-click on the tFileInputRegex component
and select Row
>
Main. Drag this main row link
onto the tFileOutputPositional component and
release when the plug symbol displays.
Configuring the components
-
Select the tFileInputRegex again so the
Component view shows up, and define the
properties: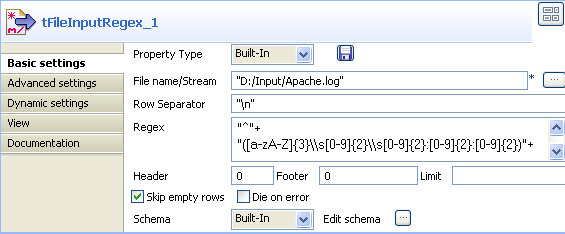
-
The Job is built-in for this scenario. Hence, the Properties are set for this
station only. -
Fill in a path to the file in File Name
field. This field is mandatory. -
Define the Row separator identifying the end
of a row. -
Then define the Regular expression in order
to delimit fields of a row, which are to be passed on to the next component. You
can type in a regular expression using Java code, and on mutiple lines if
needed.Warning:Regex syntax requires double quotes.
-
In this expression, make sure you include all subpatterns matching the fields
to be extracted. - In this scenario, ignore the header, footer and limit fields.
- Select a local (Built-in) Schema to define the data to pass on to the tFileOutputPositional component.
-
You can load or create the schema through the Edit
Schema function. -
Then define the second component properties:

- Enter the Positional file output path.
-
Enter the Encoding standard, the output file
is encoded in. Note that, for the time being, the encoding consistency
verification is not supported. -
Select the Schema type. Click on Sync columns to automatically synchronize the schema
with the Input file schema.
Saving and executing the Job
- Press Ctrl+S to save your Job.
-
Now go to the Run tab, and click on Run to execute the Job.
The file is read row by row and split up into fields based on the Regular Expression definition. You can open it using
any standard file editor.
tFileInputRegex MapReduce properties (deprecated)
These properties are used to configure tFileInputRegex running in the MapReduce Job framework.
The MapReduce
tFileInputRegex component belongs to the File family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will read all of the files stored in that folder, for example,/user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property mapreduce.input.fileinputformat.input.dir.recursive to be If you want to specify more If the file to be read is a compressed one, enter the file
Note that you need |
|
Row separator |
The separator used to identify the end of a row. |
|
Regex |
This field can contain multiple lines. Type in your
Note: Antislashes Warning:
Regex syntax requires double quotes. |
|
Header |
Enter the number of rows to be skipped in the beginning of file. |
|
Footer |
Number of rows to be skipped at the end of the |
|
Limit |
Maximum number of rows to be processed. If Limit = 0, |
|
Schema and Edit |
Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Skip empty rows |
Select this check box to skip the empty rows. |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Encoding |
Select the encoding from the list or select Custom In the Map/Reduce version of tFileInputRegex, you need to select the Custom encoding check box to display this list. |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Use this component to read a In a You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. For further information about a Note that in this documentation, unless otherwise |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tFileInputRegex properties for Apache Spark Batch
These properties are used to configure tFileInputRegex running in the Spark Batch Job framework.
The Spark Batch
tFileInputRegex component belongs to the File family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more If the file to be read is a compressed one, enter the file
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Row separator |
The separator used to identify the end of a row. |
|
Regex |
This field can contain multiple lines. Type in your
Note: Antislashes Warning:
Regex syntax requires double quotes. |
|
Header |
Enter the number of rows to be skipped in the beginning of file. |
|
Schema and Edit |
Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Skip empty rows |
Select this check box to skip the empty rows. |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. |
Usage
|
Usage rule |
This component is used as a start component and requires an output This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tFileInputRegex properties for Apache Spark Streaming
These properties are used to configure tFileInputRegex running in the Spark Streaming Job framework.
The Spark Streaming
tFileInputRegex component belongs to the File family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more If the file to be read is a compressed one, enter the file
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Row separator |
The separator used to identify the end of a row. |
|
Regex |
This field can contain multiple lines. Type in your
Note: Antislashes Warning:
Regex syntax requires double quotes. |
|
Header |
Enter the number of rows to be skipped in the beginning of file. |
|
Schema and Edit |
Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Skip empty rows |
Select this check box to skip the empty rows. |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom and define it manually. |
Usage
|
Usage rule |
This component is used as a start component and requires an output link. This component is only used to provide the lookup flow (the right side of a join This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.