tFileInputXML
fields as defined in the schema to the next component.
Depending on the Talend
product you are using, this component can be used in one, some or all of the following
Job frameworks:
-
Standard: see tFileInputXML Standard properties.
The component in this framework is available in all Talend
products. -
MapReduce: see tFileInputXML MapReduce properties (deprecated).
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Batch: see tFileInputXML properties for Apache Spark Batch.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric. -
Spark Streaming: see tFileInputXML properties for Apache Spark Streaming.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
tFileInputXML Standard properties
These properties are used to configure tFileInputXML running in the Standard Job framework.
The Standard
tFileInputXML component belongs to the File and the XML families.
The component in this framework is available in all Talend
products.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the |
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
File name/Stream |
File name: Name and path of the Warning: Use absolute path (instead of relative path) for
this field to avoid possible errors.
Stream: The data flow to be This variable could be already pre-defined in your Studio or In order to avoid the inconvenience of hand writing, you could Related topic to the available variables: see |
|
Loop XPath query |
Node of the tree, which the loop is based on. |
|
Mapping |
Column: Columns to map. They
XPath Query: Enter the fields to
Get nodes: Select this check box For further information about the Document type, see Note:
The Get Nodes option |
|
Limit |
Maximum number of rows to be processed. If Limit = 0, no row is |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
| Ignore DTD file |
Select this check box to ignore the DTD file indicated in the XML |
|
Advanced separator (for number) |
Select this check box to change the separator used for numbers. By default, the thousands separator is a comma (,) and the decimal separator is a period (.).
Thousands separator: define the
Decimal separator: define the |
|
Ignore the namespaces |
Select this check box to ignore name spaces.
Generate a temporary file: click |
|
Use Separator for mode Xerces |
Select this check box if you want to separate concatenated Note:
This field can only be used if the selected Generation mode is Xerces. The following field displays:
Field separator: Define the |
|
Encoding |
Select the encoding from the list or select Custom |
|
Generation mode |
From the drop-down list select the generation mode for the XML
|
|
Validate date |
Select this check box to check the date format strictly against |
|
tStatCatcher Statistics |
Select this check box to gather the Job processing metadata at a |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the
NB_LINE: the number of rows processed. This is an After A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
tFileInputXML is for use as an |
Reading and extracting data from an XML structure
This scenario describes a basic Job that reads a defined XML directory and extracts
specific information and outputs it on the Run console
via a tLogRow component.
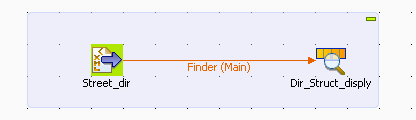
Procedure
-
Drop tFileInputXML and tLogRow from the Palette to the
design workspace. -
Connect both components together using a Main Row
link. -
Double-click tFileInputXML to open its
Basic settings view and define the
component properties.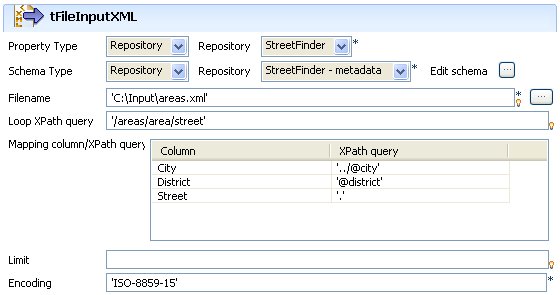
-
As the street dir file used as input file has been previously defined in the
Metadata area, select Repository as Property type. This way, the properties are
automatically leveraged and the rest of the properties fields are filled in
(apart from Schema). For more information regarding the metadata
creation wizards, see
Talend Studio
User
Guide.
-
Select the same way the relevant schema in the Repository metadata list.
Edit schema if you want to make any change
to the schema loaded. -
The Filename shows the structured file to be
used as input -
In Loop XPath query, change if needed the
node of the structure where the loop is based. -
On the Mapping table, fill the fields to be
extracted and displayed in the output. - If the file size is consequent, fill in a Limit of rows to be read.
- Enter the encoding if needed then double-click on tLogRow to define the separator character.
-
Save your Job and press F6 to execute
it.

The fields defined in the input properties are extracted from the XML structure and
displayed on the console.
Extracting erroneous XML data via a reject flow
This Java scenario describes a three-component Job that reads an XML file and:
-
first, returns correct XML data in an output XML file,
-
and second, displays on the console erroneous XML data which type does not
correspond to the defined one in the schema.
Procedure
-
Drop the following components from the Palette to the design workspace: tFileInputXML, tFileOutputXML
and tLogRow.Right-click tFileInputXML and select
Row > Main in the contextual menu and then click tFileOutputXML to connect the components together.Right-click tFileInputXML and select
Row > Reject in the contextual menu and then click tLogRow to connect the components together using a
reject link.
