tKuduOutput
tKuduOutput properties for Apache Spark Batch
These properties are used to configure tKuduOutput running in the Spark Batch Job framework.
The Spark Batch
tKuduOutput component belongs to the Databases family.
The component in this framework is available in all subscription-based Talend products with Big Data
and Talend Data Fabric.
Basic settings
|
Use an existing configuration |
Select this check box and in the Component List click the relevant connection component to |
|
Server connection |
Click the [+] button to add as many rows as the Kudu masters you need to use, each row for a master. Then enter the locations and the listening ports of the master nodes of the Kudu service to be used. This component supports only the Apache Kudu service installed on Cloudera. For compatibility information between Apache Kudu and Cloudera, see the related Cloudera |
|
Schema and Edit |
A schema is a row description. It defines the number of fields
|
|
Click Edit
|
|
|
Kudu table |
Enter the name of the table to be created, changed or removed. |
|
Action on table |
Select an operation to be performed on the table defined.
|
|
Action on data |
Select an action to be performed on data of the table defined.
|
|
Replicas |
Enter, without double quotation marks, the replication factor of this table For further information about Kudu tablets and Kudu replication policies, |
|
Hash partitions |
When you are creating a Kudu table, it is recommended to define how this
At runtime, rows are distributed by hash value in one of those buckets. If you leave this For further information about hash partitioning in Kudu, see Hash partitioning. |
|
Range partitions |
When you are creating a Kudu table, it is recommended to define how this
At runtime, rows of these columns are distributed using the values of the For further information about hash partitioning in Kudu, see Range partitioning. |
|
Die on error |
Select the check box to stop the execution of the Job when an error |
Usage
|
Usage rule |
This component is used as an end component and requires an input link. |
|
Spark Connection |
In the Spark
Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:
This connection is effective on a per-Job basis. |
Writing and reading data from Cloudera Kudu using a Spark Batch Job
In this scenario, you create a Spark Batch Job using the Kudu components to partition and write data in a Kudu table and then read some of the data from Kudu.
This scenario applies only to subscription-based Talend products with Big
Data.

follows:
|
1 2 3 4 5 |
01;ychen;30 02;john;40 03;yoko;20 04;tom;60 05;martin;50 |
This data contains the names of some persons, the ID numbers distributed to
these persons and their ages.
The ages are made distinct one from another on purpose because this column is the primary key column and is used for range partitioning in this scenario.
Note that the sample data is created for demonstration purposes only.
-
Ensure that the Spark cluster and the
Cloudera Kudu database to be used have been properly installed and are running.
-
Ensure that the client machine on which the Talend Jobs are
executed can recognize the host names of the nodes of the Hadoop cluster to be
used. For this purpose, add the IP address/hostname mapping entries for the
services of that Hadoop cluster in the hosts
file of the client machine.For example, if the host name of the Hadoop Namenode server is talend-cdh550.weave.local and its IP address is 192.168.x.x, the mapping entry reads 192.168.x.x
talend-cdh550.weave.local. -
If the cluster to be used is secured with Kerberos, ensure
that you have properly installed and configured Kerberos on the machine on
which your Talend Job is
executed. Depending on the Kerberos mode being used, the Kerberos kinit
ticket or keytab must be available on that machine.For further information, search for
how to use Kerberos in the Studio with Big Data on Talend Help Center (https://help.talend.com).
-
Define the Hadoop connection metadata from the Hadoop cluster node in Repository. This way, you can not only reuse
this connection in different Jobs but also ensure that the connection to
your Hadoop cluster has been properly set up and is working well when you
use this connection in your Jobs.For further information about
setting up a reusable Hadoop connection, search for centralizing a Hadoop
connection on Talend Help Center
(https://help.talend.com).
Design the data flow of the Kudu Job
-
In the
Integration
perspective of the Studio, create an empty
Spark Batch Job from the Job Designs node in
the Repository tree view.For further information about how to create a Spark Batch Job, see Talend Open Studio for Big Data Getting Started Guide. -
In the workspace, enter the name of the component to be used and select this
component from the list that appears. In this scenario, the components are
tHDFSConfiguration, tKuduConfiguration, tFixedFlowInput, tKuduOutput,
tKuduInput and tLogRow.The tFixedFlowInput component is used to load the
sample data into the data flow. In the real-world practice, you can use other
components such as tFileInputDelimited, alone or even
with a tMap, in the place of
tFixedFlowInput to design a sophisticated process to
prepare your data to be processed. - Connect tFixedFlowInput to tKuduOutput using the Row > Main link.
- Connect tMongoDBInput to tLogRow using the Row > Main link.
- Connect tFixedFlowInput to tMongoDBInput using the Trigger > OnSubjobOk link.