-
Double-click tFileInputXML to display the
Basic settings view and define the
component properties.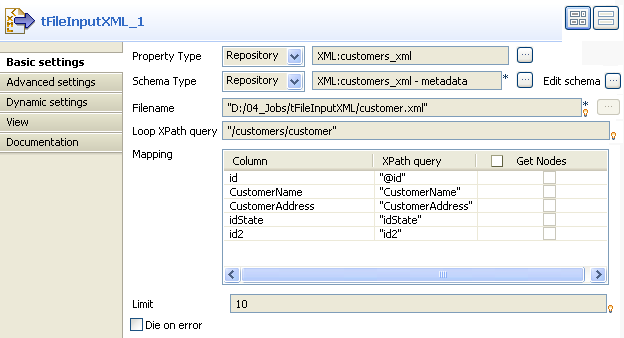
-
In the Property Type list, select Repository and click the three-dot button next to the
field to display the Repository Content
dialog box where you can select the metadata relative to the input
file if you have already stored it in the File xml node under the Metadata folder of the Repository tree view. The fields that follow are automatically
filled with the fetched data. If not, select Built-in and fill in the fields that follow manually.For more information about storing schema metadat in the Repository tree
view, see
Talend Studio User Guide. -
In the Schema Type list, select Repository and click the three-dot button to open the
dialog box where you can select the schema that describe the structure of the
input file if you have already stored it in the Repository tree view. If not, select Built-in and click the three-dot button next to Edit schema to open a dialog box where you can define
the schema manually.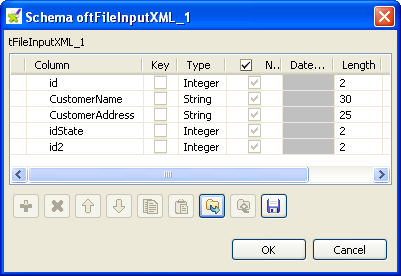 The schema in this example consists of five columns: id,
The schema in this example consists of five columns: id,
CustomerName, CustomerAddress, idState and
id2. -
Click the three-dot button next to the Filename field and browse to the XML file you want to
process. -
In the Loop XPath query, enter between
inverted commas the path of the XML node on which to loop in order to retrieve
data.In the Mapping table, Column is automatically populated with the defined
schema.In the XPath query column, enter between
inverted commas the node of the XML file that holds the data you want to extract
from the corresponding column. -
In the Limit field, enter the number of lines
to be processed, the first 10 lines in this example. -
Double-click tFileOutputXML to display its
Basic settings view and define the
component properties.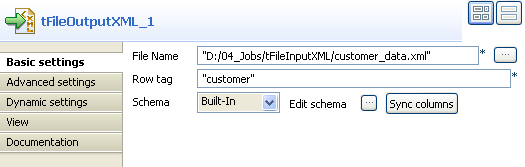
-
Click the three-dot button next to the File
Name field and browse to the output XML file you want to collect
data in, customer_data.xml in this example.In the Row tag field, enter between inverted
commas the name you want to give to the tag that will hold the recuperated
data.Click Edit schema to display the schema
dialog box and make sure that the schema matches that of the preceding
component. If not, click Sync columns to
retrieve the schema from the preceding component. -
Double-click tLogRow to display its Basic settings view and define the component
properties.Click Edit schema to open the schema dialog
box and make sure that the schema matches that of the preceding component. If
not, click Sync columns to retrieve the schema
of the preceding component.In the Mode area, select the Vertical option. -
Save your Job and press F6 to execute
it.
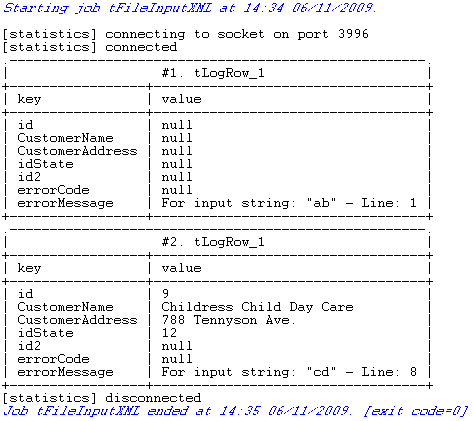
The output file customer_data.xml holding the correct XML data is
created in the defined path and erroneous XML data is displayed on the console of the
Run view.
tFileInputXML MapReduce properties (deprecated)
These properties are used to configure tFileInputXML running in the MapReduce Job framework.
The MapReduce
tFileInputXML component belongs to the MapReduce family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
The MapReduce framework is deprecated from Talend 7.3 onwards. Use Talend Jobs for Apache Spark to accomplish your integration tasks.