-
Leave tHDFSConfiguration and tKuduConfiguration alone without any
connection.
Defining the Cloudera connection parameters
Complete the Cloudera connection configuration in the Spark
configuration tab of the Run view of your Job.
This configuration is effective on a per-Job basis.
If you cannot
find the Cloudera version to be used from this drop-down list, you can add your distribution
via some dynamic distribution settings in the Studio.
-
Select the type of the Spark cluster you need to connect to.
Standalone
The Studio connects to a Spark-enabled cluster to run the Job from this
cluster.If you are using the Standalone mode, you need to
set the following parameters:-
In the Spark host field, enter the URI
of the Spark Master of the Hadoop cluster to be used. -
In the Spark home field, enter the
location of the Spark executable installed in the Hadoop cluster to be used. -
If the Spark cluster cannot recognize the machine in which the Job is
launched, select this Define the driver hostname or IP
address check box and enter the host name or the IP address of
this machine. This allows the Spark master and its workers to recognize this
machine to find the Job and thus its driver.Note that in this situation, you also need to add the name and the IP
address of this machine to its host file.
Yarn client
The Studio runs the Spark driver to orchestrate how the Job should be
performed and then send the orchestration to the Yarn service of a given
Hadoop cluster so that the Resource Manager of this Yarn service
requests execution resources accordingly.If you are using the Yarn client
mode, you need to set the following parameters in their corresponding
fields (if you leave the check box of a service clear, then at runtime,
the configuration about this parameter in the Hadoop cluster to be used
will be ignored):-
In the Resource managerUse datanode
field, enter the address of the ResourceManager service of the Hadoop cluster to
be used. -
Select the Set resourcemanager
scheduler address check box and enter the Scheduler address in
the field that appears. -
Select the Set jobhistory
address check box and enter the location of the JobHistory
server of the Hadoop cluster to be used. This allows the metrics information of
the current Job to be stored in that JobHistory server. -
Select the Set staging
directory check box and enter this directory defined in your
Hadoop cluster for temporary files created by running programs. Typically, this
directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files
such as yarn-site.xml or mapred-site.xml of your distribution. -
If you are accessing the Hadoop cluster running with Kerberos security,
select this check box, then, enter the Kerberos principal names for the
ResourceManager service and the JobHistory service in the displayed fields. This
enables you to use your user name to authenticate against the credentials stored in
Kerberos. These principals can be found in the configuration files of your
distribution, such as in yarn-site.xml and in mapred-site.xml.If you need to use a Kerberos keytab file to log in, select Use a keytab to authenticate. A keytab file contains
pairs of Kerberos principals and encrypted keys. You need to enter the principal to
be used in the Principal field and the access
path to the keytab file itself in the Keytab
field. This keytab file must be stored in the machine in which your Job actually
runs, for example, on a Talend
Jobserver.Note that the user that executes a keytab-enabled Job is not necessarily
the one a principal designates but must have the right to read the keytab file being
used. For example, the user name you are using to execute a Job is user1 and the principal to be used is guest; in this
situation, ensure that user1 has the right to read the keytab
file to be used. -
The User name field is available when you are not using
Kerberos to authenticate. In the User name field, enter the
login user name for your distribution. If you leave it empty, the user name of the machine
hosting the Studio will be used. -
If the Spark cluster cannot recognize the machine in which the Job is
launched, select this Define the driver hostname or IP
address check box and enter the host name or the IP address of
this machine. This allows the Spark master and its workers to recognize this
machine to find the Job and thus its driver.Note that in this situation, you also need to add the name and the IP
address of this machine to its host file.
Yarn cluster
The Spark driver runs in your Yarn cluster to orchestrate how the Job
should be performed.If you are using the Yarn cluster mode, you need
to define the following parameters in their corresponding fields (if you
leave the check box of a service clear, then at runtime, the
configuration about this parameter in the Hadoop cluster to be used will
be ignored):-
In the Resource managerUse datanode
field, enter the address of the ResourceManager service of the Hadoop cluster to
be used. -
Select the Set resourcemanager
scheduler address check box and enter the Scheduler address in
the field that appears. -
Select the Set jobhistory
address check box and enter the location of the JobHistory
server of the Hadoop cluster to be used. This allows the metrics information of
the current Job to be stored in that JobHistory server. -
Select the Set staging
directory check box and enter this directory defined in your
Hadoop cluster for temporary files created by running programs. Typically, this
directory can be found under the yarn.app.mapreduce.am.staging-dir property in the configuration files
such as yarn-site.xml or mapred-site.xml of your distribution. -
Set path to custom Hadoop
configuration JAR: if you are using
connections defined in Repository to
connect to your Cloudera or Hortonworks cluster, you can
select this check box in the
Repository wizard and in the
field that is displayed, specify the path to the JAR file
that provides the connection parameters of your Hadoop
environment. Note that this file must be accessible from the
machine where you Job is launched.This kind of Hadoop configuration JAR file is
automatically generated when you build a Big Data Job from the
Studio. This JAR file is by default named with this
pattern:You1hadoop-conf-[name_of_the_metadata_in_the_repository]_[name_of_the_context].jar
can also download this JAR file from the web console of your
cluster or simply create a JAR file yourself by putting the
configuration files in the root of your JAR file. For
example:12hdfs-sidt.xmlcore-site.xmlThe parameters from your custom JAR file override the parameters
you put in the Spark configuration field.
They also override the configuration you set in the
configuration components such as
tHDFSConfiguration or
tHBaseConfiguration when the related
storage system such as HDFS, HBase or Hive are native to Hadoop.
But they do not override the configuration set in the
configuration components for the third-party storage system such
as tAzureFSConfiguration. -
If you are accessing the Hadoop cluster running with Kerberos security,
select this check box, then, enter the Kerberos principal names for the
ResourceManager service and the JobHistory service in the displayed fields. This
enables you to use your user name to authenticate against the credentials stored in
Kerberos. These principals can be found in the configuration files of your
distribution, such as in yarn-site.xml and in mapred-site.xml.If you need to use a Kerberos keytab file to log in, select Use a keytab to authenticate. A keytab file contains
pairs of Kerberos principals and encrypted keys. You need to enter the principal to
be used in the Principal field and the access
path to the keytab file itself in the Keytab
field. This keytab file must be stored in the machine in which your Job actually
runs, for example, on a Talend
Jobserver.Note that the user that executes a keytab-enabled Job is not necessarily
the one a principal designates but must have the right to read the keytab file being
used. For example, the user name you are using to execute a Job is user1 and the principal to be used is guest; in this
situation, ensure that user1 has the right to read the keytab
file to be used. -
The User name field is available when you are not using
Kerberos to authenticate. In the User name field, enter the
login user name for your distribution. If you leave it empty, the user name of the machine
hosting the Studio will be used. -
Select the Wait for the Job to complete check box to make your Studio or,
if you use Talend
Jobserver, your Job JVM keep monitoring the Job until the execution of the Job
is over. By selecting this check box, you actually set the spark.yarn.submit.waitAppCompletion property to be true. While
it is generally useful to select this check box when running a Spark Batch Job,
it makes more sense to keep this check box clear when running a Spark Streaming
Job.
Ensure that the user name in the Yarn
client mode is the same one you put in
tHDFSConfiguration, the component used to provide HDFS
connection information to Spark. -
-
With the Yarn client mode, the
Property type list is displayed to allow you
to select an established Hadoop connection from the Repository, on the condition that you have created this connection
in the Repository. Then the Studio will reuse
that set of connection information for this Job.
-
If you need to launch from Windows, it is recommended to specify where
the winutils.exe program to be used is stored.
-
If you know where to find your winutils.exe file and you want to use it, select the Define the Hadoop home directory check box
and enter the directory where your winutils.exe is
stored. -
Otherwise, leave this check box clear, the Studio generates one
by itself and automatically uses it for this Job.
-
-
In the Spark “scratch” directory
field, enter the directory in which the Studio stores in the local system the
temporary files such as the jar files to be transferred. If you launch the Job
on Windows, the default disk is C:. So if you leave /tmp in this field, this directory is C:/tmp.
-
After the connection is configured, you can tune
the Spark performance, although not required, by following the process explained in:-
for Spark Batch Jobs.
-
for Spark Streaming Jobs.
-
-
It is recommended to activate the Spark logging and
checkpointing system in the Spark configuration tab of the Run view of your Spark
Job, in order to help debug and resume your Spark Job when issues arise:-
.
-
-
If you are using Cloudera V5.5+ to run your MapReduce or Apache Spark Batch
Jobs, you can make use of Cloudera Navigator to trace the lineage of given
data flow to discover how this data flow was generated by a Job.
Configuring the connection to the file system to be used by Spark
Skip this section if you are using Google Dataproc or HDInsight, as for these two
distributions, this connection is configured in the Spark
configuration tab.
-
Double-click tHDFSConfiguration to open its Component view.
Spark uses this component to connect to the HDFS system to which the jar
files dependent on the Job are transferred. -
If you have defined the HDFS connection metadata under the Hadoop
cluster node in Repository, select
Repository from the Property
type drop-down list and then click the
[…] button to select the HDFS connection you have
defined from the Repository content wizard.For further information about setting up a reusable
HDFS connection, search for centralizing HDFS metadata on Talend Help Center
(https://help.talend.com).If you complete this step, you can skip the following steps about configuring
tHDFSConfiguration because all the required fields
should have been filled automatically. -
In the Version area, select
the Hadoop distribution you need to connect to and its version. -
In the NameNode URI field,
enter the location of the machine hosting the NameNode service of the cluster.