Basic settings
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will read all of the files stored in that folder, for example,/user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property mapreduce.input.fileinputformat.input.dir.recursive to be If you want to specify more than one files or directories in this If the file to be read is a compressed one, enter the file name
Note that you need |
|
Element to extract |
Enter the element from which you need to read the contents and the The element defined in this field is used at the root node of any Note that any content outside this element is ignored and the |
|
Loop XPath query |
Node of the tree, which the loop is based on. Note its root is the element you have defined in the Element to extract field. |
|
Mapping |
Column: Columns to map. They
XPath Query: Enter the fields to
Get nodes: Select this check box For further information about the Document type, see |
|
Die on error |
Select the check box to stop the execution of the Job when an error Clear the check box to skip any rows on error and complete the process for |
Advanced settings
|
Ignore the namespaces |
Select this check box to ignore name spaces. |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom |
Global Variables
|
Global Variables |
ERROR_MESSAGE: the error message generated by the A Flow variable functions during the execution of a component while an After variable To fill up a field or expression with a variable, press Ctrl + For further information about variables, see |
Usage
|
Usage rule |
Because of the characteristics of the MapReduce framework, the In a Once a Map/Reduce Job is opened in the workspace, tFileInputXML as well as the MapReduce Note that in this documentation, unless otherwise |
|
Hadoop Connection |
You need to use the Hadoop Configuration tab in the This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Map/Reduce version of this component yet.
tFileInputXML properties for Apache Spark Batch
These properties are used to configure tFileInputXML running in the Spark Batch Job framework.
The Spark Batch
tFileInputXML component belongs to the File family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more than one files or directories in this If the file to be read is a compressed one, enter the file name
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Element to extract |
Enter the element from which you need to read the contents and the The element defined in this field is used at the root node of any Note that any content outside this element is ignored and the |
|
Loop XPath query |
Node of the tree, which the loop is based on. Note its root is the element you have defined in the Element to extract field. |
|
Mapping |
Column: Columns to map. They
XPath Query: Enter the fields to
Get nodes: Select this check box For further information about the Document type, see |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom |
Usage
|
Usage rule |
This component is used as a start component and requires an output This component, along with the Spark Batch component Palette it belongs to, Note that in this documentation, unless otherwise explicitly stated, a |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Batch version of this component
yet.
tFileInputXML properties for Apache Spark Streaming
These properties are used to configure tFileInputXML running in the Spark Streaming Job framework.
The Spark Streaming
tFileInputXML component belongs to the File family.
This component is available in Talend Real Time Big Data Platform and Talend Data Fabric.
Basic settings
|
Define a storage configuration |
Select the configuration component to be used to provide the configuration If you leave this check box clear, the target file system is the local The configuration component to be used must be present in the same Job. |
|
Property type |
Either Built-In or Repository. |
|
|
Built-In: No property data stored centrally. |
|
|
Repository: Select the repository file where the The properties are stored centrally under the Hadoop The fields that come after are pre-filled in using the fetched For further information about the Hadoop |
|
Schema and Edit |
A schema is a row description. It defines the number of fields Click Edit
|
|
|
Built-In: You create and store the schema locally for this component |
|
|
Repository: You have already created the schema and stored it in the |
|
Folder/File |
Browse to, or enter the path pointing to the data to be used in the file system. If the path you set points to a folder, this component will
read all of the files stored in that folder, for example, /user/talend/in; if sub-folders exist, the sub-folders are automatically ignored unless you define the property spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive to be true in the Advanced properties table in theSpark configuration tab.
If you want to specify more than one files or directories in this If the file to be read is a compressed one, enter the file name
The button for browsing does not work with the Spark tHDFSConfiguration |
|
Element to extract |
Enter the element from which you need to read the contents and the The element defined in this field is used at the root node of any Note that any content outside this element is ignored and the |
|
Loop XPath query |
Node of the tree, which the loop is based on. Note its root is the element you have defined in the Element to extract field. |
|
Mapping |
Column: Columns to map. They
XPath Query: Enter the fields to
Get nodes: Select this check box For further information about the Document type, see |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Advanced settings
|
Set minimum partitions |
Select this check box to control the number of partitions to be created from the input In the displayed field, enter, without quotation marks, the minimum number of partitions When you want to control the partition number, you can generally set at least as many partitions as |
|
Custom encoding |
You may encounter encoding issues when you process the stored data. In that Select the encoding from the list or select Custom |
Usage
|
Usage rule |
This component is used as a start component and requires an output link. This component is only used to provide the lookup flow (the right side of a join This component, along with the Spark Streaming component Palette it belongs to, appears Note that in this documentation, unless otherwise explicitly stated, a scenario presents |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Related scenarios
No scenario is available for the Spark Streaming version of this component
yet.