If you are using WebHDFS, the location should be
webhdfs://masternode:portnumber; WebHDFS with SSL is not
supported yet. -
In the Username field, enter
the authentication information used to connect to the HDFS system to be used.
Note that the user name must be the same as you have put in the Spark configuration tab.
Configuring the connection to the Kudu database to be used by Spark
-
Double-click tKuduConfiguration to open its
Component view.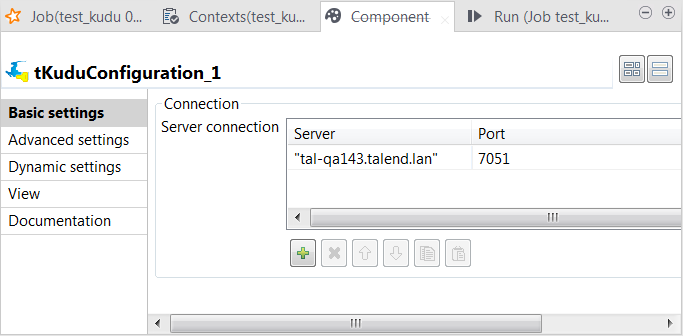
- Click the [+] button to add one row to the Server connection table.
-
Enter the node name of your Kudu master within double quotation marks and its
listening port.If your Kudu cluster has multiple masters, add them all to this table, each in
one row.
Partition the sample data and writing it to Kudu
-
Double-click the tFixedFlowIput component to
open its Component view.
- Click the […] button next to Edit schema to open the schema editor.
-
Click the [+] button to add the schema
columns as shown in this image.
-
In the Type column, select
Integer for the age column. -
In the Key column, select the check box for the
age column to define this column as key primary key
column. -
Click OK to validate these changes and accept
the propagation prompted by the pop-up dialog box. -
In the Mode area, select the Use Inline
Content radio button and paste the previously mentioned sample data
into the Content field that is displayed. -
In the Field separator field, enter a
semicolon (;). -
Double-click the tKuduOutput component to
open its Component view.
-
Select the Use an existing configuration check box and
then select the Kudu configuration you configured in the previous steps from the
Component list drop-down list. -
Click Sync columns to ensure that
tKuduOutput has the same schema as
tFixedFlowInput. -
In the Table field, enter the name of the table you want
to create in Kudu. -
From the Action on table drop-down list, select
Drop table if exists and create. -
In Range partitions, add one row by clicking the
[+] button and do the following:-
In Partition No, enter, without double quotation
marks, the number to be used as the ID of the partition to be created.
For example, enter 1 to create Partition 1. -
In Partition column, select the primary key
column to be used for partitioning. In this scenario, select
age. -
In Lower boundary, enter
20 without double quotation marks because the
type of the age data is integer. -
In Upper boundary, do the same to set it to
60.
This partitioning definition creates the partition schema reading as
follows:According123RANGE (age) (PARTITION 20 <= VALUES < 60)
to this partition schema, the record falling on the lower boundary, the age
20, is included in this partition and thus is written in
Kudu but the record falling on the upper boundary, the age
60, is excluded and is not written in Kudu.In the
real-world practice, if you need to write all the data in the Kudu table, define
more partitions to receive the data with proper boundaries. -
In Partition No, enter, without double quotation
-
From the Action on data drop-down list, select
Insert.
Scanning data from Kudu
-
Double-click tKuduInput to open its
Component view.
-
Click the […] button next to Edit
schema to open the schema editor. -
Click the [+] button to add the schema columns for
output as shown in this image.
-
In the Type field, select Integer
as data type for the age column. -
In the Key column, select the check box for the
age column because this is the primary key
column. -
Click OK to validate these changes and accept the
propagation prompted by the pop-up dialog box. -
In the Table name field, enter the name of the table
from which you need to read data. In this scenario, it is
ychen_kudu. -
In the Query mode area, select the Use
scan radio button to read all the data from the Kudu
table. -
Double click tLogRow to open its
Component view and select the Table radio button to present the result in a
table. - Press F6 to run this Job.
Once done, in the console of the Run view, you
can check the data read from the Kudu table.

The record 04;tom;60 is not written in the table because it is out
of the partition boundaries.
In the real-world practice, upon the
success of the execution, you could deploy and launch your Job on a Talend JobServer if you have one.
For related
information, search for running a Job remotely on Talend Help Center (https://help.talend.com).